Most of us have been using DRS for the longest time. To be honest, not much has changed over the past years, sure there were some tweaks and minor changes but nothing huge. In 6.5 however there is a big feature introduced, but lets just list them all for completeness sake:
- Predictive DRS
- Network-Aware DRS enhancements
- DRS profiles
First of all Predictive DRS. This is a feature that the DRS team has been working on for a while. It is a feature that integrates DRS with VROps to provide placement and balancing decisions. Note that this feature will be in Tech Preview until vRealize Operations releases their version of vROPs which will be fully compatible with vSphere 6.5, hopefully sometime in the first half of next year. Brian Graf has some additional details around this feature here by the way.
Note that of course DRS will continue to use the data provided by vCenter Server, it will on top of that however also leverage VROps to predict what resource usage will look like, all of this based on historic data. You can imagine a VM currently using 4GB of memory (demand), however every day around the same time a SQL Job runs which makes the memory demand spike up to 8GB. This data is available through VROps now and as such when making placement/balancing recommendations this predicted resource spike can now be taken in to consideration. If for whatever reason however the prediction is that the resource consumption will be lower then DRS will ignore the prediction and simply take current resource usage in to account, just to be safe. (Which makes sense if you ask me.) Oh and before I forget, DRS will look ahead for 60 minutes (3600 seconds).
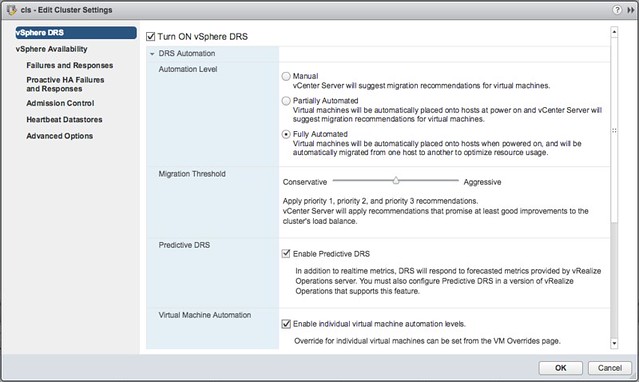
How do you configure this? Well that is fairly straight forward when you have VROps running, go to your DRS cluster and click edit settings and enable the “Predictive DRS” option. Easy right? (See screenshot below) You can also change that look ahead value by the way, I wouldn’t recommend it though but if you like you can add an advanced setting called ProactiveDrsLookaheadIntervalSecs.
One of the other features that people have asked about is the consideration of additional metrics during placement/load balancing. This is what Network-Aware DRS brings. Within Network IO Control (v3) it is possible to set a reservation for a VM in terms of network bandwidth and have DRS consider this. This was introduced in vSphere 6.0 and now with 6.5 has been improved. With 6.5 DRS also takes physical NIC utilization in to consideration, when a host has higher than 80% network utilization it will consider this host to be saturated and not consider placing new VMs.
And lastly, DRS Profiles. So what are these? In the past we’ve seen many new advanced settings introduced which allowed you to tweak the way DRS balanced your cluster. In 6.5 several additional options have been added to the UI to make it easier for you to tweak DRS balancing, if and when needed that is as I would expect that for the majority of DRS users this would not be the case. Lets look at each of the new options:
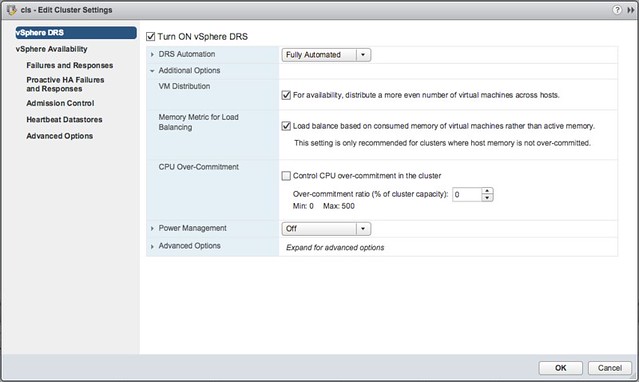
So there are 3 options here:
- VM Distribution
- Memory Metric for Load Balancing
- CPU Over-Commitment
If you look at the description then I think they make a lot of sense. Especially the first two options are options I get asked about every once in a while. Some people prefer to have a more equally balanced cluster in terms of number of VMs per host, which can be done by enable “VM Distribution”. And for those who much rather load balance on “consumed” vs “active” memory you can also enable this. Now the “consumed” vs “active” is almost a religious debate, personally I don’t see too much value, especially not in a world where memory pages are zeroed when a VM boots and consumed is always high for all VMs, but nevertheless if you prefer you can balance on consumed instead. Last is the CPU Over-Commitment, this is one that could be useful when you want to limit the number of vCPUs per pCPU, apparently this is something that many VDI customers have asked for.
I hope that was useful, we are aiming to update the vSphere Clustering Deepdive at some point as well to include some of these details…
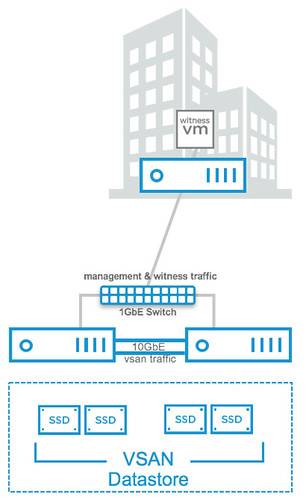 Next up on the list is 2-node direct connect. What does this mean? Well it basically means you can now cross-connect two VSAN hosts with a simple ethernet cable as shown in the diagram in the right. Big benefit of course is that you can equip your hosts with 10GbE NICs and get 10GbE performance for your VSAN traffic (and vMotion for instance) but don’t incur the cost of a 10GbE switch.
Next up on the list is 2-node direct connect. What does this mean? Well it basically means you can now cross-connect two VSAN hosts with a simple ethernet cable as shown in the diagram in the right. Big benefit of course is that you can equip your hosts with 10GbE NICs and get 10GbE performance for your VSAN traffic (and vMotion for instance) but don’t incur the cost of a 10GbE switch.