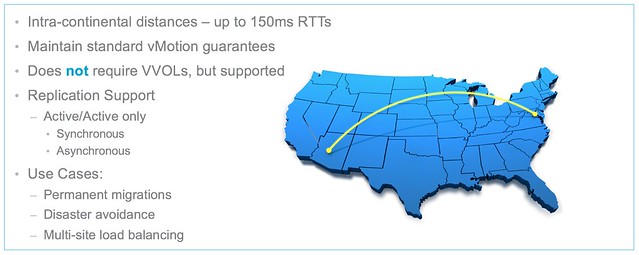
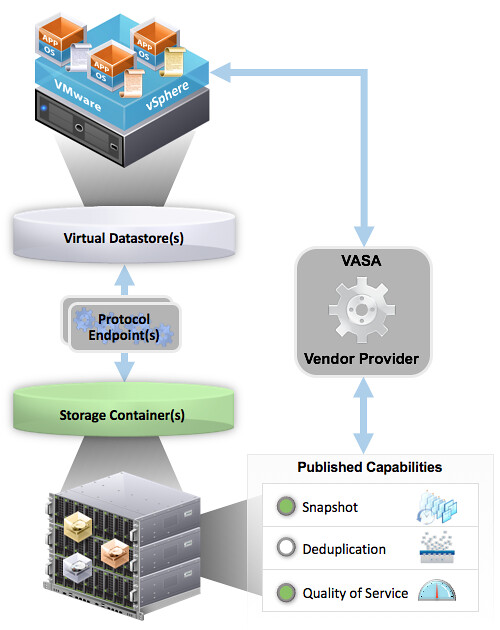
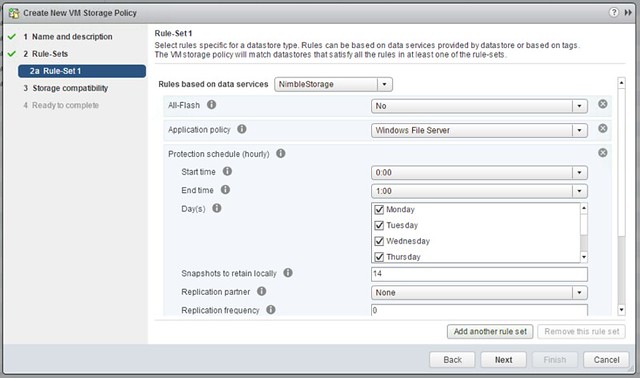
Just a short post to point out that I updated the VVol section in the HA Deepdive. If you downloaded it, make sure to download the latest version. Note that I have added a version number to the intro and a changelog at the end so you can see what changes. Also, I recommend subscribing to it, as I plan to do some more updates in the upcoming months. For the update I’ve been playing with a Nimble (virtual) array all day today and it allowed me to create some cool screenshots of how HA works in a VVol environment. I was also seriously impressed by how easy it was to setup the Nimble (virtual) array and how simple VVol was to configure for them. Not just that, but the number of policy options Nimble exposes, I was amazed. Below is just an example of some of the things you can configure!
The screenshot below shows the Virtual Volumes created for a VM, this is the view from a Storage perspective: