We just published the third episode of the Unexplored Territory. This time we are talking to Shawn Bass, who is the CTO for the EUC business unit. Shawn talks about various aspects of End User Computing, especially security is a big focus at the moment, aka zero trust. Make sure to listen to the episode, either via the embedded player below, or just add the podcast to your podcast app (google, apple, overcast etc), or spotify, and listen to it that way.
vdi
Instant Clone in vSphere 6.7 rocks!
 I wrote a blog post a while back about VMFork, which then afterwards got rebranded to Instant Clone. In the vSphere 6.7 release there has been a major change to the architecture of VMFork aka Instant Clone, so I figured I would do an update on the post. As an update doesn’t stand out from the rest of the content I am sharing it as a new post.
I wrote a blog post a while back about VMFork, which then afterwards got rebranded to Instant Clone. In the vSphere 6.7 release there has been a major change to the architecture of VMFork aka Instant Clone, so I figured I would do an update on the post. As an update doesn’t stand out from the rest of the content I am sharing it as a new post.
Instant Clone was designed and developed to provide a mechanism that allows you to instantaneously create VMs. In the early days it was mainly used by folks who want to deploy desktops, by the desktop community this was often referred to as “just in time” desktops. These desktops would literally be created when the user tried to login, it is indeed that fast. How did this work? Well a good way to describe it is that it is essentially a “vMotion” of a VM on the same host with a linked clone disk. This essentially leads to a situation which looks as follows:
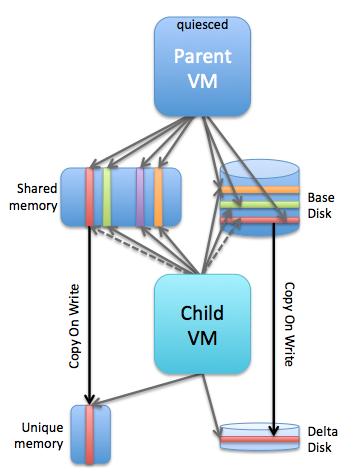
On a host you had a parent VM and a child VM associated with it. You would have a shared base disk, shared memory and then of course unique memory pages and a delta disk for (potential) changes written to disk. The reason customers primarily used this only with VDI at first was the fact that there was no public API for it. Of course folks like Alan Renouf and William Lam fought hard for public APIs internally and they managed to get things like the PowerCLI cmdlets and python vSphere SDK pushed through. Which was great, but unfortunately not 100% fully supported. On top of that there were some architectural challenges with the 1.0 release of Instant Clones. Mainly caused by the fact that VMs were pinned to a host (next to their parent VM) and as such things like HA, DRS, vMotion wouldn’t work. Now with version 2.0 this all changes. William already wrote an extensive blog post about it here. I just went over all of the changes and watched some internal training, and I am going to write some of my findings/learnings down as well, just so that it sticks… First let’s list the things that stood out to me:
- Targeted use cases
- VDI
- Container hosts
- Big data / hadoop workers
- DevTest
- DevOps
- There are two workflows for instant clone
- Instant clone a running a VM, source and generated VMs continue running
- Instant clone a frozen VM, source is frozen using guestRPC at point in time defined by customer
- No UI yet, but “simple API” available
- Integration with vSphere Features
- Now supported: HA, DRS, vMotion (Storage / XvMotion etc)
- Even when TPS is disabled (default) VMFork still leverages the P-Share technology to collapse the memory pages for efficiency
- There is no explicit parent-child relationship any longer
Let’s look at the use cases first, I think the DevTest / DevOps is interesting. You could for instance do an Instant Clone (live) of a VM and then test an upgrade for instance for the application running within the VM. For this you would use the first workflow that I mentioned above: instant clone a running VM. What happens here in the workflow is fairly straight forward. I am using William’s screenshots of the diagrams the developers created to explain it. Thanks William, and dev team 🙂

Now note that above when the first clone is created the source gets a delta disk as well. This is to ensure that the shared disk doesn’t change as that would cause problems for the target. Now when a 2nd VM is created and a 3 the source VM gets additional delta’s. This as you can imagine isn’t optimal and will over time even potentially slow down the source VM. Also one thing to point out is that although the mac address changes for the generated VM, you as the admin still need to make sure the Guest OS picks this up. As mentioned above, as there’s no UI in vSphere 6.7 for this functionality you need to use the API. If you look at the MOB you can actually find the InstantClone_Task and simply call that, for a demo scroll down. But as said, be careful as you don’t want to end up with the same VM with the same IP on the same network multiple times. You can get around the Mac/IP conflict issue rather easy and William has explained how in his post here. You can even change the port group for the NIC, for instance switch over to an isolated network only used for testing these upgrade scenarios etc.
