In this blog post, I want to go over the features which have been released for vSAN as part of 7.0 U3. It is not going to be a deep dive, just a simple overview as most features speak for themselves! Let’s list the feature first, and then discuss some of them individually.
- Cluster Shutdown feature
- vLCM support for Witness Appliance
- Skyline Health Correlation
- IO Trip Analyzer
- Nested Fault Domains for 2-Node Clusters
- Enhanced Stretched Cluster durability
- Access Based Enumeration for SMB shares via vSAN File Services
I guess the Cluster Shutdown feature speaks for itself. It basically enables you to power off all the hosts in a cluster when doing maintenance. Even if those hosts contain vCenter Server! If you want to trigger a shutdown, just right click the cluster object, go to vSAN, select “shutdown cluster” and follow the 2-step wizard. Pretty straight forward. Do note, besides the agent VMs, you will need to power-off the other VMs first. (yes, I requested this to be handled by the process as well in the future!)

The Skyline Health Correlation feature is very useful for customers who are seeing multiple alarms being triggered and are not sure what to do. In this scenario, starting with 7.0 U3, vSAN will now understand the correlation between the events and inform you what the issue is (most likely) and show you which other tests it would impact. This should enable you to fix the problem faster than before.
IO Trip Analyzer is also brand new in 7.0 U3. I actually wrote a blog post on the subject separately and included a demo, I would recommend watching that one. But if you just want the short summary, the IO Trip Analyzer basically provides an overview of latency introduced at every layer in the form of a diagram!
Nested Fault Domains for 2-node clusters has been on the “wish list” of some of our customers for a while. It is a very useful feature for those customers who want to be able to tolerate multiple failures even in a 2-node configuration. The feature requires you to have at least 3 disk groups per host, in each of the 2 hosts, and will then enable you to have “RAID-1” across those two hosts and RAID-1 within the host (Or RAID-5 if you have sufficient disk groups). If a host fails, and then a disk fails in the surviving host, the VMs would still be available. Basically a feature for customers who don’t need a lot of compute power (3 hosts or more), but do need added resiliency!
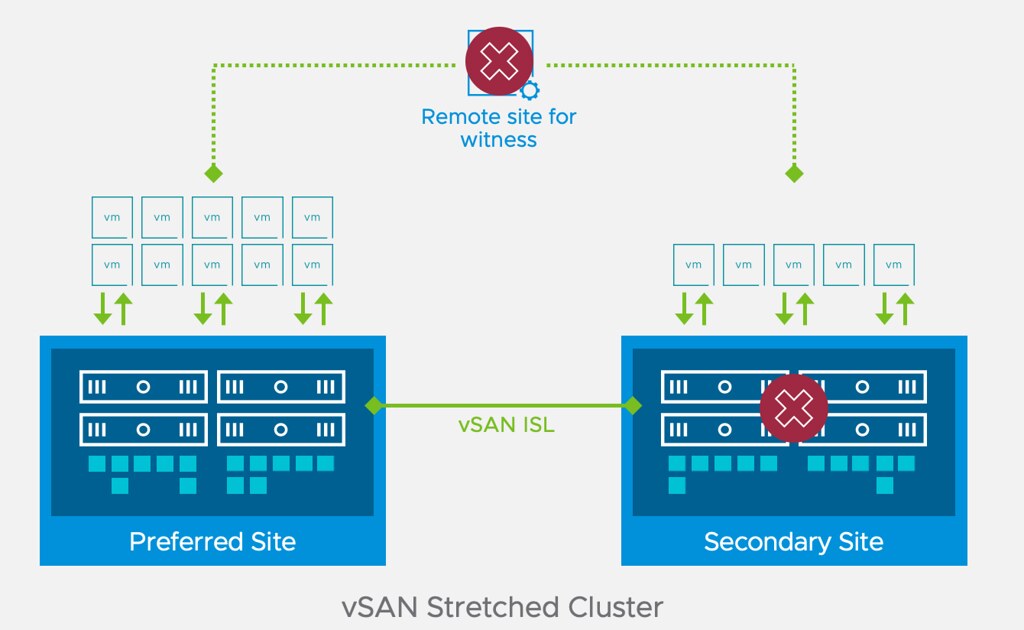
Enhanced Stretched Cluster durability (also applies to 2-node) is a feature that Cormac and I requested a while back. We requested this feature as we had heard from a few customers that unfortunately, they had found themselves in a situation where a datacenter would go offline, followed by the witness going down. This would then result in the VMs (only those which were stretched of course) in the remaining location also be unusable, as 2 out of the 3 parts of the RAID tree would be gone. This would even be the case in a situation where you would have a fully available RAID-1 / RAID-5 / RAID-6 tree in the remaining datacenter. This new feature now prevents this scenario!
