At VMworld, various cool new technologies were previewed. In this series of articles, I will write about some of those previewed technologies. Unfortunately, I can’t cover them all as there are simply too many. This article is about VMware Cluster Memory, which was session OCTO2746BU. For those who want to see the session, you can find it here. I first learned about VMware Cluster Memory at our VMware internal R&D conference in May this year, and immediately got excited about it. Please note that this is a summary of a session which is discussing a Technical Preview, this feature/product may never be released, and this preview does not represent a commitment of any kind, and this feature (or it’s functionality) is subject to change. Now let’s dive into it, what is Cluster Memory?
Well, it is exactly what you would expect it to be. Providing the ability to create a pool of cross-host memory resources. Now in order to do this, the first problem that needs to be looked at is the network. As mentioned in the session, the ratio of network to memory latency has lowered significantly. In 1997 the ratio was 1000 roughly, right now it is below 10. Meaning that network latency has lowered from milliseconds to low microseconds. Today to reach these low microseconds latencies technologies like RDMA will need to be considered. This change is very important for the Cluster Memory feature being discussed. Also very important, is the fact that RDMA is affordable, and this means it will be coming to a data center near you soon. A huge difference compared to years ago.
Next, the current problems were discussed, the first problem discussed was the fact that it is hard to expand the memory in general. Sometimes customers have to replace all hosts in a cluster simply to provide a single VM sufficient memory, this is not an economically viable option for most customers. For most customers, it is also challenging to predict what the size of the largest VM will be from a memory stance in the upcoming years, especially with new applications this is almost impossible. On top of all of that, memory size is limited per host. Typically a few TB per host when it comes to DRAM. If you need more, then you have to buy very expensive hosts. This is when Marcos Aguilera introduced VMware Cluster Memory. Before we dive further into it, what does it look like?
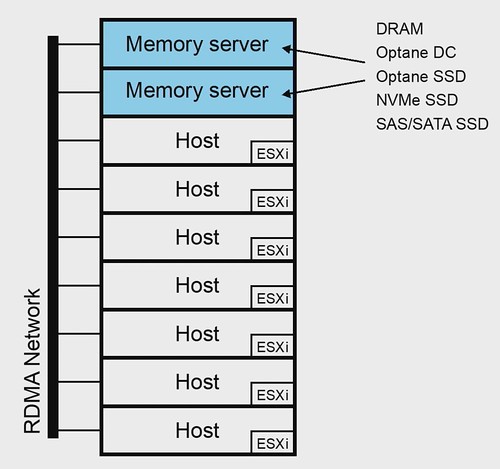
As you can see there are two hosts in the above example which are labeled “memory servers”, these will have TBs of memory vs the GBs the other servers may have, and they will be serving memory capacity up to the ESXi hosts at the bottom. Basically providing a disaggregation of memory and allowing dynamic allocation based on VM requirements, of course via a low latency and high bandwidth connection. The great thing, of course, being that your allocation could change over the course of time, and you can go beyond host physical memory limits when required.

So how does this work, how is VMware considering implementing it? The key idea here is to introduce a new type of paging mechanism. Instead from paging to disk, paging now happens from and to the remote memory pool. Do note that a local cache is needed. You may ask yourself how that works if a local cache is needed, well when pages are accessed they will be transferred from remote to the local cache. Memory for each workload will be scanned, and when pages are unused and we expect them to stay unused for a while those pages will be moved to the memory server. Basically VMware is optimizing the paging mechanisms and will be implementing an intelligent prefetching and reclamation mechanism. Similar to some extent to how swapping to disk works I guess, but with the difference being the speed at which pages are accessible.
Sounds interesting right? But what are some of the technical challenges that exist?
- Failures, disrupting access to Cluster Memory
- Security of data
- Resource management
- Bandwidth consumption
- Lifecycle management
- Performance
Can we do some form of RAID for the memory pages? Can we encrypt the data? Can we enhance DRS to include cluster memory? Can we optimize network bandwidth/transfers? Can we “migrate” memory from one host to the other? How do we get performance as close to local memory, for instance through pre-fetching? Next, a demo was shown of a VM using 3GB of cluster memory.

I guess what all of you want to know is what the performance may look like, note that these are preliminary performance number, this is still under development and these numbers will change! Note that the green bar below is 100% local memory, and the bars next to it represent the performance when only a percentage of the memory is local. What is interesting here most is “SSD-Swap” as that probably is the alternative solution for most people. As clearly demonstrated Cluster Memory is always faster than local SSD-Swap. Also interesting is that RDMA over TCP also performed relatively well, all the way to having 70% remote. Of course, there were also some benchmarks which showed that performance degraded fast, and this was acknowledged by the team, will be researched and hopefully improved before the release.

And that is where the session ended, a very interesting concept and piece of technology being worked on if you ask me. Definitely something I will keep my eye on internally, as I can definitely see a lot of use cases for it. It will allow customers who can’t afford high capacity DIMMS and high capacity hosts to still run large memory VMs. It will also add a new level of flexibility for those customers who need to be able to dynamically assign resource where and when required. If you have the time, make sure to watch the recording, well presented session!
To me, this feels like a more technically interesting feature than running a few Kubernetes containers on the ESXi Hypervisor (though that’s cool also) – both really exciting! As I can tell by the images, you don’t run any VMs on those memory hosts – but I think it would be great if it can. Then in the end you can really share all hosts memory and assign it to any VM. Next step: share CPU resources? Who knows… :-). Thanks for sharing!
Our apps have a large JVM memory footprint – I’ll need to quantify if the latency penalty will make this a net benefit – interesting R&D regardless
That is the interesting part, in some cases the latency hit is negligible, of course depending on the memory access frequency etc.
Hope it does support RoCE and not just infiniband or others like that.
Time to move to composable fabric.
Yes, RoCE is one of them being considered… And I suspect it will be considering the momentum RoCE has.
So, RAM disk for swapping?