That second workflow would be used for the following use cases: VDI, Container Hosts, Hadoop workers… all more or less the same type of use case. Scale out identical VMs fast! In this case, well lets look at the diagram first:

In the above scenario the Source VM is what they call “frozen”. You can freeze a VM by leveraging the vmware-rpctool and run it with “instantclone.freeze”. This needs to happen from within the guest, and note that you need to have VMware tools installed to have vmware-rpctool available. When this is executed, the VM goes in to a frozen state, meaning that no CPU instructions are executed. Now that you froze the VM you can go through the same instant clone workflow. Instant Clone will know that the VM is frozen. After the instant clone is create you will notice that there’s a single delta disk for the source VM and each generated VM will have its own delta disk as shown above. Big benefit is that the source VM won’t have many delta disks. Plus, you know for sure that every single VM you create from this frozen VM is 100% identical as they all resume from the exact same point in time. Of course when the instant clone is created the new VM is “unfrozen / resumed”, the source will remain frozen. Note that if for whatever reason the source is restarted / power cycled then the “frozen state” is lost. Another added benefit of the frozen VM is that you can automate the “identity / IP / mac” issue when leveraging the “frozen source VM” workflow. How do you do this? Well you disable the network, freeze it, instant clone it (unfreezes automatically), make network changes, enable network. William just did a whole blog post on how to do various required Guest changes, I would highly recommend reading this one as well!
So before you start using Instant Clone, first think about which of the two workflows you prefer and why. So what else did I learn?
As mentioned, and this is something I never realized, but even when TPS is disabled Instant Clone will still share the memory pages through the P-Share mechanism. P-Share is the same mechanism that TPS leverages to collapse memory pages. I always figured that you needed to re-enable TPS again (with or without salting), but that is not the case. You can’t even disable the use of P-Share at this point in time… Which personally I don’t think is a security concern, but you may think different about it. Either way, of course I tested this, below you see the screenshot of the memory info before and after an instant clone. And yes, TPS was disabled. (Look at the shares / saving values…)
Before:

After:

Last but not least, the explicit parent-child relationship caused several problems from a functionality stance (like HA, DRS, vMotion etc not being supported). Per vSphere 6.7 this is no longer the case. There is no strict relationship, and as such all the features you love in vSphere can be fully leveraged even for your Instant Clone VMs. This is why they call this new version of Instant Clone “parentless”.
If you are wondering how you can simply test it without diving in to the API too deep and scripting… You can use the Managed Object Browser (MOB) to invoke the method as mentioned earlier. I recorded this quick demo that shows this, which is based on a demo from one of our Instant Clone engineers. I recommend watching it in full screen as it is much easier to follow that way. (or watch it on youtube in a larger window…) Pay attention, as it is a quick demo, instant clone is extremely fast and the workflow is extremely simple.
And that’s it for now. Hope that helps those interested in Instant Clone / VMFork, and maybe some of you will come up with some interesting use cases that we haven’t thought about it. Would be good if you have use cases to share those in the comment section below. Thanks,
VMware ThinApp 4.7 Essentials by Peter Björk!
