Frank and I have discussed this topic multiple times and it was briefly mentioned in Frank’s excellent series about over-sizing virtual machines; Zero Pages, TPS and the impact of a boot-storm. Pre-vSphere 4.1 we have seen it all happen, a host fails and multiple VMs need to be restarted. Temporary contention exists as it could take up to 60 minutes before TPS completes. Or of course when the memory pressure thresholds are reached the VMkernel requests TPS to scan memory and collapse pages if and where possible. However, this is usually already too late resulting in ballooning or compressing (if your lucky) and ultimately swapping. If it is an HA initiated “boot-storm” or for instance you VDI users all powering up those desktops at the same time, the impact is the same.
Now one of the other things I also wanted to touch on was Large Pages, as this is the main argument our competitors are using against TPS. Reason for this being that Large Pages are not TPS’ed as I have discussed in this article and many articles before that one. I even heard people saying that TPS should be disabled as most Guest OS’es being installed today are 64Bit and as such ESX(i) will back even Small Pages (Guest OS) by Large Pages and TPS will only add unnecessary overhead without any benefits… Well I have a different opinion about that and will show you with a couple of examples why TPS should be enabled.
One of the major improvements in vSphere 4.0 is that it recognizes zeroed pages instantly and collapses them. I have dug around for detailed info but the best I could publicly find about it was in the esxtop bible and I quote:
A zero page is simply the memory page that is all zeros. If a zero guest physical page is detected by VMKernel page sharing module, this page will be backed by the same machine page on each NUMA node. Note that “ZERO” is included in “SHRD”.
(Please note that this metric was added in vSphere 4.1)
I wondered what that would look like in real life. I isolated one of my ESXi host (24GB of memory) in my lab and deployed 12 VMs with 3GB each with Windows 2008 64-Bit installed. I booted all of them up in literally seconds and as Windows 2008 zeroes out memory during boot I knew what to expect:
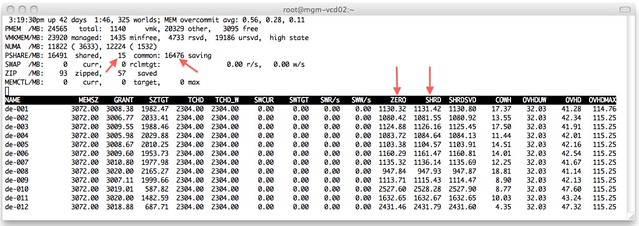
I added a couple of arrows so that it is a bit more obvious what I am trying to show here. On the top left you can see that TPS saved 16476MB and used 15MB to store unique pages. As the VMs clearly show most of those savings are from “ZERO” pages. Just subtract ZERO from SHRD (Shared Pages) and you will see what I mean. Pre-vSphere 4.0 this would have resulted in severe memory contention and as a result more than likely ballooning (if the balloon driver is already started, remember it is a “boot-storm”) or swapping.
Just to make sure I’m not rambling I disabled TPS (by setting Mem.ShareScanGHz to 0) and booted up those 12 VMs again. This is the result:
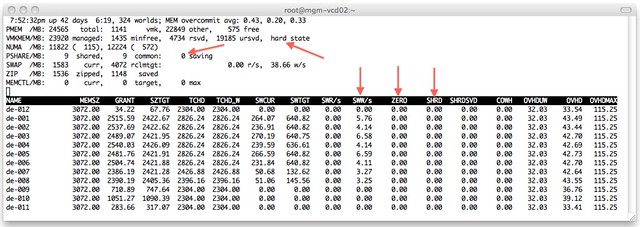
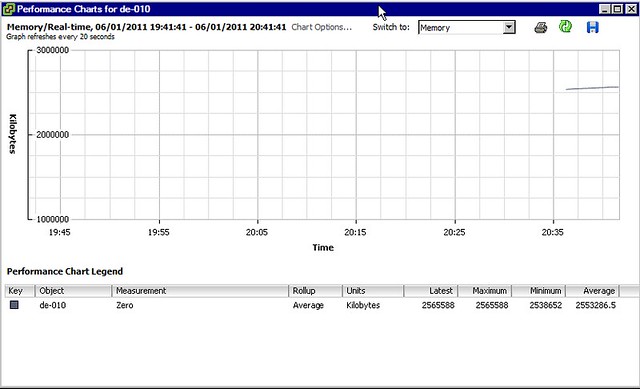
As shown at the top, the hosts status is “hard” as a result of 0 page sharing and even worse, as can be seen on a VM level, most VMs started swapping. We are talking about VMkernel swap here, not ballooning. I guess that clearly shows why TPS needs to be enabled and where and when you will benefit from it. Please note that you can also see “ZERO” pages in vCenter as shown in the screenshot below.
One thing Frank and I discussed a while back, and I finally managed to figure out, is why after boot of a Windows VM the “ZERO” pages still go up and fluctuate so much. I did not know this but found the following explanation:
There are two threads that are specifically responsible for moving threads from one list to another. Firstly, the zero page thread runs at the lowest priority and is responsible for zeroing out free pages before moving them to the zeroed page list.
In other words, when an application / service or even Windows itself “deprecates” the page it will be zeroed out by the “zero page thread” aka garbage collector at some point. The Page Sharing module will pick this up and collapse the page instantly.
I guess there is only one thing left to say, how cool is TPS?!
Pingback – linked to in vAcronym post on TPS – Thanks for the great information.
I don’t remember reading about that improvement in 4.1, but this is pretty schwanky. I am going to have to test it.. this could influence some design specifics in an environment. For instance, which VMs can boot up as high priority, etc. I always pushed for keeping that number to a minimum, but with HA using “round robin” power-ons and this improvement to TPS… maybe it isn’t as much of a concern? I still think you shouldn’t go overboard, but this certainly would have an impact for the better.
