I’ve been working on an overhauled version of the HA Deepdive Page. I’ve been adding “basic design principles” which hopefully you find useful.Here’s an example of what they look like:
Basic design principle: For iSCSI the preferred isolation response is always “Power off” to avoid a possible split brain scenario.
Another bit I’ve added is the following:
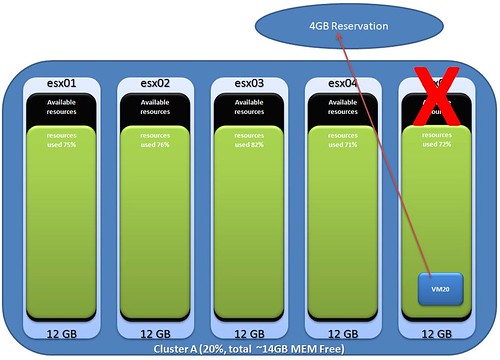
Please keep in mind that if you have an unbalanced cluster(host with different CPU or memory resources) your percentage is equal or preferably larger than the percentage of resources provided by the largest host. This way you ensure that all virtual machines residing on this host can be restarted in case of a host failure. Another thing to keep in mind is as there are no slots which HA uses resources might be fragmented throughout the cluster. Make sure you have at least a host with enough available capacity to boot the largest VM (reservation CPU/MEM). Also make sure you select the highest restart priority for this VM(of course depending on the SLA) to ensure it will be able to boot.)
What I’m discussing here is the impact of selecting a “Percentage” instead of the amount of host failures for your HA cluster. Although you might have enough spare resources left on your total cluster, the reservation of a single VM might cause it not to boot when resources are fragmented. Make sure these VMs are the first to boot up when disaster strikes by using restart priorities.
I created a diagram which makes it more obvious I think. So you have 5 hosts, each with roughly 76% memory usage. A host fails and all VMs will need to failover. One of those VMs has a 4GB memory reservation, as you can imagine failing over this particular VM will be impossible.