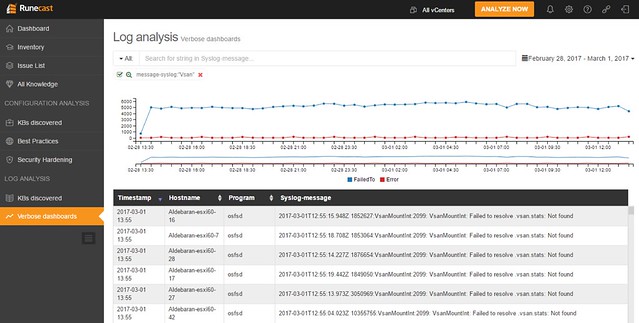
![]() Earlier this week I was on the phone with Rawlinson Rivera, my former VMware/vSAN colleague, and he told me all about the new stuff for Cohesity that was just announced. First of all, congrats with Round C funding. As we’ve all seen, lately it has been mayhem in the storage world. Landing a $90 million round is big. This round was co-led by investors GV (formerly Google Ventures) and Sequoia Capital. Both Cisco Investments and Hewlett Packard Enterprise (HPE) also participated in this round as strategic investors. I am not an analyst, and I am not going to pretend either, lets talk tech.
Earlier this week I was on the phone with Rawlinson Rivera, my former VMware/vSAN colleague, and he told me all about the new stuff for Cohesity that was just announced. First of all, congrats with Round C funding. As we’ve all seen, lately it has been mayhem in the storage world. Landing a $90 million round is big. This round was co-led by investors GV (formerly Google Ventures) and Sequoia Capital. Both Cisco Investments and Hewlett Packard Enterprise (HPE) also participated in this round as strategic investors. I am not an analyst, and I am not going to pretend either, lets talk tech.
Besides the funding round, Cohesity also announced the 4.0 release of their hyper-converged secondary storage platform. Now, let it be clear, I am not a fan of the “hyper-converged” term used here. Why? Well I think this is a converged solution. They combined multiple secondary storage use cases and created a single appliance. Hyper-Converged stands for something in the industry, and usually it means the combination of a hypervisor, storage software and hardware. The hypervisor is missing here. (No I am not saying “hyper” in hyper-converged” stands for hypervisor.) Anyway, lets continue.
In 4.0 some really big functionality is introduced, lets list it out and then discuss each at a time:
- S3 Compatible Object Storage
- Quotas for File Services
- NAS Data Protection
- RBAC for Data Protection
- Folder and Tag based protection
- Erasure Coding
As of 4.0 you can now on the Cohesity platform create S3 Buckets, besides replicating to an S3 bucket you can now also present them! This is fully S3 compatible and can be created through their simple UI. Besides exposing their solution as S3 you can also apply all of their data protection logic to it, so you can have cloud archival / tiering /replication. But also enable encryption, data retention and create snapshots.
Cohesity already offered file services (NFS and SMB), and in this release they are expanding the functionality. The big request from customers was Quotas and that is introduced in 4.0. Along with what they call Write-Once-Read-Many (WORM) capabilities, which refers to data retention in this case (write once, keep forever).
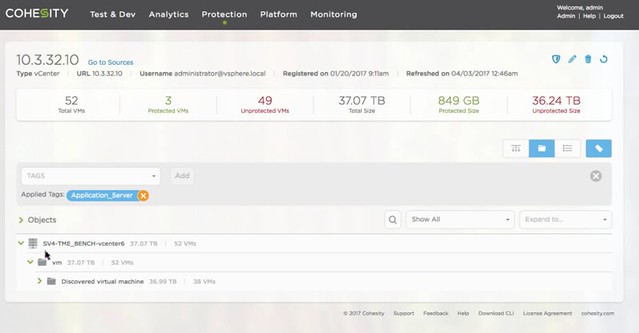
For the Data Protection platform they now offer NAS Data Protection. Basically they can connect to a NAS device and protect everything which is stored on that device by snapping the data and storing it on their platform. So if you have a NetApp filer for instance you can now protect that by offloading the data to the Cohesity platform. For the Data Protection solution they also intro Role Based Access. I think this was one of the big ticket items missing, and with 4.0 they now provide that as well. Last but not last “vCenter Integration”, which means that they can now auto-protect groups of VMs based on the folder they are in or the tag they have provided. Just imagine you have 5000 VMs, you don’t want to associate a backup scheme with each of these, you probably much rather do that for an X number of VMs with a similar SLA at a time. Give them a tag, and associate the tag with the protection scheme (see screenshot). Same for folders, easy.
Last but not least: Erasure Coding. This is not a “front-end” feature, but it is very useful to have. Especially in larger configurations it can safe a lot of precious disk space. Today they have “RAID-1” mechanism more or less, where each block is replicated / mirrored to another host in the cluster. This results in a 100% overhead, in other words: for every 100GB stored you need 200GB capacity. By introducing Erasure Coding they reduce that immediately to 33%. Or in other words, with a 3+1 scheme you get 50% more usable capacity and with a 5+2 (double protection) you get 43% more. Big savings, a lot of extra usable capacity.
Oh and before I forget, besides getting Cisco and HPE as investors you can now also install Cohesity on Cisco kit (there’s a list of approved configurations). HPE took it one step further even, they can sell you a configuration with Cohesity included and pre-installed. Smart move.
All in all, some great new functionality and some great enhancements of the current offering. Good work Cohesity, looking forward to see what is next for you guys.


 After having gone through all holiday email it is now time to go over some of the briefings. The Rubrik briefing caught my eye as it had some big news in there. First of all, they landed Series C, big congrats, especially considering the size, $ 61m is a pretty substantial I must say! Now I am not a financial analyst, so I am not going to spend time talking too much about it, as the introduction of a new version of their solution is more interesting to most of you. So what did Rubrik announce with version 3 aka Firefly.
After having gone through all holiday email it is now time to go over some of the briefings. The Rubrik briefing caught my eye as it had some big news in there. First of all, they landed Series C, big congrats, especially considering the size, $ 61m is a pretty substantial I must say! Now I am not a financial analyst, so I am not going to spend time talking too much about it, as the introduction of a new version of their solution is more interesting to most of you. So what did Rubrik announce with version 3 aka Firefly.