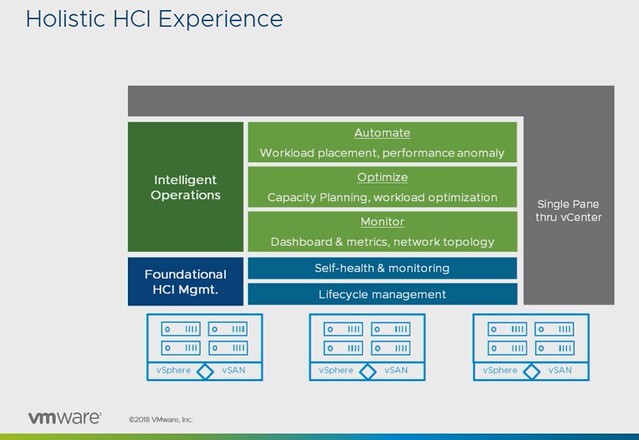
 This session by Christian Dickmann and Junchi Zhang is usually one of my favorites in the HCI track, mainly because they show a lot of demos and in many cases show you what ends up being part of the product in 6-12 months. The session revolved all around management, or as they called it in the session “providing a holistic HCI experience”.
This session by Christian Dickmann and Junchi Zhang is usually one of my favorites in the HCI track, mainly because they show a lot of demos and in many cases show you what ends up being part of the product in 6-12 months. The session revolved all around management, or as they called it in the session “providing a holistic HCI experience”.
After a short intro Christian showed a demo around what we currently have around the installation of the vCenter Server Appliance and how we can deploy that to a vSAN Datastore, followed by the Quickstart functionality. I posted a demo of Quickstart earlier this week, let me post it here as well so you have an idea of what it is/does.
In the next demo, Christian showed how you can upgrade the firmware of a disk controller using Update Manager. Pretty cool, but afaik still limited to a single disk controller, hopefully, more will follow soon. But more importantly, after that demo ended he started talking about “Guided SDDC Update & Patching”, and this is where it got extremely interesting. We all know that it isn’t easy to upgrade a full stack, and what Christian was describing would be doing exactly that. Do you have Horizon? Sure, we will upgrade that as well when we do vCenter / ESXi / vSAN etc. Do you have NSX as part of your infra? Sure, that is also something we will take into account and upgrade it when required. This would also include firmware upgrades for NICs, disk controllers etc.
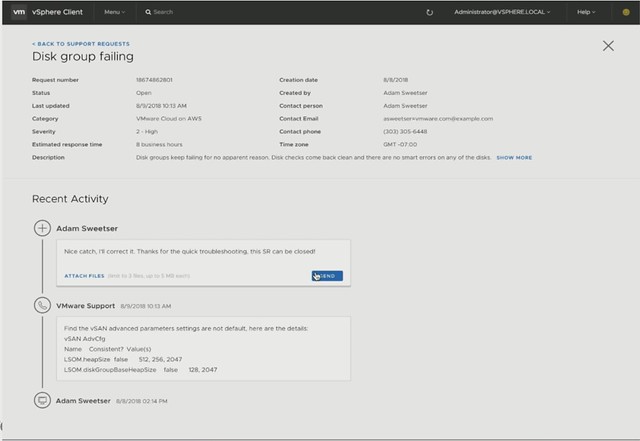
Next Christian showed the Support Insight feature, which is enabled through the Customer Experience Improvement Program. His demo then showed how to create a support request right from the H5 Client. The process shows that the solution understands the situation and files the ticket. Then it shows what the support team sees. It allows the support team to quickly analyze the environment, and more importantly inform the customer about the solution. No need to upload log bundles or anything like that, that all happens automatically. That’s not where it stop, you will be informed in the H5 client about the solution as well. Cool right?
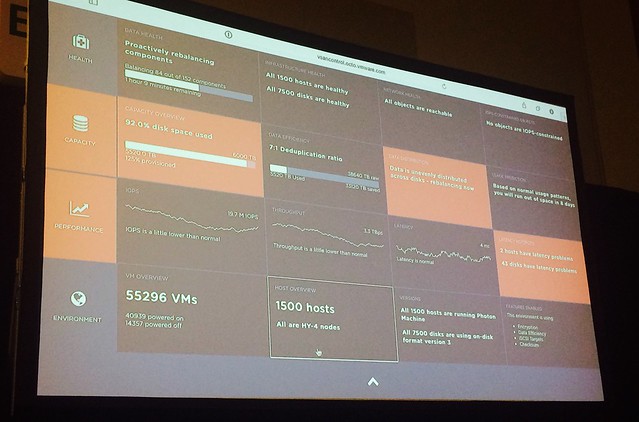
Next Junchi was up and he discussed Capacity Management first. As he mentioned it appears to be difficult for people to understand the capacity graphs provided by vSAN. Junchi proposes a new model where it is clear instantly what the usable space is and by what current capacity is being consumed. Not just on a cluster level, but also at a VM level. This should also include what-if scenarios for usage projection. Junchi then quickly demoed the tools available that help with sizing and scaling.
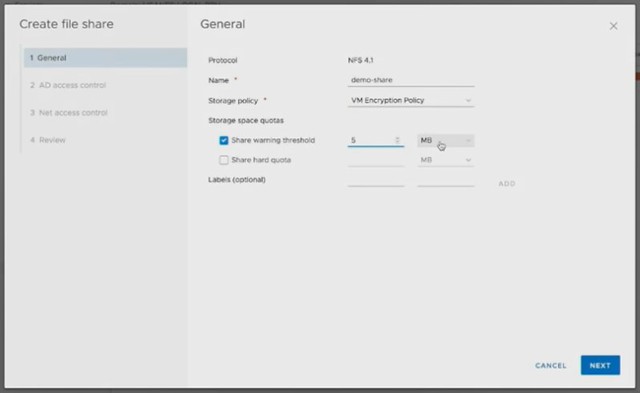
Next Native File Services was briefly discussed, Data Protection and Cloud Native Storage. What does the management of these services look like? The file services demo that Junchi showed was really slick. Fill out IP details and Domain details and have File Services running in a minute or two natively on vSAN. Only thing you would need to do is create file shares and give folks access to the file shares. Also, monitoring will go through the familiar screens like the health check etc.
Last but not least Junchi discusses the integration with vRealize Automation on-premises and SaaS-based, a very cool demo showing how Cloud Assembly (but also vRA) will be able to leverage storage policies and new applications are provided using blueprints which have these policies associated with them.
That was it, if you like to know more, watch the session online, or attend it in EMEA!