I wrote a post and recorded a short demo that explained this cool new feature called Scalable Shares, part of vSphere 7 / DRS, last week. I didn’t want to go too deep in the post, but now that I am getting more questions about how this actually works, I figured I would provide some examples to explain it. As mentioned in my previous post, Scalable Shares solves a problem many have been facing over the last decade or so, which is that DRS does not take the number of VMs in the pool into account when it comes to allocating resources. So as an example:
Just imagine you have a resource pool called “Test”, it is a resource pool with “normal” shares and has 4 VMs. Let’s say this resource pool has 4000 shares.

Now compare that resource pool to the “Production” pool, which has shares set to “high” but has 24 VMs. Let’s say this resource pool has 8000 shares.

This is a very extreme example, but it shows you immediately what the problem is. On a per VM basis, the VMs in the production resource pool, would receive far less resources when there’s contention as DRS would simply divvy up the resources based on the assignment of the shares of the resource pool. Test would receive 1/3 of the resource (4000 of 12000 total shares), and production would receive 2/3 of the resources (8000 of 12000 total shares). If you would divide that by the number of VMs in each pool, it is obvious that the VMs in Test are in a better situation than the VMs in Production.
So how would this work if you Scalable Shares enabled? Well, let’s list some facts first:
- A resource pool looks like a VM with 4 vCPUs and 16GB of memory to DRS
- Scalable Shares looks at the total amount of shares in the Resource Pool (all vCPUs!)
- For a resource pool high is 8000 shares, normal is 4000 shares and low is 2000 shares
- Note, that this is based on 4 vCPUs, so the real values are 2000, 1000, 500.
The calculation would be as following:
Resource Pool Shares = (4 vCPU * Shares of Pool )* (Total number of shares of all vCPUs in resource pool)
So as an example, in the case I have Test with normal shares and 4 VMs, and Production with high shares and 24 VMs, and all VMs have a single vCPU with normal priority the calculation for those two resource pools would be:
Test = (4 * 1000) * (4 * 1000) = 16,000,000 shares
Production = (4 * 2000) * (24 * 1000) = 192,000,000 shares
In other words, Production has 12 times more the number of shares as Test has when Scalable Shares is enabled. I hope that clears things up!
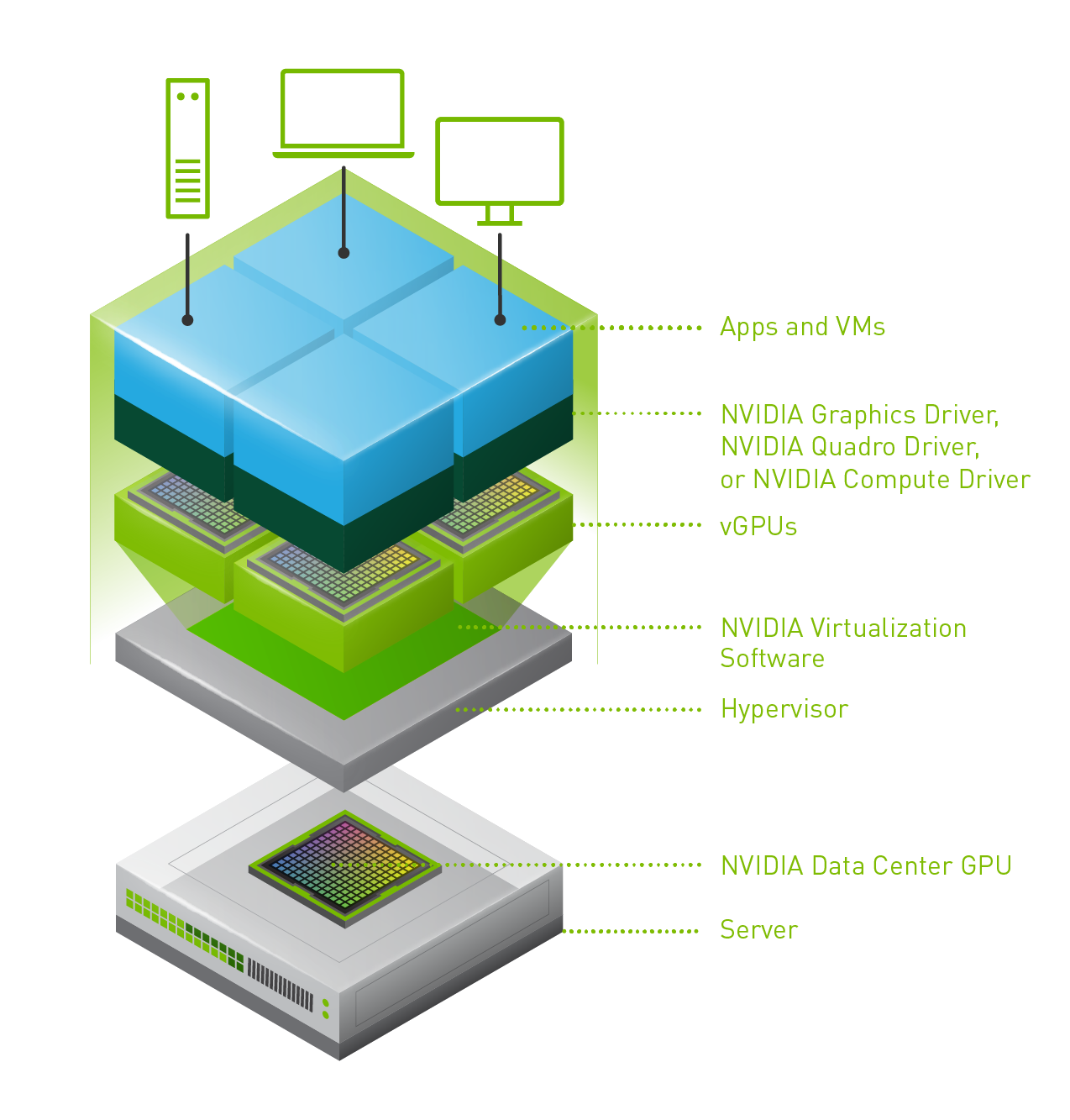 Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in
Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in 

