") About 6.5 years ago I wrote this blog post around the future of Software-Defined Storage and if the VSA (virtual storage appliance) is the future for it. Last week at VMworld a customer reminded me of this article. Not because they read the article and pointed me back at it, but because they implemented what I described in this post, almost to the letter.
About 6.5 years ago I wrote this blog post around the future of Software-Defined Storage and if the VSA (virtual storage appliance) is the future for it. Last week at VMworld a customer reminded me of this article. Not because they read the article and pointed me back at it, but because they implemented what I described in this post, almost to the letter.
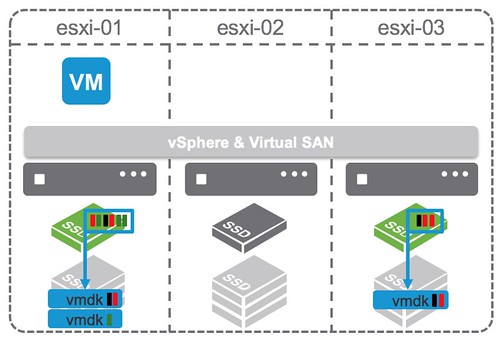
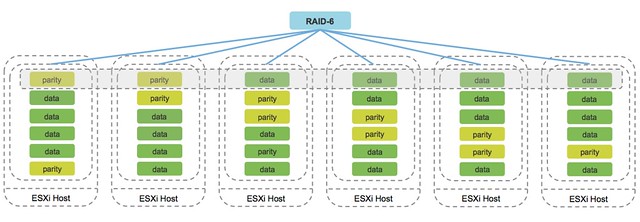
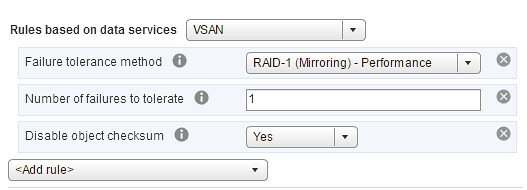
This customer had an interesting implementation, which kind of resembles the diagram I added to the blog post, note I added a part to the diagram which I originally left out but had mentioned in the blog (yes that is why the diagram looks like it is ancient… it is):

I want to share with you what the customer is doing because there are still plenty of customers that do not realize that this is supported. Note that this is supported by both vSAN as well as VMware Cloud Foundation, providing you a future proof, scalable, and flexible full-stack HCI architecture which does not need to be implemented in a rip and replace approach!
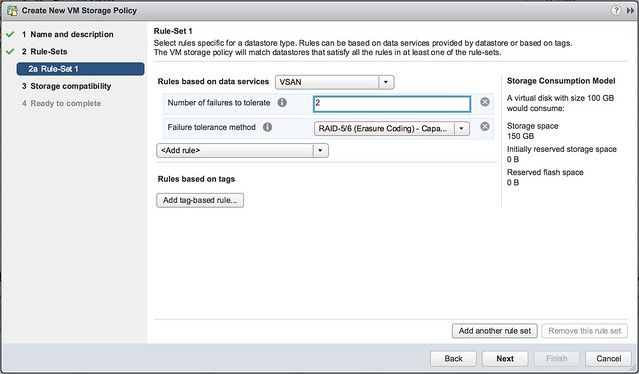
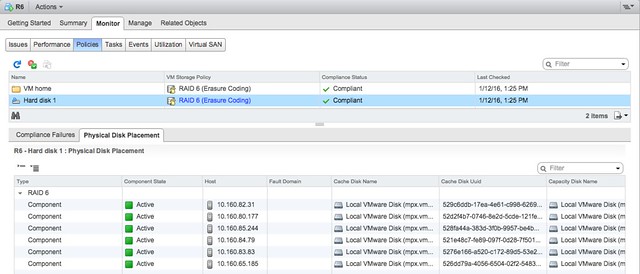
This customer basically leverages almost all functionality of our Software-Defined Storage offering. They have vSAN with locally attached storage devices (all NVMe) for certain workloads. They have storage arrays with vVols enabled for particular workloads. They have a VAIO Filter Driver which they use for replication. They also heavily rely on our APIs for monitoring and reporting, and as you can imagine they are a big believer in Policy-Based Management, as that is what helps them with placing workloads on a particular type of storage.
Now you may ask yourself, why on earth would they have vSAN and vVols sitting next to each other? Well, they had a significant investment in storage already, the storage solution was fully vVols capable and when they started using vSAN for certain projects they simply fell in love with Storage Policy-Based Management and decided to get it enabled for their storage systems as well. Even though the plan is to go all-in on vSAN over time, the interesting part here, in my opinion, is the “openness” of the platform. Want to go all-in on vSAN? Go ahead! Want to have traditional storage next to HCI? Go ahead! Want to use software-based data services? Go ahead! You can mix and match, and it is fully supported.
Anyway, just wanted to share that bit, and figured it would also be fun to bring up this 6.5 years old article again. One more thing, I think it is also good to realize how long these transitions tend to take. If you would have asked me in 2013 when we would see customers using this approach my guess would have been 2-3 years. Almost 6.5 years later we are starting to see this being seriously looked at. Of course, platforms have to mature, but also customers have to get comfortable with the idea. Change simply takes a lot of time.
 This week I presented at the German VMUG and a day after the event someone commented on my session. Well not really on my session, but more on my title. My title was “Goodbye SAN Huggers“. Mildly provocative indeed. “SAN Huggers” is a play on the term “Server Hugger“. That term has been around for the longest time and refers to people who prefer to be able to point out their servers. People who prefer the physical world, where every application ran on one server and every server was equal to one physical box.
This week I presented at the German VMUG and a day after the event someone commented on my session. Well not really on my session, but more on my title. My title was “Goodbye SAN Huggers“. Mildly provocative indeed. “SAN Huggers” is a play on the term “Server Hugger“. That term has been around for the longest time and refers to people who prefer to be able to point out their servers. People who prefer the physical world, where every application ran on one server and every server was equal to one physical box.