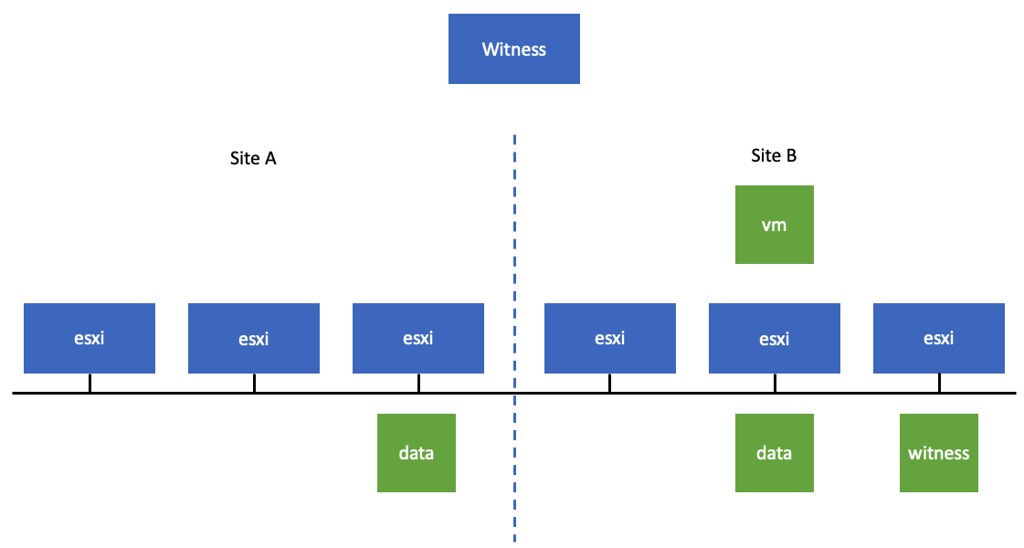
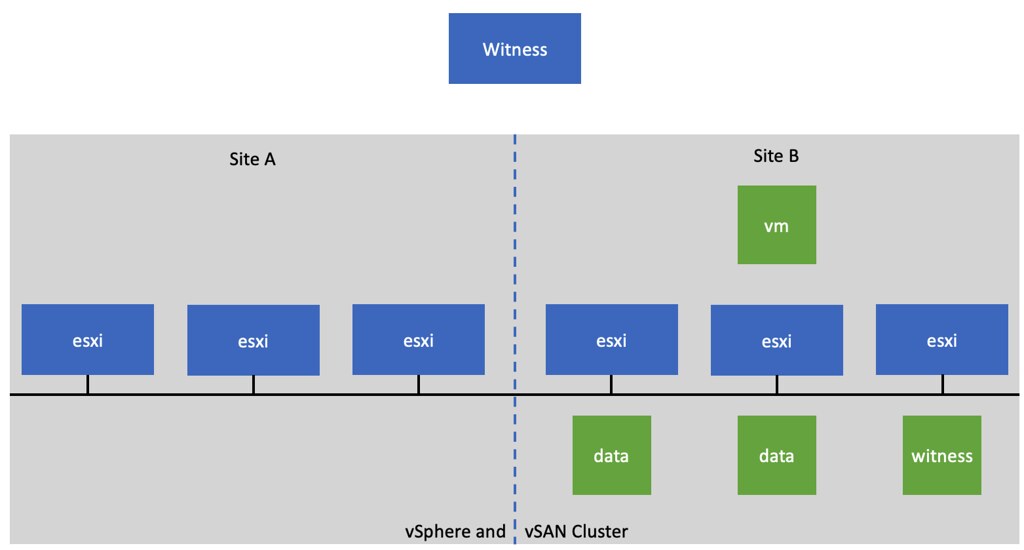
Sometimes unfortunately there are situations where a vendor’s ESXi image includes a disk controller driver that is not on the vSAN HCL/VCG (VMware Compatibility Guide). Typically it is a new version of the driver which is supported for vSphere, but not yet for vSAN. In that situation, what should you do? So far there are two approaches I have seen customers take:
- Keep running with the included driver and wait for the driver to be supported and listed on the vSAN HCL/VCG
- Downgrade the driver to the version which is listed on the vSAN HCL/VCG
Personally, I feel that option 2 is the correct way to go. The reason is simple, vSphere and vSAN have different certification requirements for disk controllers and the vSAN certification criteria are just more stringent than vSphere’s. Hence, sometimes you see vSAN skipping certain versions of drivers, this usually means a version did not pass the tests. Now, of course, you could keep running the driver and wait for it to appear on the vSAN HCL/VC. If however, you hit a problem, VMware Support will always ask you first to bring the environment to a fully supported state. Personally, I would not want the extra stress while troubleshooting. But that is my experience and preference. Just to be clear, from a VMware stance, there’s only one option, and that is option two, downgrade to the supported version!