On Reddit, someone asked what DRS advanced setting IsClusterManaged does and if it is even legit. I can confirm it is legit, it is a setting which was introduced to prevent customers from disabling DRS while the cluster is managed by vCloud Director for instance. As disabling DRS would lead to deleting resource pools, which would be a very bad situation to find yourself in when you run vCloud Director as it leans on DRS Resource Pools heavily. So if you see the advanced setting IsClusterManaged in your environment for DRS, just leave it alone, it is there for a reason. (Most likely because you are using something like vCloud Director…)
vSphere
I want vSphere HA to use a specific Management VMkernel interface
This comes up occasionally, customers have multiple Management VMkernel interfaces and see vSphere HA traffic on both of the interfaces, or on the incorrect interface. In some cases, customers use the IP address of the first management VMkernel interface to connect the host to vCenter and then set an isolation address that is on the network of the second management VMkernel so that HA uses that network. This is unfortunately not how it works. I wrote about this 6 years ago, but it never hurts to reiterate as it came up twice over the past couple of weeks. The “management” tickbox is all about HA traffic. Whether “Management” is enabled or not makes no difference for vCenter or SSH for instance. If you create a VMkernel interface without the Management tickbox enabled you can still connect to it over SSH and you can still use the IP to add it to vCenter Server. Yes, it is confusing, but that is how it works.

If you want the interface to not be used by vSphere HA, make sure to untick “Management”. Note, this is not the case for vSAN, with vSAN automatically the vSAN network is used by HA. This only pertains to traditional, non-vSAN based, infrastructures.
Mixing versions of ESXi in the same vSphere / vSAN cluster?
I have seen this question being asked a couple of times in the past months, and to be honest I was a bit surprised people asked about this. Various customers were wondering if it is supported to mix versions of ESXi in the same vSphere or vSAN Cluster? I can be short whether this is support or not, yes it is but only for short periods of time (72hrs max). Would I recommend it? No, I would not!
Why not? Well mainly for operational reasons, it just makes life more complex. Just think about a troubleshooting scenario, you now need to remember which version you are running on which host and understand the “known issues” for each version. Also, for vSAN things are even more complex as you could have “components” running on a different version of ESXi. On top of that, it could even be the case that a certain command or esxcli namespace is not available on a particular version of ESXi.
Another concern is when doing upgrades or updates, you need to take the current version into account when updating, or more importantly when upgrading! Also, remember that firmware/driver combination may be different for a particular version of vSphere/vSAN as well, this could also make life more complex and definitely increases the chances of making mistakes!
Is this documented anywhere? Yes, check out the following KB:
vSphere HA virtual machine failed to failover error on VMs in a partitioned cluster
I received two questions this week around partition scenarios where after the failure has been lifted some VMs display the error message “vSphere HA virtual machine failed to failover”. The question that then arises is: why did HA try to restart it, and why did it fail? Well, first of all, this is an error that in most cases you can safely ignore. There’s a KB on the topic which gives a bit of detail to be found here, but let me explain also in a bit more depth.
In a partitioning scenario, each partition will have its own primary node. If there is no form of communication (datastore/network) possible, what the HA primary will do is it will list all the VMs that are currently not running within that partition. It will also want to try to restart those VMs. A partition is extremely uncommon in normal environments but may happen in a stretched cluster. In a stretched cluster when a partition happens a datastore only belongs to 1 location. The VMs which appear to be missing typically are running in the other location, as typically the other location will have access to that particular datastore. Although the primary has listed these VMs as “missing and need to restart” it will not be able to do this. Why? It doesn’t have access to the datastore itself, or when it has access to the datastore the files are locked as the VMs are still running. As a result, this will, unfortunately, be reported as a failed failover. Even though the VM was still running and there was no need for a failover. So if you hit this during certain failure scenarios, and the VMs were running as you expected, you can safely ignore this error.
How to test failure scenarios!
Almost on a weekly basis, I get a question about unexpected results during the testing of certain failure scenarios. I usually ask first if there’s a diagram that shows the current configuration. The answer is usually no. Then I would ask if they have a failure testing matrix that describes the failures they are introducing, the expected result and the actual result. As you can guess, the answer is usually “euuh a what”? This is where the problem usually begins. The problem usually gets worse when customers try to mimic a certain failure scenario.
What would I do if I had to run through failure scenarios? When I was a consultant we always started with the following:
- Document the environment, including all settings and the “why”
- Create architectural diagrams
- Discuss which types of scenarios would need to be tested
- Create a failure testing matrix that includes the following:
- Type of failure
- How to create the scenario
- Preferably include diagrams per scenario displaying where the failure is introduced
- Expected outcome
- Observed outcome
What I would normally also do is describe in the expected outcome section the theory around what should happen. Maybe I should just give an example of a failure and how I would describe it more or less.
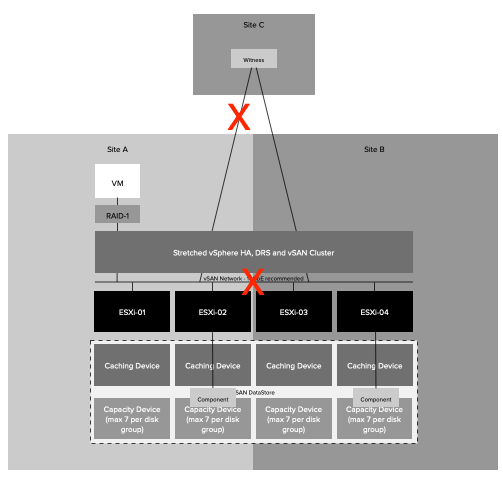
Type Failure: Site Partition
How to: Disable links between Site-A / Site-C and Site-A / Site-B
Expected outcome: The secondary location will bind itself with the witness and will gain ownership over all components. In the preferred location, the quorum is lost, as such all VMs will appear as inaccessible. vSAN will terminate all VMs in the preferred location. This is from an HA perspective however a partition and not an isolation as all hosts in Site-A can still communicate with each other. In the secondary location vSphere HA will notice hosts are missing. It will validate that the VMs that were running are running, or not running. All VMs which are not running, and have accessible components, will be restarted in the secondary location.
Observed outcome: The observed outcome was similar to the expected outcome. It took 1 minute and 30 seconds before all 20 test VMs were restarted.
In the above example, I took a very basic approach and didn’t even go into the level of depth you probably should go. I would, for instance, include the network infrastructure as well and specify exactly where the failure occurs, as this will definitely help during troubleshooting when you need to explain why you are observing a particular unexpected behavior. In many cases what happens is that for instance a site partition is simulated by disabling NICs on a host, or by closing certain firewall ports, or by disabling a VLAN. But can you really compare that to a situation where the fiber between two locations is damaged by excavations? No, you can not compare those two scenarios. Unfortunately this happens very frequently, people (incorrectly) mimic certain failures and end up in a situation where the outcome is different than expected. Usually as a result of the fact that the failure being introduced is also different than the failure that was described. If that is the case, should you still expect the same outcome? You probably should not.
Yes I know, no one likes to write documentation and it is much more fun to test things and see what happens. But without recording the above, a successful implementation is almost impossible to guarantee. What I can guarantee though is that when something fails in production, you most likely will not see the expected behavior when you have not tested the various failure scenarios. So please take the time to document and test, it is probably the most important step of the whole process.