Last, but not least, we now have support for Access Based Enumeration for SMB shares via vSAN File Services. What does this mean? Pre vSAN 7.0 U3, if a user had access to a file share the user would be able to see all folders/directories in this share. Starting with 7.0 U3 when looking at the share, only the folders that you have the appropriate permissions for will be displayed! (More about ABE here)
Hi Duncan,
How does the new “Enhanced Stretched Cluster” feature differentiate between the scenario you talk about (failure of one site and the witness) and network isolation of one site? In the second scenario, the inability to form a quorum with the witness will normally kill the VMs on the isolated site so they can safely be restarted on the other site. Is that not the case anymore with this new feature?
Hello there
I also would like to get more details on this new feature
Maybe they finally implemented a solution to choose between poweroff and “keep running locally” for VMs when the ISL is down ?
No we did not implement that, but it is definitely something I requested a while back already.
That is unfortunately a different situation, but it also happens to be a scenario which we have requested to be “fixed”, as we also feel the VMs should not need to restart when there’s a split between the data locations while both locations can still communicate with the witness. In summary, if one data site is isolated from the other, the VMs will still be killed and restarted!
Hi,
Thanks for the info. Yes, the situation is different when only the ISL is down, and as you say, there’s no change with that, but hopefully it will change in the future.
But in the full isolation of one site, I don’t understand the change, how does it know it’s not “just” isolated? Or the change is that it “doesn’t care”, assume everything else is down, keep everything running as is and resolve the conflict later when the connectivity is restored (if it was just a network issue)?
If one site is isolated, then this typically happens simultaneously. This means that there’s no time to restructure the votes. So if you have 3 locations: Data-1,Data-2,Witness. If Data-1 goes down, and 10 minutes later the witness, then in between the Data-1 failure and the witness Failure a recalculation of votes will be done, which will allow for the witness to fail while Data-2 can remain running.
If however Data-2 is isolated from Data-1 and Witness, then the recalculation cannot be done, as a result the components will be inaccessible and killed, just like they are pre-7.0U3
Ok, that makes sense, thanks for the explanation.
Then unfortunately it doesn’t help in my scenario, but hopefully there will be something for that in the future..
Hi,
Yes, that’s why I ask, it would be great if we could choose to only do manual failovers. Unfortunately, network isolation is much more probable (we had a couple) than real site disaster, even with everything redundant, so just waiting it out would be better than needlesly failing over everything.
Understood, let me loop back with the engineering team.
Hi Duncan,
I’m quite interested in the new Cluster Shutdown feature and I’ve been testing it in a lab environment. It works quite well and is much more elegant than our current solution (running scripts through APC’s powerchute appliance), but I can’t seem to find any way to start the process other than using the UI. We’d like to call the shutdown process from a (ideally powershell) script when our UPS monitoring system detects a prolonged power failure.
I tried using vCenter code capture when I performing the shutdown, but didn’t record any events from the process. I also saw that PowerCLI 12.4 has added the ability to call every(?) vSphere API function using new Invoke- and Initialize cmdlets, but apparently the vSAN API is not part of the vSphere Automation API. The VSAN API documentation for 7U3 does have the relevant VsanClusterPowerSystem functions added but they are not exposed in either the VSAN powercli cmdlets or the new Automation API cmdlets.
Do you know if this functionality may be added in the future? It would greatly simplify performing automatic safe shutdowns when power is lost, especially for edge locations
Details around the API can be found here: https://vdc-download.vmware.com/vmwb-repository/dcr-public/bd51bfdb-3107-4a66-9f63-30aa3fae196e/98507723-ab67-4908-88fa-7c99e0743f0f/vim.cluster.VsanClusterPowerSystem.html
Thanks for the reply. As I mentioned in my post, I did find that section of the API in the 7u3 documentation, but there doesn’t seem to be any way to call that functionality using powerCLI. I suppose my question is really just “Do you know if there are plans to update PowerCLI to support the Cluster Shutdown feature?”
Sorry for hitting you with a wall of text haha.
Not sure if there are plans to create a cmdlet, but if you need help with accessing and executing the right commands, I would recommend the VMTN Community, I am sure Luc can help.
Just got a reply from the PowerCLI team, they will write some sample code for this feature soon, and they will consider a cmdlet for a future release.
Glad to hear it, thanks for the update. In the meantime I’ve managed to kludge together a solution using the vSAN managed object browser and invoke-webrequest.
Folks should be advised that this shutdown feature requires all running VM’s to be shut down to work properly.
However, when folks have all their services (AD, DNS, NTP, VCSA, etc.) on a vSAN cluster they wish to shutdown this feature will not work — they’ll have to shutdown vSAN the manual way. I’ve been working with the vSAN team to correct this behavior and at some point it may be able to supply a shutdown feature free of these service requirements.