I’ve seen this question popping up regularly. Which policy setting (“site disaster tolerance” and “failures to tolerate”) should I use when I do not want to stretch my VMs? Well, that is actually pretty straight forward, in my opinion, you really only have two options you should ever use:
- None – Keep data on preferred (stretched cluster)
- None – Keep data on non-preferred (stretched cluster)
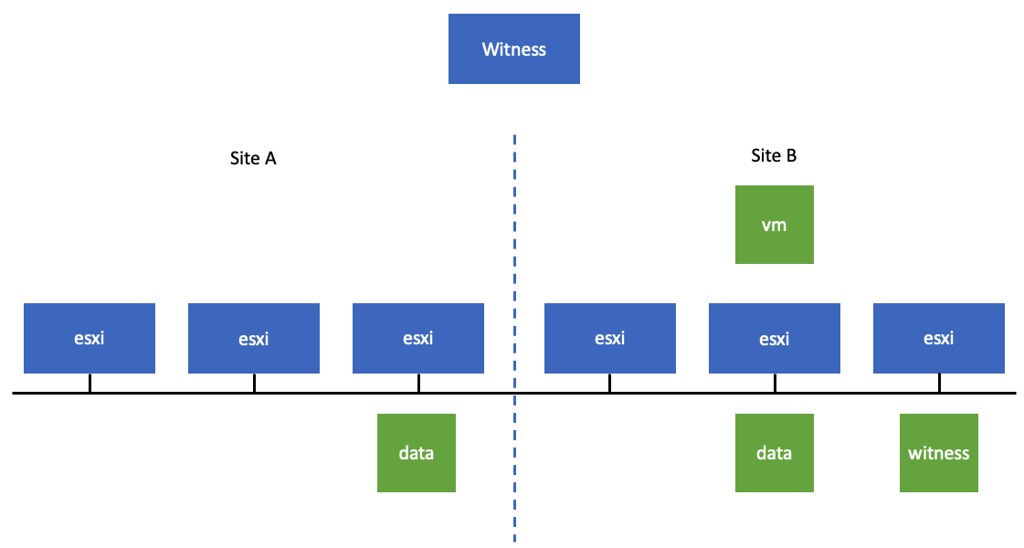
Yes, there is another option. This option is called “None – Stretched Cluster” and then there’s also “None – Standard Cluster”. Why should you not use these? Well, let’s start with “None – Stretched Cluster”. In the case of “None – Stretched Cluster”, vSAN will per object decide where to place it. As you hopefully know, a VM consists of multiple objects. As you can imagine, this is not optimal from a performance point of view, as you could end up having a VMDK being placed in Site A and a VMDK being placed in Site B. Which means it would read and write from both locations from a storage point of view, while the VM would be sitting in a single location from a compute point of view. It is also not very optimal from an availability stance, as it would mean that when the intersite link is unavailable, some objects of the VM would also become inaccessible. Not a great situation. What would it look like? Well, potentially something like the below diagram!
Then there’s “None – Standard Cluster”, what happens in this case? When you use “None – Standard Cluster” with “RAID-1”, what is going to happen is that the VM is configured with FTT=1 and RAID-1, but in a stretched cluster “FTT” does not exist, and FTT automatically will become PFTT. This means that the VM is going to be mirrored across locations, and you will have SFTT=0, which means no resiliency locally. It is the same as “Dual Site Mirroring”+”No Data Redundancy”!
In summary, if you ask me, “none – standard cluster” and “none – stretched cluster” should not be used in a stretched cluster.