I was answering a couple of questions on the VMTN forum and stumbled on the impact of using similar blocksizes for all VMFS volume which I never realized. Someone did a zero out on their VM to reclaim some wasted diskspace by doing a Storage vMotion to a different datastore. (Something that I have described in the past here, and also with relationship to VCB here.) However to the surprise of this customer the zeroed out space was not reclaimed even though he did a Storage vMotion to a thin disk.
After some tests they noticed that when doing a Storage vMotion between Arrays or between datastores formatted with a different blocksize they were able to reclaim the zeroed out diskspace. This is a cool workaround to gobble the zeroes Now the question of course remains why this is the case. The answer is simple: there is a different datamover used. Now this might not say much to some so let me explain the three types that can be used:
- fsdm – This is the legacy datamover which is the most basic version and the slowest as the data moves all the way up the stack and down again.
- fs3dm – This datamover was introduced with vSphere 4.0 and contained some substantial optimizations where data does not travel through all stacks.
- fs3dm – hardware offload – This is the VAAI hardware offload full copy that is leveraged and was introduced with vSphere 4.1. Maximum performance and minimal host CPU/Mem overhead.
I guess it is a bit easier to digest when it is visualized. It should be noted here that fs3dm is used in software mode when HW Offload (VAAI) capabilities are not available. Also note that “application”, the top layer, can be Storage vMotion or for instance vmkfstools:
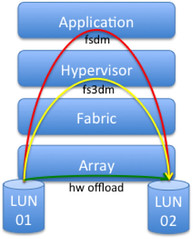
(Please note that the original diagram came from a VMworld preso (TA3220))
Now why does it make a difference? Well remember this little line in the VAAI FAQ?
- The source and destination VMFS volumes have different block sizes
As soon as different blocksized vmfs volume or a different array is selected as the destination the hypervisor uses the legacy datamover (fsdm). The advantage of this datamover, and it is probably one of the few advantages, is that it gobbles the zeroes. The new datamover (fs3dm), and that includes both the software datamover and the HW Offload, will not do this currently and as such all blocks are copied. The fs3dm datamover however is substantially faster than the fsdm datamover though. The reason for this is that the fsdm datamover reads the block in to the applications buffer (Storage vMotion in our case) and then write the block. The new datamover just moves the block without adding it to the application buffer. I guess it is a “minor” detail as you will not do this on a day to day basis, but when you are part of operations it is definitely a “nice to know”.
Duncan,
Nice one! So here you actually see an advantage of NOT using VAAI… Basically you’d want a tickbox on svMotion, “Do not use VAAI” or maybe more human readable “force shrink of thin disks”…
Do you know of any way to force the use of the legacy fsdm?
other than using a different array / blocksized volume. no.
Duncan,
There is a hidden option that determines if the datamover should be using fs3dm or not, though it’s only hidden/available through the use of vsish which is only available on ESXi
/VMFS/EnableDataMovement
1 = yes
0 = no
Description – Whether VMFS should handle data movement requests by leveraging FS3DM
http://download.virtuallyghetto.com/complete_vsish_config.html
Of course it’s probably hidden for a reason, but I assume if you were to disable this, that it would use fsdm?
–William
You can do this also in PowerCLI:
Get-VM -Name “vm-to-shrink” | Get-VMHost | Get-VMHostAdvancedConfiguration -Name “VMFS3.EnableDataMovement”
Get-VM -Name “vm-to-shrink” | Get-VMHost | Set-VMHostAdvancedConfiguration -Name “VMFS3.EnableDataMovement” -Value ([int64] 0)
Get-VM -Name “vm-to-shrink” | Get-VMHost | Set-VMHostAdvancedConfiguration -Name “VMFS3.EnableDataMovement” -Value ([int64] 1)
This brings me to a question, since we are talking about it.
I have always formatted VMFS-3 volumes at 8 MB; even if the LUN size is smaller than 2 TB (-512B).
For the primary reason that workloads move around, including bigger VMs from larger LUNs to smaller LUNs -> Even if the 257 GB VMDK shows up on the 512 GB LUN.
My question is, is formatting at 8 MB at all times OK? Any downside to that?
