Admission Control is always a difficult topic when I talk to customers. It seems that many people still don’t fully grasp the concept, or simply misunderstand how it works. To be honest, I can’t blame them. It doesn’t always make sense when you think things through. Most recently for Admission Control we introduced a mechanism in which you can specify what the “tolerated performance loss” should be for any given VM. This isn’t really admission control unfortunately as it doesn’t stop you from powering on new VMs, it does, however, warn you if you reach the threshold where a host failure would lead to the specified performance degradation.
After various discussion with the HA team over the past couple of years, we are now exploring what we can change about Admission Control to give you more options as a user to ensure VMs are not only restarted but also receive the resources you expect them to receive. As such, the HA team is proposing 3 different ways of doing Admission Control, and we would like to have your feedback on this potential change:
- Admission Control based on reserved resources and VM overheads
This is what you have today, nothing changes here. We use the static reservations and ensure that all VMs can be powered on! - Admission Control based on consumed resources
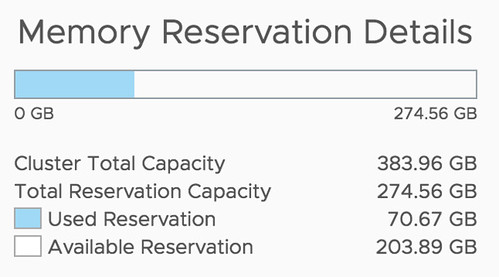
This is similar to the “performance degradation tolerated” option. We will look at the average consumed CPU and Memory resources, let’s say past 24 hours), and base our admission control calculations on that. This will allow you to guarantee performance for workloads to be similar after a failure. - Admission Control based on configured resources
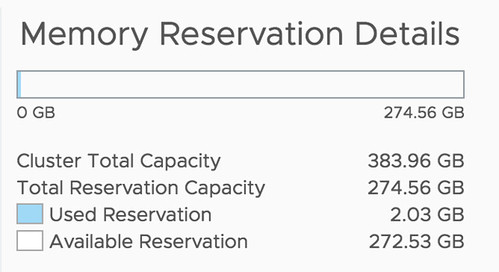
This is a static way of doing admission control similar to the first. The only difference is that here Admission Control will do the calculations based on the resources configured. So if you configured a VM with 24GB of memory, then we will do the math with 24GB of memory for that VM. The big advantage, of course, is that the VMs will always be able to claim the resources they have assigned.
In our opinion, adding these options should help to ensure that VMs will receive the resources you (or your customers) would expect them to get. Please help us by leaving a comment/providing feedback. If you agree that this would be helpful then let us know, if you have serious concerns then we would also like to know. Please help shape the future of HA!

 Another amazing story was
Another amazing story was 

 Norwegian Cruise Line mentioned that they also still use traditional storage, same for ConAgra. It is great that you can do this with vSAN, keep your “old investment”, while building out the new solution. Over time most applications will move over though. One thing that they feel is missing with hyper-converged is the ability to run large memory configurations or large storage capacity configurations. (Duncan: Not sure I entirely agree, limits are very close to non-HCI servers, but I can see what they are referring to.) One thing to note as well from an operational aspect is that certain types of failures are completely different, and handled completely different in an HCI world, that is definitely something to get familiar with. Another thing mentioned was the opportunity of HCI in the Edge, nice small form factor should be possible and should allow running 10-15 VMs. It removes the need for “converged infra” in those locations or traditional storage in general in those environments. Especially now that compute/processing and storage requirements go up at the edge due to IoT and data analytics that happens “locally”.
Norwegian Cruise Line mentioned that they also still use traditional storage, same for ConAgra. It is great that you can do this with vSAN, keep your “old investment”, while building out the new solution. Over time most applications will move over though. One thing that they feel is missing with hyper-converged is the ability to run large memory configurations or large storage capacity configurations. (Duncan: Not sure I entirely agree, limits are very close to non-HCI servers, but I can see what they are referring to.) One thing to note as well from an operational aspect is that certain types of failures are completely different, and handled completely different in an HCI world, that is definitely something to get familiar with. Another thing mentioned was the opportunity of HCI in the Edge, nice small form factor should be possible and should allow running 10-15 VMs. It removes the need for “converged infra” in those locations or traditional storage in general in those environments. Especially now that compute/processing and storage requirements go up at the edge due to IoT and data analytics that happens “locally”.