Last week a blog post was published on VMware’s Virtual Blocks blog on the topic of Ransomware Recovery. Some of the numbers shared were astonishing and hard to contextualize even. Global damages caused by ransomware for instance are estimated to exceed 42 billion dollars in 2024, and this is expected to be doubling every year. Also, 66% of all enterprises were hit by ransomware, of which 96% did not regain full access to their data.
Last week a blog post was published on VMware’s Virtual Blocks blog on the topic of Ransomware Recovery. Some of the numbers shared were astonishing and hard to contextualize even. Global damages caused by ransomware for instance are estimated to exceed 42 billion dollars in 2024, and this is expected to be doubling every year. Also, 66% of all enterprises were hit by ransomware, of which 96% did not regain full access to their data.
Now, it explicitly mentions “enterprises”, but this does not mean that only enterprise organizations are prone to ransomware attacks. Ransomware attacks do not discriminate, every company, non-profit, and even individuals are at risk if you ask me. As a smart person once said, data is the new oil, and it seems that everyone is drilling for it, including trespassers who don’t own the land! Of course, depending on the type of organization, solutions and services are available to mitigate the risks of losing access to your company’s most valuable asset, data.
VMware, and many other vendors, have various solutions (and services) to protect your data center, your workloads, and essentially your data. But what do you do if you are breached? How do you recover? How fast can you recover, and how fast do you need to recover? How far back do you need to go, and are you allowed to go? Some of you may wonder why I ask these questions, well that has everything to do with the numbers shared at the start of this blog. Unfortunately, today, when organizations are breached malicious code is often only detected after a significant amount of time. Giving the attacker time to collect information about the environment, spread itself throughout the environment, activate the attack, and ultimately request the ransom.
This is when you, the administrator, the consultant, and the cloud admin, will get those questions. How fast can you recover? How far back do we need to go? Where do we recover to? And what about your data? All fair questions, but these shouldn’t be asked after an attack has occurred and ransom is demanded. These are questions we all need to ask constantly, and we should be aligning our Ransomware Recovery strategy with the answers to those questions.
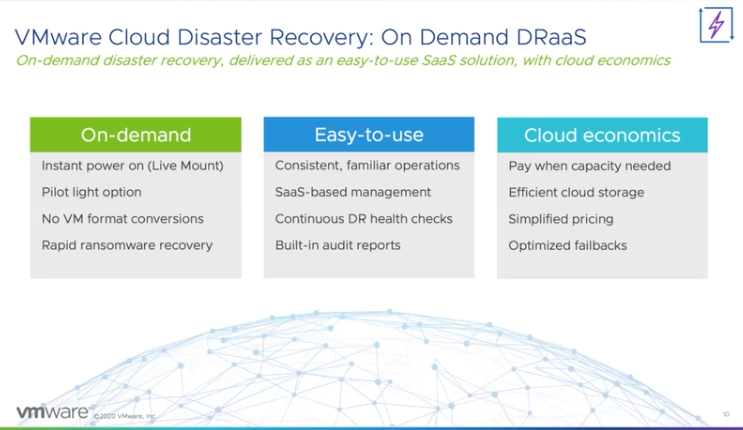
Now, it is fair to say that I am probably somewhat biased, but it is also fair to say that I am as Dutch as it gets and I wouldn’t be writing this blog if I did not believe in this service. VMware’s Ransomware Recovery as a Service, which is part of VMware Cloud Disaster Recovery, provides a unique solution in my humble opinion. First, the service provided can just simply start as a cloud storage service to which you replicate your workloads, without needing to run a full (small but still) software-defined datacenter. This is especially useful for those organizations that can afford to take ~3hrs to spin up an SDDC when there’s a need to recover (or test the process). However, it is also possible to have an SDDC ready for recovery at all times, which will reduce the recovery time objective significantly.

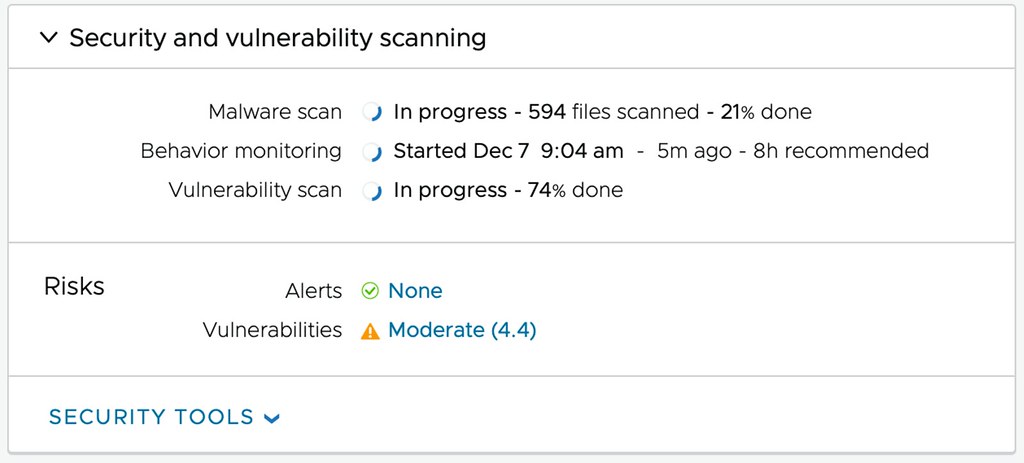
Of course, VMware provides the ability to protect multiple environments, many different workloads, and many point-in-time copies (snapshots). But it also enables you to verify your recovery point (snapshot) in a fully isolated environment. What you will appreciate is that the solution will actually not only isolate the workloads, but on top of that also provide you insights at various levels about the probability of the snapshot being infected. First of all, while going through the recovery process, entropy and change rate are shown which provides insights of when potentially the environment was infected. (Or ransomware was activated for that matter.)
