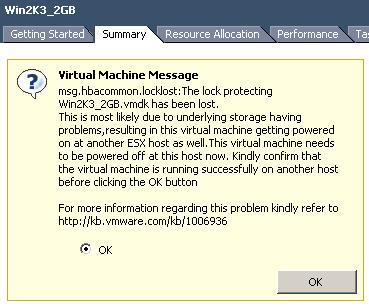
I am working on a special project at the moment. I noticed something I never realized before and wanted to share it with you guys. When a restart of a VM fails VMware HA will retry this.
The amount of VMware HA retries is configurable as of vCenter 2.5 U4 with the advanced option “das.maxvmrestartcount”. The default value is 5. Pre vCenter 2.5 U4 HA would keep retrying forever which could lead to serious problems as described in KB article 1009625 where multiple virtual machines would be registered on multiple hosts simultaneously leading to a confusing and inconsistent state.(http://kb.vmware.com/kb/1009625)
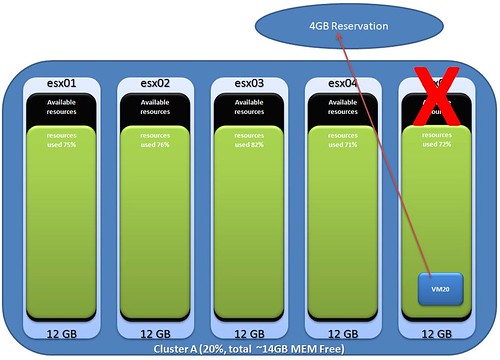
Important to note is that HA will try to start the virtual machine on each of the hosts in the affected cluster, if this is unsuccessful the restart count will be increased by 1. In other words, if a cluster contains 32 hosts HA will try to start the virtual machine on all hosts and count it as a single try. Something I definitely never realized and something that definitely is worth knowing.