A while ago I wrote an article about the queue depth of certain disk controllers and tried to harvest some of the values and posted those up. William Lam did a “one up” this week and posted a script that can gather the info which then should be posted in a Google Docs spreadsheet, brilliant if you ask me. (PLEASE run the script and lets fill up the spreadsheet!!) But some of you may still wonder why this matters… (For those who didn’t read some of the troubles one customer had with a low-end shallow queue depth disk controller, and Chuck’s take on it here.) Considering the different layers of queuing involved, it probably makes most sense to show the picture from virtual machine down to the device.
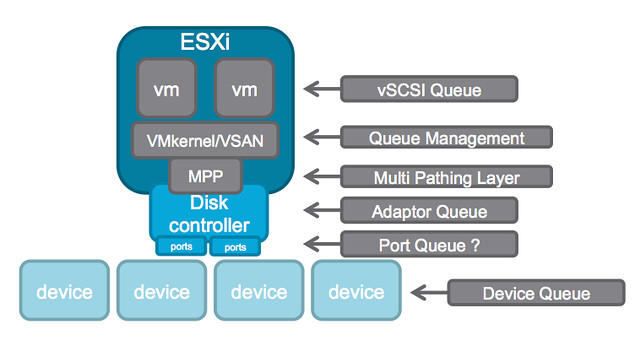
In this picture there are at least 6 different layers at which some form of queuing is done. Within the guest there is the vSCSI adaptor that has a queue. Then the next layer is VMkernel/VSAN which of course has its own queue and manages the IO that is pushed to the MPP aka muti-pathing layer the various devices on a host. On the next level a Disk Controller has a queue, potentially (depending on the controller used) each disk controller port has a queue. Last but not least of course each device (i.e. a disk) will have a queue. Note that this is even a simplified diagram.
If you look closely at the picture you see that IO of many virtual machines will all flow through the same disk controller and that this IO will go to or come from one or multiple devices. (Typically multiple devices.) Realistically, what are my potential choking points?
- Disk Controller queue
- Port queue
- Device queue
Lets assume you have 4 disks; these are SATA disks and each have a queue depth of 32. Total combined this means that in parallel you can handle 128 IOs. Now what if your disk controller can only handle 64? This will result in 64 IOs being held back by the VMkernel / VSAN. As you can see, it would beneficial in this scenario to ensure that your disk controller queue can hold the same number of IOs (or more) as your device queue can hold.
When it comes to disk controllers there is a huge difference in maximum queue depth value between vendors, and even between models of the same vendor. Lets look at some extreme examples:
HP Smart Array P420i - 1020
Intel C602 AHCI (Patsburg) - 31 (per port)
LSI 2008 - 25
LSI 2308 - 600
For VSAN it is recommended to ensure that the disk controller has a queue depth of at least 256. But go higher if possible. As you can see in the example there are various ranges, but for most LSI controllers the queue depth is 600 or higher. Now the disk controller is just one part of the equation, as there is also the device queue. As I listed in my other post, a RAID device for LSI for instance has a default queue depth of 128 while a SAS device has 254 and a SATA device has 32. The one which stands out the most is the queue depth of the SATA device, only a queue depth of 32 and you can imagine this can once again become a “choking point”. However, fortunately the shallow queue depth of SATA can easily be overcome by using NL-SAS drives (nearline serially attached SCSI) instead. NL-SAS drives are essentially SATA drives with a SAS connector and come with the following benefits:
- Dual ports allowing redundant paths
- Full SCSI command set
- Faster interface compared to SATA, up to 20%
- Larger (deeper) command queue [depth]
So what about the cost then? From a cost perspective the difference between NL-SAS and SATA is for most vendors negligible. For a 4TB drive the difference at the time of writing on different website was on average $ 30,-. I think it is safe to say that for ANY environment NL-SAS is the way to go and SATA should be avoided when possible.
In other words, when it comes to queue depth: spent a couple of extra bucks and go big… you don’t want to choke your own environment to death!