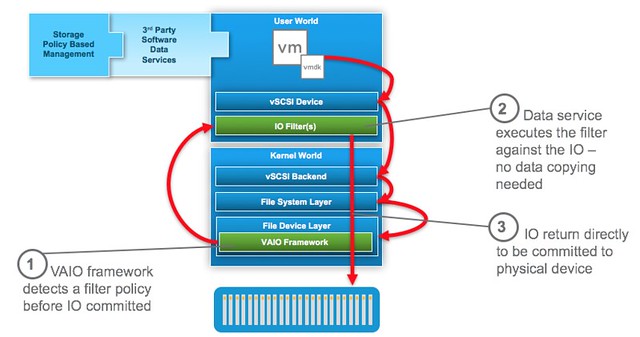
A while ago (2014) I wrote an article on TPS being disabled by default in future release. (Read KB 2080735 and 2097593 for more info) I described why VMware made this change from a security perspective and what the impact could be. Even today, two years later, I am still getting questions about this and what for instance the impact is on swap files. With vSAN you have the ability to thin provision swap files, and with TPS being disabled is this something that brings a risk?
Lets break it down, first of all what is the risk of having TPS enabled and where does TPS come in to play?
With large pages enabled by default most customers aren’t actually using TPS to the level they think they are. Unless you are using old CPUs which don’t have EPT or RVI capabilities, which I doubt at this point, it only kicks in with memory pressure (usually) and then large pages get broken in to small pages and only then will they be TPS’ed, if you have severe memory pressure that usually means you will go straight to ballooning or swapping.
Having said that, lets assume a hacker has managed to find his way in to you virtual machine’s guest operating system. Only when memory pages are collapsed, which as described above only happens under memory pressure, will the hacker be able to attack the system. Note that the VM/Data he wants to attack will need to be on the located on the same host and the memory pages/data he needs to breach the system will need to be collapsed. (actually, same NUMA node even) Many would argue that if a hacker gets that far and gets all the way in to your VM and capable of exploiting this gap you have far bigger problems. On top of that, what is the likelihood of pulling this off? Personally, and I know the VMware security team probably doesn’t agree, I think it is unlikely. I understand why VMware changed the default, but there are a lot of “IFs” in play here.
Anyway, lets assume you assessed the risk and feel you need to protect yourself against it and keep the default setting (intra-VM TPS only), what is the impact on your swap file capacity allocation? As stated when there is memory pressure, and ballooning cannot free up sufficient memory and intra-VM TPS is not providing the needed memory space either the next step after compressing memory pages is swapping! And in order for ESXi to swap memory to disk you will need disk capacity. If and when the swap file is thin provisioned (vSAN Sparse Swap) then before swapping out those blocks on vSAN will need to be allocated. (This also applies to NFS where files are thin provisioned by default by the way.)
What does that mean in terms of design? Well in your design you will need to ensure you allocate capacity on vSAN (or any other storage platform) for your swap files. This doesn’t need to be 100% capacity, but should be more than the level of expected overcommitment. If you expect that during maintenance for instance (or an HA event) you will have memory overcommitment of about 25% than you could ensure you have 25% of the capacity needed for swap files available at least to avoid having a VM being stunned as new blocks for the swap file cannot be allocated and you run out of vSAN datastore space.
Let it be clear, I don’t know many customers running their storage systems in terms of capacity up to 95% or more, but if you are and you have thin swap files and you are overcommitting and TPS is disabled, you may want to re-think your strategy.