<Update>I asked William Lam if he could write a script to detect this problem and possibly even mitigate it. William worked on it over the weekend and just posted the result! Head over to his blog for the script! Thanks William for cranking it out this quick! For those who prefer PowerCLI… Alan Renouf just posted his version of the script! Both scripts provide the same functionality though!</Update>
A couple of weeks back Craig S. commented on my blog about an issue he ran in to in his environment. He was using a Distributed vSwitch and testing certain failure scenarios. One of those scenarios was failing a host in the middle of a Storage vMotion process of a virtual machine. After he had failed the host he expected HA to restart the virtual machine but this did not happen unfortunately. He also could not get the virtual machine up and running again himself. Unfortunately in this case it was the vCenter Server that was used to test this scenario with, which brought him in to a difficult position. This was the exact error:
Operation failed, diagnostics report: Failed to open file /vmfs/volumes/4f64a5db-b539e3b0-afed-001b214558a5/.dvsData/71 9e 0d 50 c8 40 d1 c3-87 03 7b ac f8 0b 6a 2d/1241 Status (bad0003)= Not found
Today I spotted a KB article which describes this scenario, the error mentioned in this KB articles reveals a bit more what is going wrong I guess:
2012-01-18T16:23:17.827Z [FFE3BB90 error 'Execution' opID=host-6627:6-0] [FailoverAction::ReconfigureCompletionCallback] Failed to load Dv ports for /vmfs/volumes/UUID/VM/VM.vmx: N3Vim5Fault19PlatformConfigFault9ExceptionE(vim.fault.PlatformConfigFault) 2012-01-18T16:23:17.827Z [FFE3BB90 verbose 'Execution' opID=host-6627:6-0] [FailoverAction::ErrorHandler] Got fault while failing over vm. /vmfs/volumes/UUID/VM/VM.vmx: [N3Vim5Fault19PlatformConfigFaultE:0xecba148] (state = reconfiguring)
It seems that at the time of fail-over the “dvport” information cannot be loaded by HA as after the Storage vMotion process the dvport file is not created on the destination datastore. Now please note that this applies to all VMs attached to a VDS which have been Storage vMotioned using vCenter 5.0. However the problem will only be witnessed during time of HA fail-over.
This dvport info is what I mentioned in my “digging deeper into the VDS construct” article. I already mentioned there that this is what HA uses to reconnect the virtual machine to the Distributed vSwitch… And when files are moving around you can imagine it is difficult to power-on a virtual machine.
I reproduced the problem as shown in the following screenshot. The VM has port 139 assigned by the VDS, but on the datastore there is only a dvport file for 106. This is what happened after I simply Storage vMotioned the VM from Datastore-A to Datastore-B.

For now, if you are using a Distributed vSwitch and running a virtual vCenter Server and have Storage DRS enabled… I would recommend disable Storage DRS for vCenter specifically, just to avoid getting in these scenarios.
Go to Datastore & Datastore Clusters view, Edit properties on Datastore Cluster and change automation level:
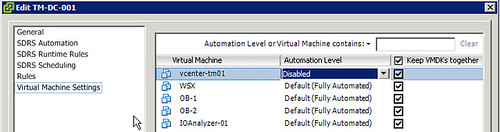
The problem itself can be mitigated, as described by Michael Webster here, by simply selecting a different dvPortgroup or vSwitch for the virtual machine. After the reconfiguration has completed you can select the original portgroup again, this will recreate the dvport info on the datastore.