*** These formulas apply only to ESX/ESXi 4.0 and vCenter Server 4.0. They are subject to change ***
Last week I mentioned which metrics DRS used for load balancing VMs across a cluster. Of course the obvious question was when the DRS Deepdive would be posted. I must admit I’m not an expert on this topic as like most of you I always took for granted that it worked out of the box. I can’t remember that there ever was the need to troubleshoot DRS related problems, or better said I don’t think I’ve ever seen an issue which was DRS related.
This article will focus on two primary DRS functions:
- Load balancing VMs due to imbalanced Cluster
- VM Placement when booting
I will not be focusing on Resource Pools at all as I feel that there are already more than enough articles which explain these. The Resource Management Guide also contains a wealth of info on resource pools and this should be your starting place!
Load Balancing
First of all VMware DRS evaluates your cluster every 5 minutes. If there’s an imbalance in load it will reorganize your cluster, with the help of VMotion, to create an evenly balanced cluster again. So how does it detect an imbalanced Cluster? First of all let’s start with a screenshot:
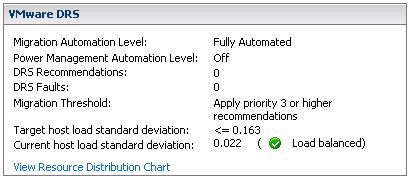
fig 1
There are three major elements here:
- Migration Threshold
- Target host load standard deviation
- Current host load standard deviation
Keep in mind that when you change the “Migration Threshold” the value of the “Target host load standard deviation” will also change. In other words the Migration Threshold dictates how much the cluster can be “imbalanced”. There also appears to be a direct relationship between the amount of hosts in a cluster and the “Target host load standard deviation”. However, I haven’t found any reference to support this observation. (Two host cluster with threshold set to three has a THLSD of 0.2, a three host cluster has a THLSD of 0.163.) As said every 5 minutes DRS will calculate the sum of the resource entitlements of all virtual machines on a single host and divides that number by the capacity of the host:
sum(expected VM loads) / (capacity of host)
The result of all hosts will then be used to compute an average and the standard deviation. (Which effectively is the “Current host load standard deviation” you see in the screenshot(fig1).) I’m not going to explain what a standard deviation is as it’s explained extensively on Wiki.
If the environment is imbalanced and the Current host load standard deviation exceeds the value of the “Target host load standard deviation” DRS will either recommend migrations or perform migrations depending on the chosen setting.
The question left is how does DRS decide which VM or set of VMs it will VMotion…
The following procedure is used to form a set of recommendations to correct the imbalanced cluster:
While (load imbalance metric > threshold) {
move = GetBestMove();
If no good migration is found:
stop;
Else:
Add move to the list of recommendations;
Update cluster to the state after the move is added;
}
Step by step in plain English:
While the cluster is imbalanced (Current host load standard deviation > Target host load standard deviation) select a VM to migrate based on specific criteria and simulate a move and recompute the “Current host load standard deviation” and add to the migration recommendation list. If the cluster is still imbalanced(Current host load standard deviation > Target host load standard deviation) repeat procedure.
Now how does DRS select the best VM to move? DRS uses the following procedure:
GetBestMove() {
For each VM v:
For each host h that is not Source Host:
If h is lightly loaded compared to Source Host:
If Cost Benefit and Risk Analysis accepted
simulate move v to h
measure new cluster-wide load imbalance metric as g
Return move v that gives least cluster-wide imbalance g.
}
Again in plain English:
For each VM check if a VMotion to each of the hosts which are less utilized than source host would result in a less imbalanced cluster and meets the Cost Benefit and Risk Analysis criteria. Compare the outcome of all tried combinations(VM<->Host) and return the VMotion that results in the least cluster imbalance.
This should result in a migration which gives the most improvement in terms of cluster balance, in other words: most bang for the buck! This is the reason why usually the larger VMs are moved as they will most likely decrease “Current host load standard deviation” the most. If it’s not enough to balance the cluster within the given threshold the “GetBestMove” gets executed again by the procedure which is used to form a set of recommendations.
Now the next question would be what does “Cost Benefit” and “Risk Analysis” consist of and why are we doing this?
First of all we want to avoid a constant stream of VMotions and this will be done by weighing costs vs benefits vs risks. These consists of:
- Cost benefit
Cost: CPU reserved during migration on t he target host
Cost: Memory consumed by shadow VM during VMotion on the target host
Cost: VM “downtime” during the VMotion
Benefit: More resources available on source host due to migration
Benefit: More resources for migrated VM as it moves to a less utilized host
Benefit: Cluster Balance - Risk Analysis
Stable vs unstable workload of the VM (historic info used)
Based on these consideration a cost-benefit-risk metric will be calculated and if this has an acceptable value the VM will be consider for migration.
Every migration recommendation will get a priority rating. This priority rating is based on the Current host load standard deviation. The actual algorithm being used to determine this is described in this KB article. I needed to read the article 134 times before I actually understood what they were trying to explain so I will use an example based on the info shown in the screenshot(fig1). Just to make sure it’s absolutely clear, LoadImbalanceMetric is the Current host load standard deviation value and ceil is basically a “round up”. The formula mentioned in the KB article followed by an example based on the screenshot(fig1):
6 - ceil(LoadImbalanceMetric / 0.1 * sqrt(NumberOfHostsInCluster))
6 - ceil(0.022 / 0.1 * sqrt(3))
This would result in a priority level of 5 for the migration recommendation if the cluster was imbalanced.
VM Placement
The placement of a VM when being powered on is as you know part of DRS. DRS analyzes the cluster based on the algorithm described in “Load Balancing”. The question of course is for the VM which is being powered on what kind of values does DRS work with? Here’s the catch, DRS assumes that 100% of the provisioned resources for this VM will be used. DRS does not take limits or reservations into account. Just like HA, DRS has got “admission control”. If DRS can’t guarantee the full 100% of the resources provisioned for this VM can be used it will VMotion VMs away so that it can power on this single VM. If however there are not enough resources available it will not power on this VM.
That’s it for now… Like I said earlier, if you have more in-depth details feel free to chip in as this is a grey area for most people.