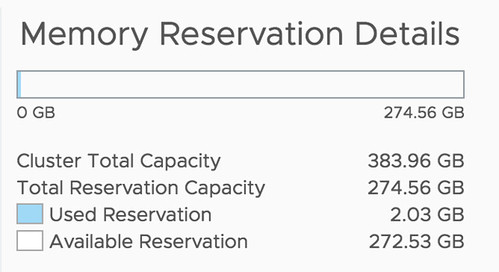
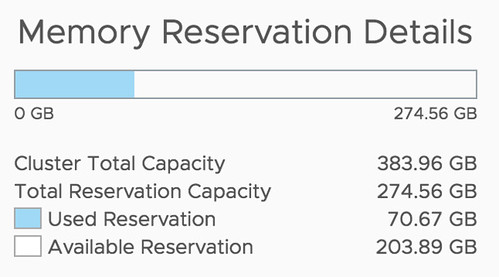
This week I received some questions on the topic of HA Admission Control. There was a customer that had a cluster configured with the dedicated failover host admission control policy and they had no clue why. This cluster had been around for a while and it was configured by a different admin, who had left the company. As they upgraded the environment they noticed that it was configured with an admission control policy they never used anywhere else, but why? Well, of course, the design was documented, but no one documented the design decision so that didn’t really help. So they came to me and asked what it exactly did and why you would use it.
Let’s start with that last question, why would you use it? Well normally you would not, you should not. Forget about it, well unless you have a specific use case and I will discuss that later. What does it do?
When you designate hosts as failover hosts, they will not participate in DRS and you will not be able to run VMs on these hosts! Not even in a two-host cluster when placing one of the two in maintenance. These hosts are literally reserved for failover situations. HA will attempt to use these hosts first to failover the VMs. If, for whatever reason, this is unsuccessful, it will attempt a failover on any of the other hosts in the cluster. For example, in a when two hosts would fail, including the hosts designated as failover hosts, HA will still try to restart the impacted VMs on the host that is left. Although this host was not a designated failover host, HA will use it to limit downtime.
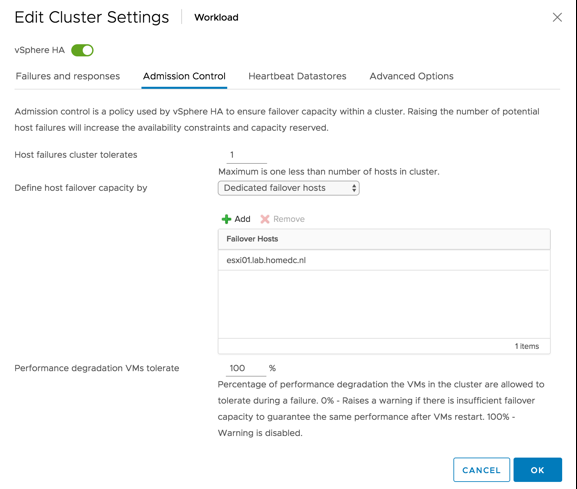
As can be seen above, you select the correct admission control policy and then add the hosts. As mentioned earlier, the hosts added to this list will not be considered by DRS at all. This means that the resources go wasted unless there’s a failure. So why would you use it?
- If you need to know where a VM runs all the time, this admission control policy dictates where the restart happens.
- There is no resource fragmentation, as a full host (or multiple) worth of resources will be available to restart VMs on, instead of 1 host worth of resources across multiple hosts.
In some cases, the above may be very useful, for instance knowing where a VM is all the time could be required for regulatory compliance, or could be needed for licensing reasons when you run Oracle for instance.