 About a year ago one of my colleagues reached out with some questions around book publishing. Many people ask me questions around what it takes, hours involved etc etc, and unfortunately many decide it is not the right time. I guess Peter Björk decided it was the right time as he managed to crank out this awesome book within a year. Congrats Peter, awesome work and major achievement!
About a year ago one of my colleagues reached out with some questions around book publishing. Many people ask me questions around what it takes, hours involved etc etc, and unfortunately many decide it is not the right time. I guess Peter Björk decided it was the right time as he managed to crank out this awesome book within a year. Congrats Peter, awesome work and major achievement!
The book is titled “VMware ThinApp 4.7 Essentials” and contains everything you need to know about ThinApp, or as the website states:
“VMware ThinApp 4.7 Essentials” shows you how to deploy ThinApp packages in order to improve the portability, manageability and compatibility of applications by encapsulating them from the underlying operating system on which they are executed.
In this book you will learn about how application virtualization works and how to deploy ThinApp packages. You will learn how to update and tweak ThinApp Projects before distribution. This book will then cover design and implementation considerations for future ThinApp projects.
You can find it on Amazon here: Kindle ($ 23.25) – Paper (54.99). Pick it up!
VMware View without HA?
I was discussing something with one of my former colleagues a couple of days ago. He asked me what the impact was of running VMware View in an environment without HA.
To be honest I am not a View SME, but I do know a thing or two about HA/vSphere in general. So the first thing that I mentioned was that it wasn’t a good idea. Although VDI in general is all about density not running HA in these environments could lead to serious issues when a host fails.
Now, just imagine you have 80 Desktop VMs per host running and roughly 8 hosts in a DRS only cluster on NFS based storage. One of those hosts is isolated from the network…. what happens?
- User connection is dropped
- VMDK Lock times out
- User tries to reconnect
- Broker powers on the VM on a new host
Now that sounds great doesn’t it? Well yeah in a way it does, but what happens when the host is not isolated anymore?
Indeed, the VMs were still running. So basically you have a split brain scenario. The only way in the past to avoid this was to make sure you had HA enabled and had set HA to power off the VM.
But with vSphere 4 Update 2 a new mechanism has been introduced. I wanted to stress this, as some people have already made assumption that it is part of AAM/HA. It actually isn’t… The question for powering off the VM to recover from the split brain scenario is generated by “hostd” and answered by “vpxa”. In other words, with or without HA enabled ESX(i) will recover the split brain
Again, I am most definitely not a Desktop/View guy so I am wondering how the View experts out there look against disabling HA on your View Compute Cluster. (Note that on the Management Layer this should be enabled.)
VMware Desktop Reference Architecture Workload Simulator (RAWC) 1.1
VMware has just released version 1.1 of the VMware Desktop Reference Architecture Workload Simulator (RAWC). As I know many of my readers are actively working on View projects I thought it might be of interest for you.
VMware Desktop Technical Marketing & TS Research Labs are jointly announcing the availability of VMware Desktop Reference Architecture Workload Simulator (RAWC) version 1.1. With RAWC 1.1, Solution Providers can better anticipate and plan for infrastructure requirements to support successful VMware View deployments for Windows 7 Migration.
RAWC 1.1 now simulates user workloads in Windows 7 environments and can be used to validate VMware View designs to support Windows 7 Migrations. RAWC 1.1 supports the following desktop applications in Windows 7 and Windows XP environments: Microsoft Office 2007, Microsoft Outlook, Microsoft Internet Explorer, Windows Media Player, Java code compilation simulator, Adobe Acrobat, McAfee Virus Scan, and 7-Zip.
RAWC 1.1 also includes bug fixes and several enhancements in test run configurations, usability and user interface. Please see RAWC 1.1 product documents for more details.
VMware partners can download RAWC 1.1 software and the product documents from VMware Partner Central:Sales Tools > Services IP.