As vSphere High Availability was completely revamped in 5.0 not a lot of changes have been introduced in 5.1. There are some noteworthy changes though that I figured I would share with you. So what’s cool?
- Ability to set slot size for “Host failures tolerated” through the vSphere Web Client
- Ability to retrieve a list of the virtual machines that span multiple slots
- Support for Guest OS Sleep mode
- Including the Application Monitoring SDK in the Guest SDK (VMware Tools SDK)
- vSphere HA (FDM) VIB is automatically added to Auto-Deploy image profile
- Ability to delay isolation response throught the use of “das.config.fdm.isolationPolicyDelaySec”
Although many of these speak for itself, I will elaborate on why these enhancements are useful and when to use them.
The ability to set slot size for “Host failures tolerated” allows you to manually dictate how many virtual machines you can power-on in your cluster. Many have used advanced settings to achieve more or less the same, but through the UI things are a lot easier I guess.
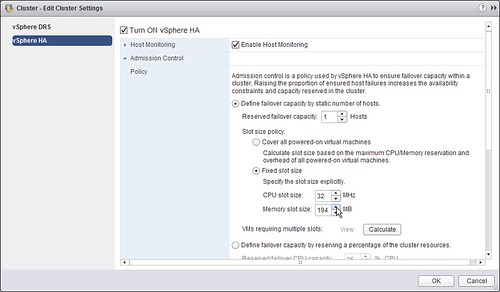
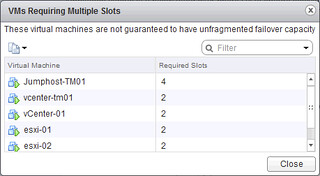
Now if you do this, it could happen that a virtual machine needs multiple slots in order to successfully power-on. That is where the second bullet point comes in to play. In the vSphere Web Client you can now see a list of all the virtual machines that currently span multiple slots.
Support for Guest OS “Sleep Mode” in environments where VM Monitoring is used was added. This was reported by Sudharsan a while back and I addressed it with the HA engineering team. As a result they added in the logic that recognizes the “state” of the virtual machine to avoid unneeded restarts. Thanks Sudharsan for reporting! (I can’t find this in the release notes however)
With 5.0 the Application Monitoring SDK was opened up to the broader audience. It was still a separate installer though. As of vSphere 5.1 the App Monitoring SDK is part of the VMware Tools SDK. This will make your life easier when you use Application Monitoring.
Those running stateless will be happy about the fact that the FDM VIB is now part of the Auto-Deploy image profile. This will avoid the need to manually add it every time you create a new image.
Last but not least, in 5.1 we re-introduce “das.failuredetectiontime”… well not exactly but a similar concept with a different name. This new advanced setting named “das.config.fdm.isolationPolicyDelaySec” will allow you to extend the time it takes before the isolation response is triggered. By default the isolation response is triggered after ~30 seconds with vSphere 5.x. If you have a requirement to increase this then this new advanced setting can be used.