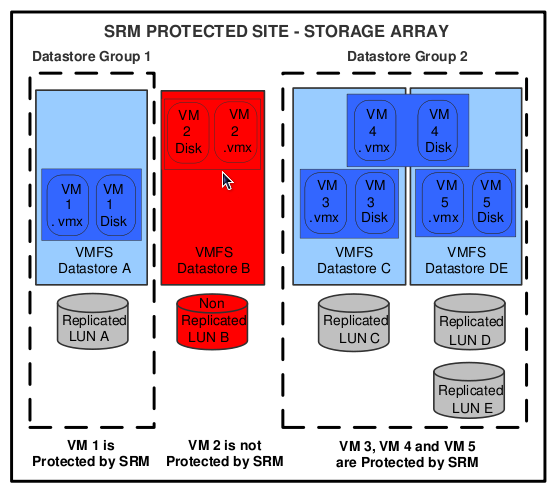
Most of you are familiar with the VMTN Podcasts by now which are hosted by VMware’s John Troyer. One of the regulars of the VMTN podcast, Edward Haletky (also known as Texiwill on VMTN and Twitter), formed a panel of experts on Security and will start a new podcast: The Virtualization Security Round Table Podcast. Those who listen to the VMTN Podcast know how passionate Edward is about security and virtualization so expect these weekly roundtables to be at least on the same level as the VMTN podcasts.
Info about the podcasts can be found on Edwards website:
Episode 1: First Panel Talkshoe on Thursday 15 January 2009 at 2:30 PM EST / 20:30 (CEST): http://www.talkshoe.com/tc/34217
Expect the following topics to be discussed in the near future:
- Use of Virtualization in a DMZ.
- Review of security lockdown standards/benchmarks and tools
- Virtualization Security in shared and dedicated hosting environments
- Providing VaaS (VMware as a Service) securely to SMBs for DR.
- How virtualization security relates to cloud computing security
- Top 3 security issues
- Optimal Network configuration and design for security
- How to accommodate small / medium and home businesses
- Disaster recovery options – small, medium, large businesses
- VLANs as a Security measure with vSwitch Security
If you’ve got ideas / topics for the roundtable hit Edward up on the VMTN forum or via Twitter. And off course it’s also possible to just drop your questions during the podcast on the Talkshoe chat. Mark the date in your agenda, every week on Thursday at 2:30 PM EST / 20:30 (CEST)!