Almost on a weekly basis, I get a question about unexpected results during the testing of certain failure scenarios. I usually ask first if there’s a diagram that shows the current configuration. The answer is usually no. Then I would ask if they have a failure testing matrix that describes the failures they are introducing, the expected result and the actual result. As you can guess, the answer is usually “euuh a what”? This is where the problem usually begins. The problem usually gets worse when customers try to mimic a certain failure scenario.
What would I do if I had to run through failure scenarios? When I was a consultant we always started with the following:
- Document the environment, including all settings and the “why”
- Create architectural diagrams
- Discuss which types of scenarios would need to be tested
- Create a failure testing matrix that includes the following:
- Type of failure
- How to create the scenario
- Preferably include diagrams per scenario displaying where the failure is introduced
- Expected outcome
- Observed outcome
What I would normally also do is describe in the expected outcome section the theory around what should happen. Maybe I should just give an example of a failure and how I would describe it more or less.
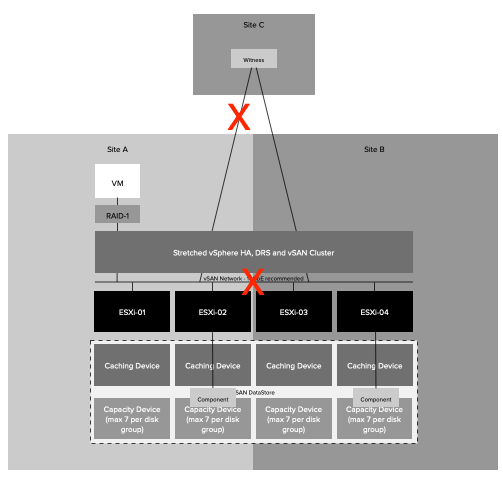
Type Failure: Site Partition
How to: Disable links between Site-A / Site-C and Site-A / Site-B
Expected outcome: The secondary location will bind itself with the witness and will gain ownership over all components. In the preferred location, the quorum is lost, as such all VMs will appear as inaccessible. vSAN will terminate all VMs in the preferred location. This is from an HA perspective however a partition and not an isolation as all hosts in Site-A can still communicate with each other. In the secondary location vSphere HA will notice hosts are missing. It will validate that the VMs that were running are running, or not running. All VMs which are not running, and have accessible components, will be restarted in the secondary location.
Observed outcome: The observed outcome was similar to the expected outcome. It took 1 minute and 30 seconds before all 20 test VMs were restarted.
In the above example, I took a very basic approach and didn’t even go into the level of depth you probably should go. I would, for instance, include the network infrastructure as well and specify exactly where the failure occurs, as this will definitely help during troubleshooting when you need to explain why you are observing a particular unexpected behavior. In many cases what happens is that for instance a site partition is simulated by disabling NICs on a host, or by closing certain firewall ports, or by disabling a VLAN. But can you really compare that to a situation where the fiber between two locations is damaged by excavations? No, you can not compare those two scenarios. Unfortunately this happens very frequently, people (incorrectly) mimic certain failures and end up in a situation where the outcome is different than expected. Usually as a result of the fact that the failure being introduced is also different than the failure that was described. If that is the case, should you still expect the same outcome? You probably should not.
Yes I know, no one likes to write documentation and it is much more fun to test things and see what happens. But without recording the above, a successful implementation is almost impossible to guarantee. What I can guarantee though is that when something fails in production, you most likely will not see the expected behavior when you have not tested the various failure scenarios. So please take the time to document and test, it is probably the most important step of the whole process.