I was reading this article by Michael Webster about the benefit of Jumbo Frames. Michael was testing what the impact was from both an IOps and latency perspective when you run Jumbo Frames vs non-Jumbo Frames. Michael saw a clear benefit:
- Higher IOps
- Lower latency
- Lower CPU utilization
I would highly recommend reading Michael’s full article for the details, I don’t want to steal his thunder. Now what was most interesting is the following quote, I highly regard Michael he is a smart guy and typically spot-on:
I’ve heard reports that some people have been testing VSAN and seen no noticeable performance improvement when using Jumbo Frames on the 10G networks between the hosts. Although I don’t have VSAN in my lab just yet my theory as to the reason for this is that the network is not the bottleneck with VSAN. Most of the storage access in a VSAN environment will be local, it’s only the replication traffic and traffic when data needs to be moved around that will go over the network between VSAN hosts.
As I said, Michael is a smart guy and as I’ve seen various people asking questions around this and it isn’t a strange assumption to make that with VSAN most IO will be local, I guess this is kind of the Nutanix model. But VSAN is no Nutanix. VSAN takes a different approach, a completely different approach and this is important to realize.
I guess with a very small cluster of 3 nodes Michael chances of IO being local are bigger, but even then IO will not only be local at a minimum 50% (when failures to tolerate is set to 1) due to the data mirroring. So how does VSAN handle this, what are some of the things to keep in mind, lets starts with some VSAN principles:
- Virtual SAN uses an “object model”, objects are stored on 1 or multiple magnetic disks and hosts.
- Virtual SAN hosts can access “objects” remotely, both read and write.
- Virtual SAN does not have the concept of data locality / gravity, meaning that the object does not follow the virtual machine, reason for this is that moving data around is expensive from a resource perspective.
- Virtual SAN has the capability to read from multiple mirror copies, meaning that if you have 2 mirror copies IO will be distributed equally.
What does this mean? First of all, lets assume you have an 8 host VSAN cluster. You have a policy configured for availability: N+1. This means that the objects (virtual disks) will be on two hosts (at a minimum). What about your virtual machine from a memory and CPU point of view? Well it could be on any of those 8 hosts. With DRS being envoked every 5 minutes at a minimum I would say that chances are bigger that the virtual machine (from a CPU/Memory) resides on one of the 6 hosts that does not hold the objects (virtual disk). In other words, it is likely that I/O (both reads and writes) are being issued remote.
From an I/O path perspective I would like to re-iterate that both mirror copies can and will serve I/O, each would serve ~50% of the I/O. Note that each host has a read cache for that mirror copy, but blocks in read cache are only stored once, this means that each host will “own” a set of blocks and will serve data for those be it from cache or be it from spindles. Easy right?
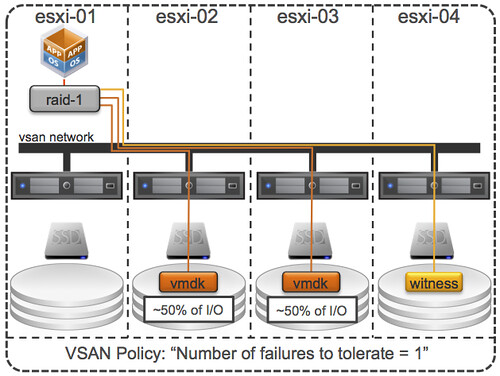
Now just imagine you have configured your “host failures” policy set to 2. I/O can now come from 3 hosts, at a minimum. And why do I say at a minimum? Because when you have the stripe width configured or for whatever reason striping goes across hosts instead of disks (which is possible in certain scenarios) then I/O can come from even more hosts… VSAN is what I would call a true fully distributed solution! Below is an example of “number of failures” set to 1 and “stripe width” set to 2, as can be seen there are 3 hosts that are holding objects.
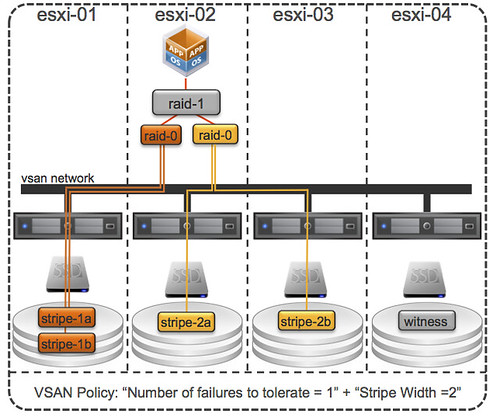
Lets reiterate that. When you define “host failures” as 1 and stripe width as 1 then VSAN can still, when needed, stripe across multiple disks and hosts. When needed, meaning when for instance the size of a VMDK is larger than a single disk etc.
Now lets get back to the original question Michael asked himself, does it make sense to use Jumbo Frames? Michael’s tests clearly showed that it does, in his specific scenario that is of course. I have to agree with him that when (!!) properly configured it will definitely not hurt, so the question is should you always implement this? I guess if you can guarantee implementation consistency, then conducts tests like Michael did. See if it benefits you, and if it lowers latency and increase IOps I can only recommend to go for it.
PS: Michael mentioned that even when mis-configured it can’t hurt, well there were issues in the past… although they are solved now, it is something to keep in mind.
Great Post !
Help me to understand how these solutions do not exponentially drive up storage costs.
