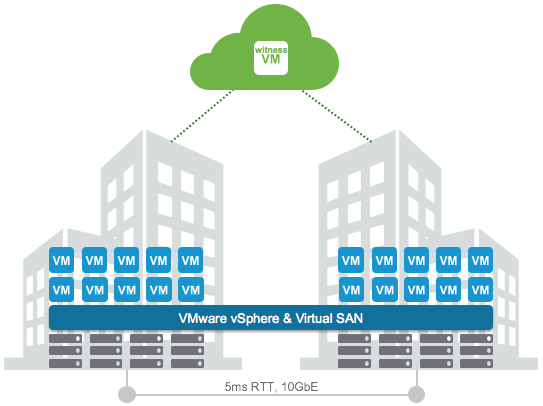
A question was asked internally if you can still provision VMs when a site has failed in a VSAN stretched cluster environment. In a regular VSAN environment when you don’t have sufficient fault domains you cannot provision new VMs, unless you explicitly enable Force Provisioning, which most people do not have enabled. In a VSAN stretched cluster environment this behaviour is different. In my case I tested what would happen if the witness appliance would be gone. I had already created a VM before I failed the witness appliance, and I powered it on after I failed the witness, just to see if that worked. Well that worked, great, and if you look at the VM at a component level you can see that the witness component is missing.

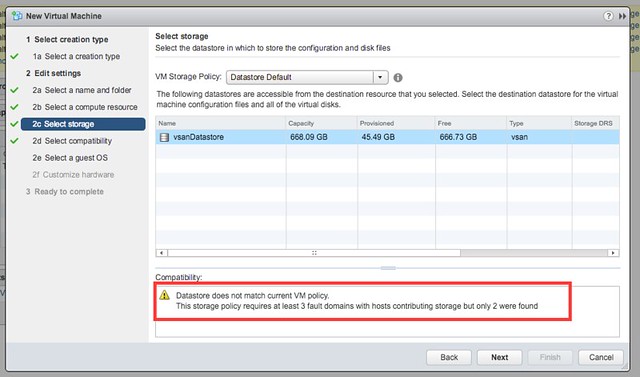
Next test would be to create a new VM while the Witness Appliance is down. That also worked, although I am notified by vCenter during the provisioning process that there are less fault domain than expected as shown in the below screenshot. This is the difference with a normal VSAN environment, here we actually do allow you to provision new workloads, mainly because the site could be down for a longer period of time.
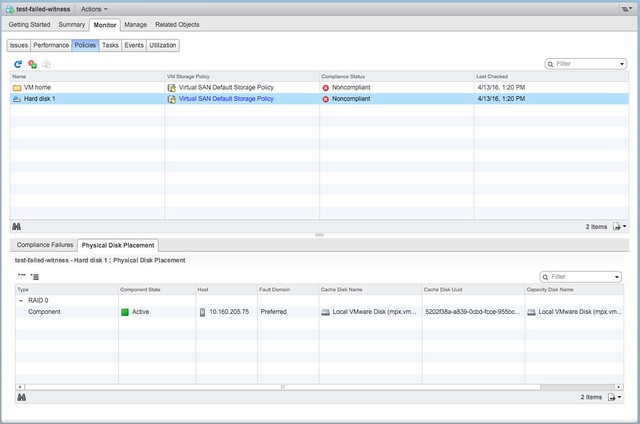
Now next step would be to power on the just created VM and then look at the components. The power on works without any issues and as shown below, the VM is created in the Preferred site with a single component. As soon though as the Witness recovers the the remaining components are created and synced.
Good to see that provisioning and power-on actually does work and that behaviour for this specific use-case was changed. If you want to know more about VSAN stretched clusters, there are a bunch of articles on it to be found here. And there is a deepdive white paper also available here.