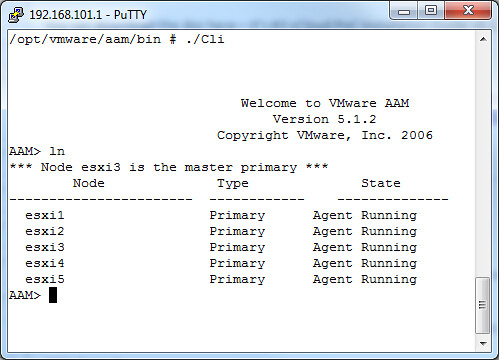
I was just playing around with the HA Cli and noticed that when you give an “ln” (listNodes) that the failover coordinator (aka master primary) is also listed. I have never noticed this before, but don’t have a pre-vSphere 4.1 environment to test it on to see if this existed before 4.1. If you want to test it in your own environment just simply run “/opt/vmware/aam/bin/Cli” and give the “ln” command as shown in the screenshot below:
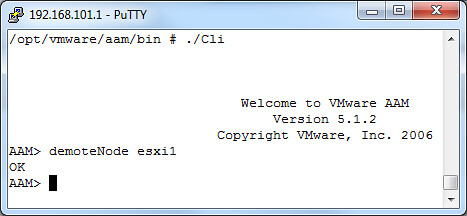
I also tested demoting of a node just for fun. In this case I demoted the node “esxi1” from primary to secondary:
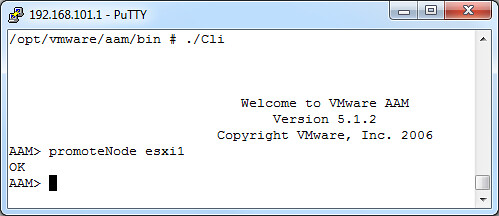
And of course I promoted it again to primary:
** Disclaimer: This article contains references to the words master and/or slave. I recognize these as exclusionary words. The words are used in this article for consistency because it’s currently the words that appear in the software, in the UI, and in the log files. When the software is updated to remove the words, this article will be updated to be in alignment. **