I received this question and figured I would write a quick post about it, as it comes up occasionally. Why does vSphere HA no power-on VMs after a full cluster is brought back online after a full cluster shutdown? In this case, the customer had a power outage, so their hosts and all VMs were powered off, by an administrator cleanly, as a result of the backup power unit running out of power. Unfortunately, this happens more frequently than you would think.
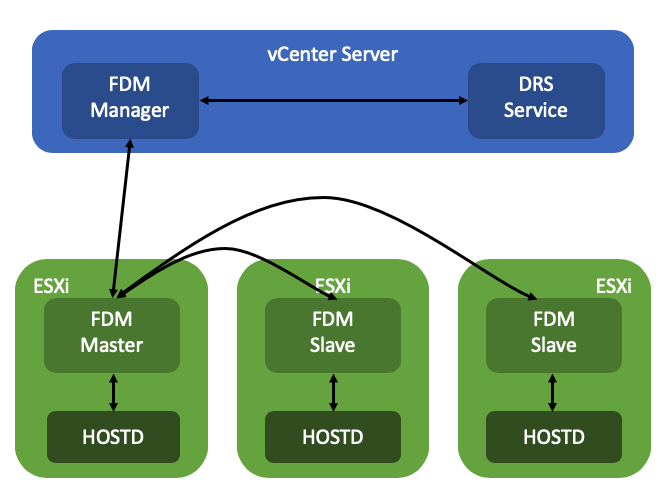
When VMs are powered off by an administrator, or anyone/anything (PowerCLI etc) else which has permissions to power off VMs, then vCenter Server will mark these VMs as “cleanly powered off”. Next, also the state of the VMs is tracked by vSphere HA. So if a host is powered off, HA will know if the VM was powered on, or powered off at the time the host goes missing.
Now, when the host (or hosts) returns for duty, vSphere HA will of course verify what the last known state was of the cluster. It will read the list of all the VMs that were powered on, and it will restart those that were powered on and are configured for HA. It will also look at a VM property called “runtime.cleanPowerOff”, this property indicates if the VM was cleanly powered off by an Admin or a script, or if the VM was for instance powered off by vSphere HA itself. (PDL response etc.) Depending on the value of the property, the VM will, or will not be restarted.
Having said all of that, when you power off a VM manually through the UI, or via a script, then the VM will be marked as being “cleanly powered off”. This means that HA has no reason to restart it, as the powered-off VM is not the result of a host, network, or storage failure.