The sub-block algorithm protects us somewhat from waste, and I’d rather keep functionality high.
What does everyone think?
No, there are no negative side effects for 8MB blocksize formatted volumes Rick.
Wow, what the hell. It isn’t a “regular” occurrence, but anyone trying to use ‘thin’ provisioning would be interested in this one. Some environments are moving whole-sale to thin.
You said, specifically that he was trying to reclaim space by zeroing out, I guess by using something like sdelete. The question I have, is what if the disk type is any one of the “thick” types versus already being set to “thin”. Does that trigger the older datamover? Is a check done that says, “this is thin already, no reason to use the legacy datamover?” If that is the case, that check is probably done when you specifically check the box that says “thin provisioned format” versus “same format as source” or “thick format”. I guess then, if that were the case, you could do a storage vmotion to thick and then back to thin. Maybe it doesn’t matter and you flat out have to use a different blocksized datastore. ;\
OK I just performed some tests.
4MB block -> 4MB block datastore on the same array. Svmotion choosing “thin”. Test VM has a “thick” disk (win2k8r2 — essentially a fresh install).
35 GB “thick” .vmdk before svmotion
14.5 GB “thin” .vmdk after svmotion
Same 35 GB disk above (currently “thin” .vmdk 14.5 GB), with 1 GB of data created, then deleted (confirmed .vmdk is ~15.5 GB). Sdelete to re-zero… which of course inflates the .vmdk to essentially the full size of the disk. Same 4MB block -> 4MB block datastore on the same array. Specifically chose “same format as source”.
35 GB “thin” .vmdk before svmotion
35 GB “thin” .vmdk after svmotion — this is expected given Duncan’s post
Repeated svmotion specifically choosing thin:
35 GB “thin” .vmdk before svmotion
35 GB “thin” .vmdk after svmotion — again this was expected
Repeated svmotion again specifically choosing thick:
35 GB “thin” .vmdk before svmotion
35 GB “thick” .vmdk after svmotion
Repeat svmotion again specifing thin format:
35 GB “thick” .vmdk before svmotion
35 GB “thin” .vmdk after svmotion
Wow… that sucks :\. Although it does appear that thick disks which aren’t eagerzero will save some space on the inital svmotion as zeros aren’t already written. That doesn’t help for p2v’s, etc or anywhere else you want to reclaim. Looks like you need a “mover” datastore specifically set with a different block size in order to remove space. Kind of sucks for the 8mb block size datastores with a 1.1 TB “thin” disk you want to reclaim space from :).
That is what I tested as well and hence this article to explain the impact.
I certainly didn’t mean to take way from your original post. I just didn’t imply enough from it, it isn’t that I didn’t believe you :). I speak Oklahoma English so I have to reread some of what you say sometimes, even in the HA/DRS deepdive book. Hopefully I only added for others rather than detract.
Hello,
On vSphere 5.0u1, with 2 VMFS 5 on the same VAAI array, I SvMotionned my thin VM to thick, then re-SvMotionned from thick to thin and it works.
NB : when I tried from thin to thin, it doesn’t work.
Great find, Duncan, and thanks for sharing this information with us. It would be great if we could trigger use of the legacy datamover (to enable the reclaiming of zero’ed blocks), although I suspect that continued advances in zero reclamation by arrays and expanded use of the T10 UNMAP command will alleviate the need to reclaim those blocks at the hypervisor level.
for people who don’t know what “T10 UNMAP” is ?
Hi Duncan, that is a nice read !
Never realized there were more datamovers.
one quick feed-back, I guess your third bullet should say: HW offload? instead of fs3dm ?
never mind, I misread the third bullet, it is correct after all.
Remains a nice read!
Seems like one reason to do thin on thin, the array should be smart enough to see the zero’d blocks and unmap them at that level =)
@Andrew – that is one reason why I think this option will become more prevalent over time – UNMAP support (both in the array and in the future, in vSphere itself) will make this config the most efficient.
I remember the VAAI FAQ about different block sizes but I probably wouldn’t have connected it to such a scenario until you pointed it out. Nice find.