Indeed you shouldn’t go overboard, but I tested up to 15 VMs booting in literally seconds on the same host. I saw I think in total 50MB compressed memory and that is it, rest of it was all down to TPS.
(15 x 3GB vs 24GB of memory in my host)
Great info Duncan. Maybe you could write an article about changing the MMU to run in software mode instead of hardware. Your servers are only backed up by large pages if the MMU is running in hardware mode.
This could be a design choice if you wanted to prioritize TPS and reclaim more memory.
Duncan, you said “One of the major improvements in vSphere 4.0 is that it recognizes zeroed pages instantly and collapses them” but later “Pre-vSphere 4.1 this would have resulted in severe memory contention”. Didn’t you meant pre-vSphere 4.0 ?
That it correct, typo…. it should be 4.0. But I am trying to get that 100% validated currently.
One thing I’ve heard a couple of times is that TPS isnt as effective on server2008 (or R2 depending on who you talk to) due to windows encrypting memory pages…
Is there any truth to this, I havent found any info on it from MS and it doesn’t seem right to me (adding an encryption overhead on high-speed memory…)
I also picked up the 4.0 – 4.1 mismatch, where is this enhancement introduced?
Cheers,
Doug
Do you mean “ASLR” Doug cause I didn’t know there was real encryption out there? If it is ASLR it will not really make a difference in my opinion as most of Windows itself isn’t taking “advantage” of the ASLR capabilities.
This article actually shows that by the way: http://blogs.kraftkennedy.com/index.php/2010/04/26/effect-of-aslr-on-transparent-page-sharing-in-vmware-vsphere/
But if I have the time I will try to validate it for you.
I suspect ASLR was what was eluded to, the people I heard about the issue from specifically mentioned encryption… but I’d treat that with a grain of salt.
Thanks for you reply, puts one more problem to rest 🙂
Regarding ASLR, whether or not windows is leveraging it, it is my understanding that this will not affect TPS because:
a.) the actual contents of the memory pages are still the same … the are not, for instance, encrypted (as mentioned by the other commenter)
b.) ASLR merely locates those pages in different locations
In other words, the memory page contents are the same, it’s just the location that changes. Thus, when TPS triggers, it will still find identical pages and be able to collapse them … ASLR will merely mean that those pages are not located in the same address in each VM.
Can you confirm this?
It has been my understanding that when Large Pages are in play, vSphere will completely defer TPS operations until memory pressure it felt.
If that is correct, when you say that Zero Pages are recognized “instantly,” does that mean:
a.) the moment windows touches/zeroes the page
(potentially *before* memory pressure is felt
and therefore *before* TPS is scouring for
sharing opportunities)
b.) or, instead, is the zero page only recognized
once memory pressure is felt and TPS is working
Your examples seem to imply the former — that zero pages are being shared even before TPS is actively looking for other opportunties. Or did that zero sharing not kick in till the 24 GB in your host were exceed and TPS was now “looking for the 0s”?
Is that correct? Thanks for the clarification for those of us who revel in the details.
Very nice post Duncan. How do you get resxtop (in vma) to show the ZERO and SHRD column?
You have to use the vMA 4.1 (I don’t think it is is 4.0). Then switch to the memory mode and select the COW field.
(Launch resxtop, type m for memory, I type V for only Virtual Machines, type f then m and enter for COW fields)
This also works against ESX/ESXi 4.0.
Indeed, you will need vMA 4.1
the way you describe it suggests that even though large pages are used, when they get zeroed, TPS will collapse it. that would make TPS even cooler than i thought it was.. is that true though?
as for ASLR, it randomizes at 64kB bounderies. with TPS checking 4kB pages, it shouldn’t matter at all wether ASRL is used or not. but still it does; we see a 5-10% decrease in shared memory. i still haven’t found a solid explanation for that behaviour. only thing i know is that the first page of the loaded memory block gets changed (pointers and such) but that’s not enough to account for this decrease. curious 🙂
Hold on Herco. Small pages that are zeroed and backed by large pages will be recognized. Large pages backed by Large more than likely won’t but I haven’t tested it.
Would love to see some stats on performance when using large/large pages and memory contentioned occurs. Since ESX will have to break up the pages, will this only affect the one VM, or every other VM on this host as well, and how bad?
For what I’ve read going for a large/large combo seems to be a performance win on most heavy workload.
Nice article, Duncan.
Eric
What level of cost is incurred when the guest OS wishes to use a shared zero page? Presumably, the first guest write to a shared zeroed page is going to incur a large overhead as the page is unshared and backed with physical memory…
That wouldn’t be any different than a normal shared page. copy on write, so a new page will need to be allocated. I cannot really express in latency or % what the overhead would be but I would say it is neglect-able.
There may be some unintended consequences of the changes to enable sharing of zero pages even when large pages are used. I get vmkernel messages indicating that I/O processing gets blocked and retried up to 10-20 times on a 4.1 + Nehalem host with Windows 2008 R2 guests running SQL server. I opened an SR with VMWare support and was told this was happening because I/O pins pages in the driver, a (very small) P2MCache is used and that it is not a problem because the I/O is getting retried. What do you think?
Hi,
I cant find SHRDSVD and SHRD in esxtop. How to enable these counters?
press M
then press F followed by N (COW)
Great article, and which leads me to another question do we have a formula to calculate how much memory can be over committed by TPS?
Hi Duncan, great post!
I got a question, is there any way to disable the use of Large Pages and enable the use of TPS since the ESXi starts, i.e., we don’t want to wait until the host is with memory contention to brake down the 2 MB Large Pages into 4 KB pages to start doing TPS.
So, is there a way to disable Large Pages and enable TPS?
Yes, you can set Mem.AllocGuestLargePage to 0