I had some questions around this in the past month, so I figured I would share some details around this. As persistent memory (Intel Optane Memory devices for instance) is getting more affordable and readily available more and more customers are looking to use it. Some are already using it for very specific use cases, usually in situations where the OS and the App actually understand the type of device being presented. What does that mean? At VMworld 2018 there was a great session on this topic and I captured the session in a post. Let me copy/paste the important bit for you, which discusses the different modes in which a Persistent Memory device can be presented to a VM.
- vPMEMDisk = exposed to guest as a regular SCSI/NVMe device, VMDKs are stored on PMEM Datastore
- vPMEM = Exposes the NVDIMM device in a “passthrough manner, guest can use it as block device or byte addressable direct access device (DAX), this is the fastest mode and most modern OS’s support this
- vPMEM-aware = This is similar to the mode above, but the difference is that the application understands how to take advantage of vPMEM
But what is the problem with this? What is the impact? Well when you expose a Persistent Memory device to the VM, it is not currently protected by vSphere HA, even though HA may be enabled on your cluster. Say what? Yes indeed, the VM which has the PMEM device presented to it will be disabled for vSphere HA! I had to dig deep to find this documented anywhere, and it is documented in this paper. (Page 47, at the bottom.) So what works and what not? Well if I understand it correctly:
- vSphere HA >> Not supported on vPMEM enabled VMs, regardless of the mode
- vSphere DRS >> Does not consider vPMEM enabled VMs, regardless of the mode
- Migration of VM with vPMEM / vPMEM-aware >> Only possible when migrating to host which has PMEM
- Migration of VM with vPMEMDISK >> Possible to a host without PMEM
Also note, as a result (data is not replicated/mirrored) a failure could potentially lead to loss of data. Although Persistent Memory is a great mechanism to increase performance, it is something that should be taken into consideration when you are thinking about introducing it into your environment.
Oh, if you are wondering why people are taking these risks in terms of availability, Niels Hagoort just posted a blog with a pointer to a new PMEM Perf paper which is worth reading.
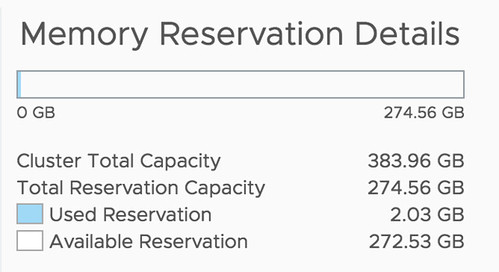
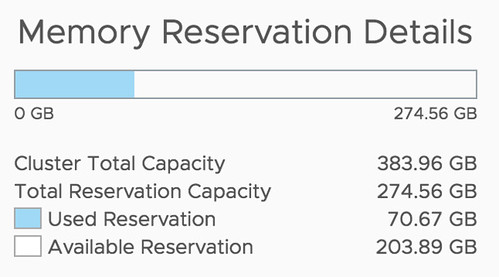

 Another amazing story was
Another amazing story was 

 Norwegian Cruise Line mentioned that they also still use traditional storage, same for ConAgra. It is great that you can do this with vSAN, keep your “old investment”, while building out the new solution. Over time most applications will move over though. One thing that they feel is missing with hyper-converged is the ability to run large memory configurations or large storage capacity configurations. (Duncan: Not sure I entirely agree, limits are very close to non-HCI servers, but I can see what they are referring to.) One thing to note as well from an operational aspect is that certain types of failures are completely different, and handled completely different in an HCI world, that is definitely something to get familiar with. Another thing mentioned was the opportunity of HCI in the Edge, nice small form factor should be possible and should allow running 10-15 VMs. It removes the need for “converged infra” in those locations or traditional storage in general in those environments. Especially now that compute/processing and storage requirements go up at the edge due to IoT and data analytics that happens “locally”.
Norwegian Cruise Line mentioned that they also still use traditional storage, same for ConAgra. It is great that you can do this with vSAN, keep your “old investment”, while building out the new solution. Over time most applications will move over though. One thing that they feel is missing with hyper-converged is the ability to run large memory configurations or large storage capacity configurations. (Duncan: Not sure I entirely agree, limits are very close to non-HCI servers, but I can see what they are referring to.) One thing to note as well from an operational aspect is that certain types of failures are completely different, and handled completely different in an HCI world, that is definitely something to get familiar with. Another thing mentioned was the opportunity of HCI in the Edge, nice small form factor should be possible and should allow running 10-15 VMs. It removes the need for “converged infra” in those locations or traditional storage in general in those environments. Especially now that compute/processing and storage requirements go up at the edge due to IoT and data analytics that happens “locally”.