Jas
I was scratching my head for some time why I cannot reclaim zeroed space. At the end I solved it with svmotion to NFS datastore. Another option is if you can have some downtime, clone the disk with vmkfstools or export it to OVF and import back. There should definitely be a command or checkbox to choose the datamover while doing svmotion.
You forgot to mention the trick to vmkfstools -i 2gbsparse the disk to reclaim. Anyway it would need a downtime :(.
Might be worth linking directly to the VAAI FAQ to save a google search. 😀 http://kb.vmware.com/kb/1021976
All of my Datastores have the same block size so I would be using the fs3dm datamover. I thought by using the shrink feature in VMware tools or sdelete that I would reclaim or zero out unused blocks. Is that not the case. I am doing SvMotion from thick to thin.
Great find! It makes sense why it happens and why the workaround works as the different block sizes and as Tomas said about svMotion to an NFS share.
I wonder if the development team at VMware is working on a fix to this?
C
I spoke with the engineers and they will look into the possibilities. I cannot make any promises unfortunately.
I don’t have a VAAI array yet. But could you just disable VAAI on the ESX servers temporary and that would force it to use one of the legacy datamovers ? I couldn’t find anything that says it requires downtime but you never know.
I believe that’s where William was getting at and it might be cleaner way than the KB article
Here’s the link to the KB article on how to disable VAAI.
http://tinyurl.com/4jjaz68
-Rich
It’s the FS3DM datamover that causes this behavior. That datamover has 2 different mechanisms software or vaai. even if you disable vaai it won’t work. William does mention a hidden advanced option, but I cannot recommend using it.
Thanks for a great article. I need some clarification. How legacy datamover handles zeroed blocks when target vmdk is thick? Does it actually write zeroes?
yes it does copy those blocks and writes them.
This also has consequences for View Composer disks. The supposedly thin provisioned replicas end up fully allocated as happened to a customer I visited this week: http://www.demitasse.co.nz/wordpress2/2011/08/vaai-consideration-with-view-composer/
Does that means, if we have datastore bearing the same block size, the space will not be reclaimed when we use Storage Vmotion since the fsdm 3 soft/hard is used.
Is this resolve in vSphere 5 with the new VAAI?
Yes it means that when you have similar blocksizes in-guest dead space will not be reclaimed.
vSphere 5 does not resolve this. vSphere 5 will only reclaim dead space of the VMFS volume itself when your array supports it, but not dead space in-guest.
Hi Duncan,
Thanks for the explanation. So for VMFS it doesn’t matter the block size as long the array supports it.
For guest only through storage vmo across different block size then will it be reclaimed.
Since vSphere 5 datastores now use 1 MB blocks only, how will we reclaim guest-level wasted space (zeros)? I assume we can’t create an 8 MB block datastore just for reclaiming the unused space. Though to be honest that’s not ideal from a management perspective. I was and am still hoping for a trim-like and ghost clean-up cycle for guests to VMware much in the same way SSD’s manage their deleted space today.
thanks as usual
Only thing u could do with 5 is move to a different array or to an NFS volume…
The engineers are working on improving this though,
Move to a VMFS5 datastore with different block size could still be a solution.
I’ve tried also the William Lam “hack” and it works also on ESXi 5.
Excellent… I understand the concept of datamover choices based on block size. Does this apply to svmotions to different arrays I.e. two VAAI capable arrays?
Hi Duncan,
Any word from the engineers? I ran into this problem when trying to shrink a Windows 7 VM for a View environment. I noticed that when VIEW generates a replica on the same SAN between VMFS stores with the same blocksize, the dead space in the replica is removed. So View must use FSDM??
How is the data integrity verified after being moved through the FSDM. Is it checksummed? Is there any way to verify the checksum in the logs?
What happens when you are Storage VMotioning from a ESXi 4.1 with 3.94 VMFS datastore on FC that are moving vMs to a NAS remotely. How does tyhis affect performance? Also is there anyway to increase performance at all or somewhat?
I’m looking at this issue today. I’m assuming if someone took a VM that was thin on VMFS, and it was Storage vMotion’d to NFS, and back again – its free space would show up in the vSphere Web Client?