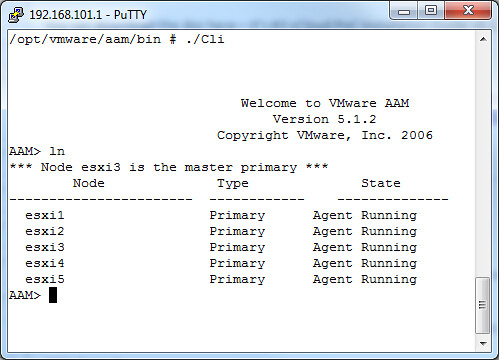
I was just browsing the vsinodes/procnodes. I noticed the following:
Free memory state thresholds {
soft:64 pct
hard:32 pct
low:16 pct
}
As explained in Frank’s excellent article on memory reservations, ESX/ESXi uses memory states to determine what type of memory reclamation technique to use. Techniques that can be used are TPS, ballooning and swapping. Of course you will always want to avoid ballooning and swapping but that is not the point here. The point is that as far as I am aware the thresholds for those states have always been:
- High – 6%
- Soft – 4%
- Hard – 2%
- Low – 1%
This is also what our documentation states. Now if you do the math you will notice that 64% of 6% is indeed 4% and so on… Although it doesn’t seem to be substantial it is something I wanted to document, just for completeness sake.