Last week on our internal slack channel one of the field folks had a question. He was hitting a situation where vSAN File Services failed when creating a file share with the error “Failed to create the VDFS File System”. We went back and forth a bit and after a while I jumped on Zoom to look at the issue, and troubleshoot the environment. After testing various combinations of policies I noticed that a particular policy worked, whole another policy did not. At first it looked like that stretched cluster policies would not work but after creating a new policy with a different name it did work. One thing left, the name of the policy. It appears that the use of special characters in the VM Storage Policy name results in the error “Failed to create the VDFS File System”. In this particular case the VM Storage Policy that was used was “stretched – mirrored FTT=1 RAID-1”. The character that was causing the issue was the “=” character.
How do you resolve it? Simply change the name of the policy. For instance, the following would work: “stretched – mirrored FTT1 RAID-1”.

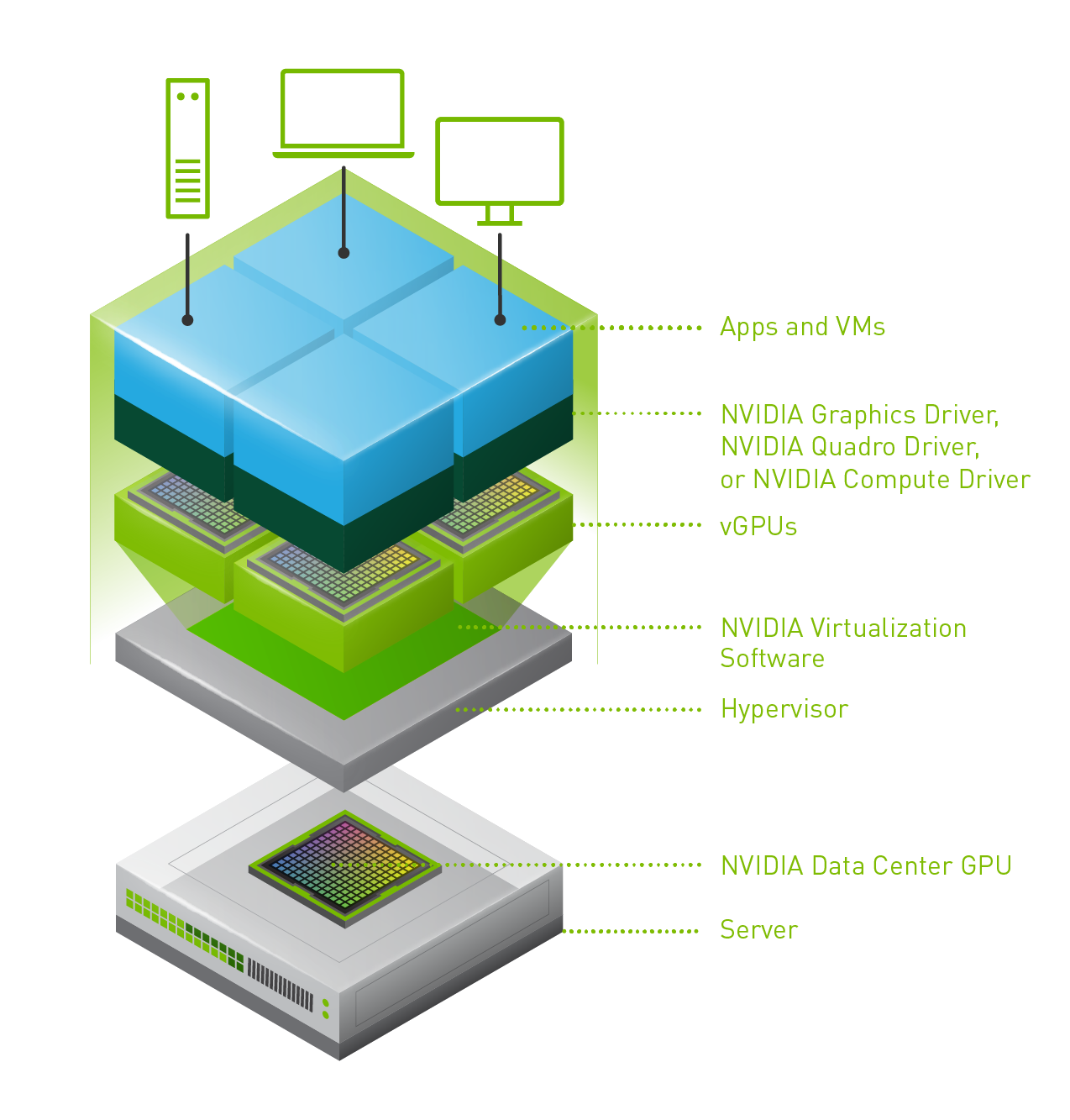 Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in
Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in