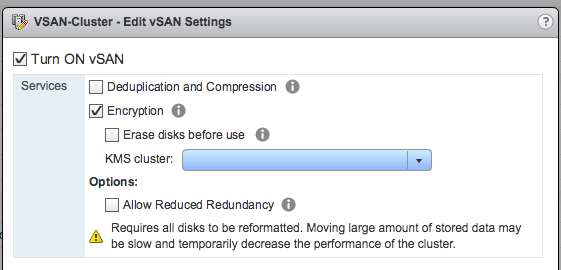
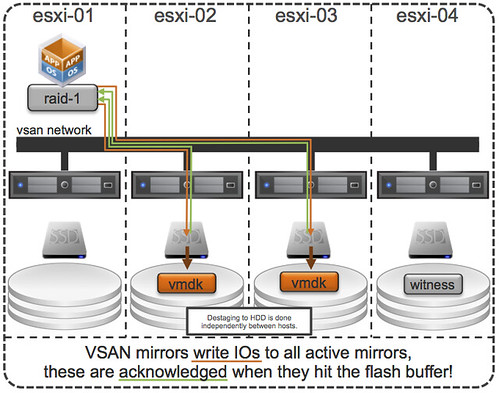
You must have been wondering the same thing after reading the introduction to Virtual SAN. Last week at VMworld I received many questions on this topic, so I figured it was time for a quick blog post on this matter. How do you know where a storage object resides with Virtual SAN when you are striping across multiple disks and have multiple hosts for availability purposes, what about Virtual SAN object location? Yes I know this is difficult to grasp, even with just multiple hosts for resiliency where are things placed? The diagram gives an idea, but that is just from an availability perspective (in this example “failures to tolerate” is set to 1). If you have stripe width configured for 2 disks then imagine what could happen that picture. (Before I published this article, I spotted this excellent primer by Cormac on this exact topic…)

Luckily you can use the vSphere Web Client to figure out where objects are placed:
- Go to your cluster object in the Web Client
- Click “Monitor” and then “Virtual SAN”
- Click “Virtual Disks”
- Click your VM and select the object
The below screenshot depicts what you could potentially see. In this case the Policy was configured with “1 host failure to tolerate” and “disk striping set to 2”. I think the screenshot explains it pretty well, but lets go over it.
The “Type” column shows what it is, is it a “witness” (no data) or a “component” (data). The “Component state” shows you if it is available (active) or not at the moment. The “Host” column shows you on which host it currently resides and the “SSD Disk Name” column shows which SSD is used for read caching and write buffering. If you go to the right you can also see on which magnetic disk the data is stored in the column called “Non-SSD Disk Name”.
Now in our example below you can see that “Hard disk 2” is configured in RAID 1 and then immediately following with RAID 0. The “RAID 1” refers to “availability” in this case aka “component failures” and the “RAID 0” is all about disk striping. As we configured “component failures” to 1 we can see two copies of the data, and we said we would like to stripe across two disks for performance you see a “RAID 0” underneath. Note that this is just an example to illustrate the concept, this is not a best practice or recommendation as that should be based on your requirements! Last but not least we see the “witness”, this is used in case of a failure of a host. If host 10.20.177.19 would fail or be isolated from the network somehow then the witness would be used by host 10.20.177.17 to claim ownership. Makes sense right?

Hope this helps understanding Virtual SAN object location a bit better… When I have the time available, I will try to dive a bit more in to the details of Storage Policy Based Management.
 This seems to becoming a true series, introducing startups… Now in the case of
This seems to becoming a true series, introducing startups… Now in the case of  I have this search column open on twitter with the term “software defined storage”. One thing that kept popping up in the last couple of days was a tweet from various IBM people around how
I have this search column open on twitter with the term “software defined storage”. One thing that kept popping up in the last couple of days was a tweet from various IBM people around how