But maybe even more important, through the use of NSX and VMware’s Next Generation Anti-Virus software, a recovery point can be safely tried. A quarantined environment is instantiated and the recovery point can be scanned for vulnerabilities and threats, and an analysis of the workloads to be recovered can be provided, as shown below. This simplifies the recovery and validation process immensely, as it removes the need for many of the manual steps usually involved in this process. Of course, as part of the recovery process, the advanced runbook capabilities of VMware Cloud Disaster Recovery are utilized, enabling the recovery of a full data center, or simply a select group of VMs, by running a recovery plan. This recovery plan includes the order in which workloads need to be powered on and restored, but can also include IP customization, DNS registration, and more.
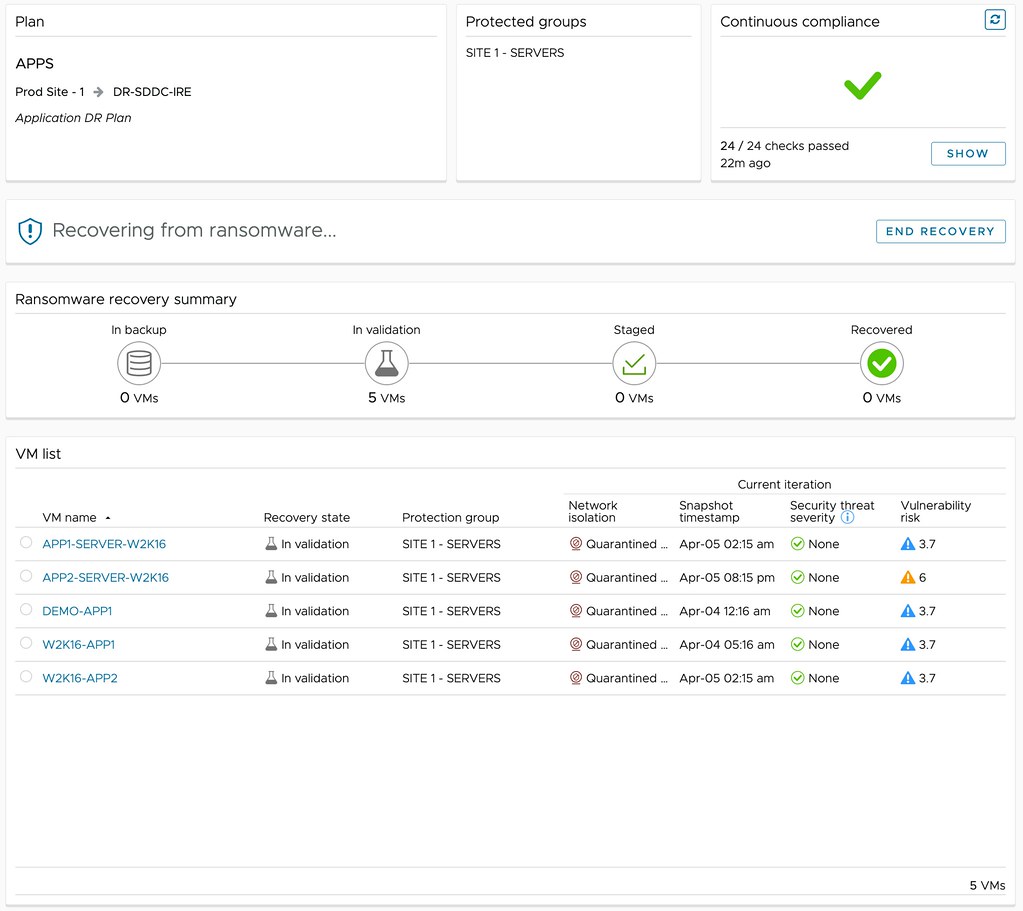
Depending on the outcome of the analysis, you can then determine what to do with the snapshot. Is the data not compromised? Are the workloads not infected? Are there any known vulnerabilities that we would need to mitigate first? If data is compromised, or the environment is infected in any shape or form, you can simply disregard the snapshot and clean the environment. Rinse and repeat until you find that recovery point that is not compromised! If there are known vulnerabilities, and the environment is clean, you can mitigate those and complete the recovery. Ultimately resulting in full access to your company’s most valuable asset, data.