A while ago I wrote an article about the queue depth of certain disk controllers and tried to harvest some of the values and posted those up. William Lam did a “one up” this week and posted a script that can gather the info which then should be posted in a Google Docs spreadsheet, brilliant if you ask me. (PLEASE run the script and lets fill up the spreadsheet!!) But some of you may still wonder why this matters… (For those who didn’t read some of the troubles one customer had with a low-end shallow queue depth disk controller, and Chuck’s take on it here.) Considering the different layers of queuing involved, it probably makes most sense to show the picture from virtual machine down to the device.
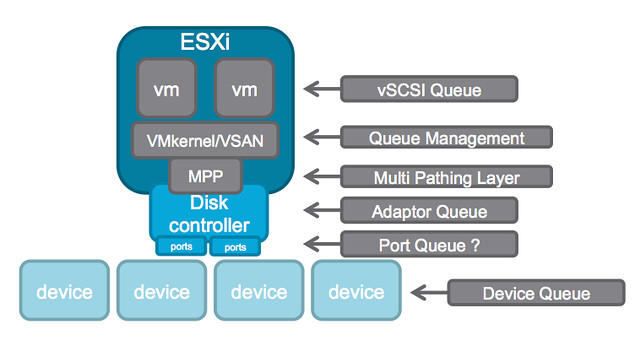
In this picture there are at least 6 different layers at which some form of queuing is done. Within the guest there is the vSCSI adaptor that has a queue. Then the next layer is VMkernel/VSAN which of course has its own queue and manages the IO that is pushed to the MPP aka muti-pathing layer the various devices on a host. On the next level a Disk Controller has a queue, potentially (depending on the controller used) each disk controller port has a queue. Last but not least of course each device (i.e. a disk) will have a queue. Note that this is even a simplified diagram.
If you look closely at the picture you see that IO of many virtual machines will all flow through the same disk controller and that this IO will go to or come from one or multiple devices. (Typically multiple devices.) Realistically, what are my potential choking points?
- Disk Controller queue
- Port queue
- Device queue
Lets assume you have 4 disks; these are SATA disks and each have a queue depth of 32. Total combined this means that in parallel you can handle 128 IOs. Now what if your disk controller can only handle 64? This will result in 64 IOs being held back by the VMkernel / VSAN. As you can see, it would beneficial in this scenario to ensure that your disk controller queue can hold the same number of IOs (or more) as your device queue can hold.
When it comes to disk controllers there is a huge difference in maximum queue depth value between vendors, and even between models of the same vendor. Lets look at some extreme examples:
HP Smart Array P420i - 1020
Intel C602 AHCI (Patsburg) - 31 (per port)
LSI 2008 - 25
LSI 2308 - 600
For VSAN it is recommended to ensure that the disk controller has a queue depth of at least 256. But go higher if possible. As you can see in the example there are various ranges, but for most LSI controllers the queue depth is 600 or higher. Now the disk controller is just one part of the equation, as there is also the device queue. As I listed in my other post, a RAID device for LSI for instance has a default queue depth of 128 while a SAS device has 254 and a SATA device has 32. The one which stands out the most is the queue depth of the SATA device, only a queue depth of 32 and you can imagine this can once again become a “choking point”. However, fortunately the shallow queue depth of SATA can easily be overcome by using NL-SAS drives (nearline serially attached SCSI) instead. NL-SAS drives are essentially SATA drives with a SAS connector and come with the following benefits:
- Dual ports allowing redundant paths
- Full SCSI command set
- Faster interface compared to SATA, up to 20%
- Larger (deeper) command queue [depth]
So what about the cost then? From a cost perspective the difference between NL-SAS and SATA is for most vendors negligible. For a 4TB drive the difference at the time of writing on different website was on average $ 30,-. I think it is safe to say that for ANY environment NL-SAS is the way to go and SATA should be avoided when possible.
In other words, when it comes to queue depth: spent a couple of extra bucks and go big… you don’t want to choke your own environment to death!
I was calling this issue death by queue depth but couldn’t this issue also be – death by firmware?
And this could be a great software opportunity – or VSAN environments who run the lower end HCL-approved controllers – code the “throttles” to run slower??
Today the 25 queue depth is pretty low – but what happens when 600 is the next “low queue depth” because of increased IO on the VSAN?
Will Server Vendors (who usually OEM the SAS/RAID/HBA products) keep maintaining their firmware?