I ask because I have discussed large datasets with a number of similar solutions and usually arrive at the centralized array again.
For each machine instance, I will consume approximately double the consumed storage space. If VM1 is provisioned 60GB and consumes 30GB. I will consume 30GB from my local disks within the vSAN cluster. If the same VM consumes all of its allotted capacity, 120GB is taken. If the replication is set higher than 1, then this consumption rate multiplies.
For temporary system images and small footprint solutions (Amazon, VDI, etc.) I see significant value. In cloud application architectures, I would set the replication to 0 or else end up flooding the storage with the replicated application tiers.
Similarly, DBs and file archives might consume the entire storage pools with hundreds of GBs duplicated.
So, what are the use cases for which vSAN shines?
Not sure which similar solutions you are referring to and how a centralized array would be less expensive. I typically don’t see that in the field to be be honest.
I think DWP is arguing that de-duped storage is really useful and that Capacity/GB is the limiting factor. For what its worth I’m building an entire 3 node 2RU server VSAN cluster with 36TB RAW (18TB replicated once) and 720GB of Flash with 10Gbps for under $15,000. I can’t get a HUS/VNX/3PAR/Netapp FAS in that territory of cache/capacity. This is something I’m actually going to be able to run VM’s off of (144GB of RAM, 18 Cores of E5 across the cluster). This is just a lab build, but if this is what people can do, its going to be very disruptive, especially as this system will scale linearly, while modular arrays hit random walls when the storage processor gives up and then they require forklift upgrades.
Honestly Dedupe is something you do at a VM level (Linked Clones in View, or vCloud) a file level (SIS) or a block level inside a VM or on a NAS head or in an archive (Server 2012, Netapp or HNAS, HCP). Inline compression is becoming more popular for data reduction (lower IO hit, and you don’t have to maintain in memory dedupe tables or pay a latency/IO hit and you can custom tune the data reduction to the workload and the block size while maintaining data reduction across array or other snapshot.
Honestly I’d rather do dedupe closer to the data or in a backup process. Blindly doing it to all blocks can have unintended consequences, and in my opinion in an era of 4TB drives with 100 IOPS is kind of a fad. Trying to cram more inside the spindle isn’t necessarily the best solution (unless your doing it to flash, and even then a lot of vendors like Nimble are leaning towards compression instead).
My concern is actually around large data sets tided to distributed applications which replicate.
A simple example is Microsoft Exchange. Larger deployments commonly use DAGs for performance and availability. Exchange will replication its GBs of data between instances.
With vSAN or similar solutions, the concern becomes data placement, performance, and utilization. Will I end up with 4 copies of the data – 2 copies from exchange replication and 2 copies from vSAN replication?
Another is Microsoft’s DFS solution.
With a legacy array. There is a single copy of any virtual machine (normally) striped across a number of spindles. With vSAN, to maintain availability, the VM must be copied at least once. So my storage is automatically cut in half. While the entry costs are lower, my burn rate and cost of growth may escalate as I have to continually double the storage allocation.
I believe this is the reason that AWS treats basic images a disposable and there is extra cost for S3/EBS. Trying to build the case and numbers for a 1,000 VM footprint as I like the technology and see many benefits, but as they say – how does it scale?
I would argue that the majority of applications in datacenters are far from that advanced unfortunately, and in those cases where they are you have the ability with VSAN to create a fully custom policy for that specific VMDK even or VM or multiple VMs.
Now even if you look at a traditional storage environment you would end-up with various copies if you would run your Exchange Server on there. When I owned these types of environments we ran exchange on RAID-1 storage, which means 2 copies of your data (same as VSAN conceptually speaking), now if you replicated that to a RAID-1 set guess what…
I mean, with VSAN you do not need to create mirror copies. You can set it to 0 if you want because your app architecture is smart enough to handle this for you… that is up to you.
Im having trouble following the logic here against data locality/gravity. I understand the inherent benefit of “2 different sets of disks serving up an equal share of the I/O, but wouldn’t that become cumbersome at scale? your words ” moving data around is expensive from a resource perspective.”,
For example, a VM on host 1 is reading/writing I/O locally (SSD). trigger DRS event > VM goes to host 2 and starts writing locally, then when it reads across to host 1, it writes a local copy so it can read locally again, thereby saving the network pipe on unnecessary traffic in the future.
if you don’t do this you are just spamming the network with read/writes. on a small VSAN cluster, not such a big deal, but once we get bigger, we could start hammering the network.
But because VSAN is an object store, and not moving just blocks, I can see where the design logic fits. writing the whole vmdk would be way worse on network and performance than just the hot blocks.
You lost me. Data never moves with the VM. Even if DRS triggers an event then the VM would not write locally afterwards UNLESS there was already an object of that VM sitting there.
VSAN is not a distributed file system, it is an object store.
Hi Duncan,
I understand that data is not following the virtual machines but resides where they are created. What’s not clear to me is where the initial creation takes place. Suppose we have a 4 cluster node with N+1 redundancy and i create 10vm’s on host one. Will VSAN then creates 10 VMDK’s on host 1 an d distribute 10 redundancy copys across the three other nodes or will it create 10 VMDK’s random across the 4 nodes with random creation of te redundancy copy’s.Or something else? Hoe does it handle’s load balancing after that?
Rgds, Jerry