I just wanted to write a couple of lines about Resource Pools. During most engagements I see environments where Resource Pools have been implemented together with shares. These Resource Pools are usually labeled “Low”, “Normal” and “High” with the shares set respectively. This is the traditional example being used during the VMware vSphere / VI3 course. Why am I writing about this you might ask yourself as many have successfully deployed environments with resource pools.
The problem I have with default implementations is the following:
Sibling resource pools share resources according to their relative share values.
Please read this line a couple of times. And then look at the following diagram:
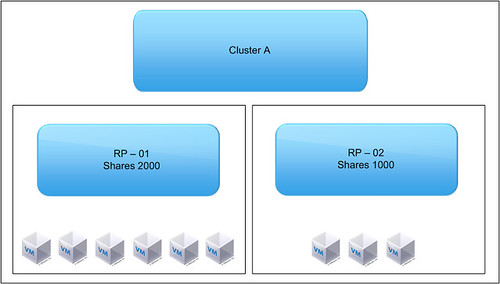
What’s the issue here?
RP – 01 -> 2000 Shares -> 6 VMs
RP – 02 -> 1000 Shares -> 3 VMs
So what happens if these 9 VMs start fight for resources. Most people assume that the 6 VMs, which are part of RP-01, get more resources than the 3 VMs. Especially when you name them “Low” and “Normal” you expect the VMs which are part of “Low” to get a “lower” amount of resources than those which belong to the “Normal” resource pool. But is this the case?
No it is not. Sibling resource pools share resources according to their relative share values. In other words, resources are divided on a resource pool level, not on a per VM level. So what happens here? RP-01 will get 66% of the resources and RP-02 will get 33% of the resources. But because RP-01 contains twice as many VMs as RP-02 this will not make a difference when all VMs are fighting over resources… Each VM will roughly get the same amount of processor time. This is something that not many people take into account when designing an infrastructure or when implementing resource pools.