The Dell H310 is a “low-end shallow queue depth disk controller” but its also based on the LSI 2008 which appears to be “25 / 600 (firmware dependent!)”
If Dell wanted – could they have pushed a Firmware out that improved queue depth to 600?
Dinesh Nambisan – who I now regard as the ‘Godfather of VMware vSAN’ as he “boot-strapped, built the team and drove execution of VMware Virtual SAN from concept to shipping” from VMware wrote on Reddit that “VSAN does have an inbuilt throttling mechanism for rebuild traffic”.
And even though VSAN will throttle back rebuild activity if needed – Vmware’s root cause analysis said:
“While VSAN will throttle back rebuild activity if needed, it will insist on minimum progress, as the user is exposed to the possibility of another error while unprotected. This minimum rebuild rate saturated the majority of resources in your IO controller. Once the IO controller was saturated, VSAN first throttled the rebuild, and — when that was not successful — began to throttle production workloads.”
Maybe that “minimum progress” on that “rebuild throttle” can be dynamically adjusted for the “shallow end of the RAID pool” like a lifeguard and prevent drowning by queue depth (or drowning by firmware).
Can a vendor really push the QD via firmware? I don’t think it’s always possible, and if it is, not by much. The controller must have the processing power to handle the additional commands, and code optimization can only go so far.
VR Bitman,
In Synchronet’s VSAN labs just between the two firmware on H310/LSI 2008’s we saw a difference of 10x better IOPS and 30x better latency. Write operations are just brutal with that narrow queue depth and it is a 100% software update. Issues like this is why I’m starting to lean towards working with SuperMicro/LSI/VMware directly for customers when possible.
http://thenicholson.com/lsi-2008-dell-h310-vsan-rebuild-performance-concerns/
Now if I can find some time I’m going to do a shoot out with a lot of different switches (Juniper/brocade/Cisco/Dlink/Netgear) in 1 and 10 Gbps configurations….
As John mentioned with the LSI 2008 the difference is 25 –> 600. This is huge if you ask me, and I have heard of at least 1 other occasion where this happened.
Rob the problem with adjusting it too low is you start exposing people to dataloss (too slow of a rebuild). I’d rather take a 4 hour outage on something that can be fixed, than discover dataloss. VMware (like all smart storage companies) errors on the side of not loosing data. This is the #1 rule of storage.
Wow, sorry guys, was ssh’ed into the wrong host on my 3 node cluster/eyes crossed. HAH, funny how things work a whole lot better when you querying the proper host w/ devices installed. 😀
LSI 9271-8i RAID controller supports queue depth of 256 per target and 976 per controller [per conversation with LSI Support]. When looking for a suitable RAID controller for VSAN, are we concerned with the per controller value, per disk value or both?
The Cisco UCS 240 M3 supports up to 24 drives. Theoretically, could max. this server with 4 disk groups configured as: 1x SAS SSD + 5x SAS HDD = 24x drives. If the total controller Max Queue Depth is 976. That would mean 40[e] Max Queue Depth per SAS drive.
All we have accomplished is to move the bottleneck away from the controller and onto the disk device queue. If SAS device has a queue depth of 254, do we still have a “VSAN Nightmare” problem in the event of a rebuild? Thx.
You should be concerned about both of course, but 256 per target is more than most disks can take anyway. The problem described in that VSAN Nightmare thread was the fact that the whole controller only had a queue depth of 25. With a controller queue depth of >256 you will not hit these issues.
Hi Duncan – I am curious whether adaptive queue depth algorithms (I believe that came out with ESX 3.5 Update 4???) should/could be implemented in a VSAN environment? Back in my 3PAR days, we were pretty hot on that feature and wonder if that could be trickled down to VSAN to simplify performance management.
Not sure how that would help to be honest, keep in mind that hosts access disks locally and disks are not shared between hosts but rather between VMs. Completely different concept then a traditional array.
yep – got it – thanks
Duncan – Considering that SATA has a QD of 32, should one always stick with a SAS based SSD? I see the Intel S3700 drives recommended a lot for VSAN but those are SATA disks, going SAS only for SSD really limits the choices on the current VSAN HCL.
Thanks!
I think for SSDs it is slightly different due to the speed at which is can empty a queue as well 🙂
Excellent – That’s what I was assuming but wanted an experts opinion. Cheers!
Excellent Post. Much appreciated.