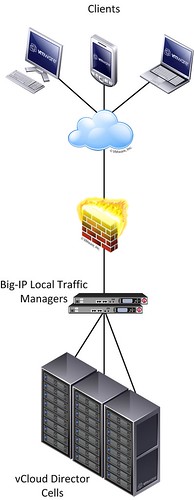
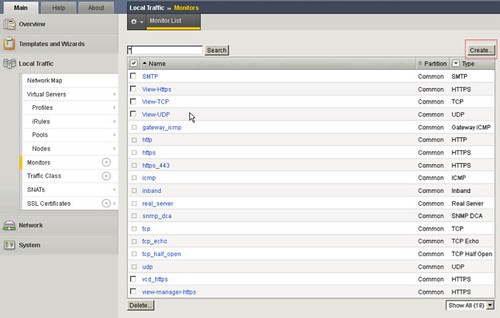
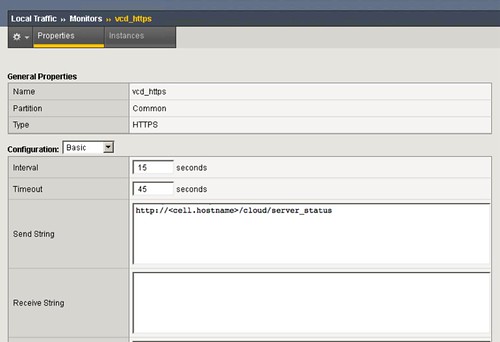
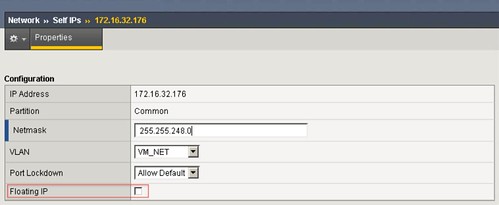
We all know how difficult it can be to implement and configure a new infrastructure. Racking, cabling, configuring VLANs, setting policies / permissions, firewalling etc. It is a lot of work… Well in a physical world it is a lot of work, in a vCloud Director environment that is slightly different. In this demo that I recorded I am going to show you:
- Login as a vCloud Admin
- How to create an organization
- How to create an organization virtual datacenter
- Selecting a specific compute tier
- Selecting all storage tiers
- Selecting a specific networking tier
- How to create an Edge Gateway
- How to create add a vApp to a Catalog
- Login as the tenant:
- Deploy a 3-tier vApp with each VM on a different storage tier
- Snapshot the full vApp
All of that in under 10 minutes, I could do it faster… but I guess it would be difficult to watch then :). Anyway, I hope this demo shows how easy it is to provide access and resources to a tenant in a vCloud environment .