I’ve written about Permanent Device Loss multiple times but another scenario that some of you might have encountered is All Paths Down. All Paths Down already describes the scenario, but an example would be when for whatever reason the network between the host and the array fails. This would be result in an APD condition, meaning that the LUNs are unreachable due to the fact that all paths to the LUN are gone.
Some of you who have been in this scenario probably also have seen hosts being disconnected. In some cases, I’ve seen this happening at one point, a host might even freeze up. This would typically happen when a lot of I/O was sent to the datastore. This is of course something that everyone would want to avoid and hence a new advanced setting has been introduced, a new mechanism to handle APD conditions.
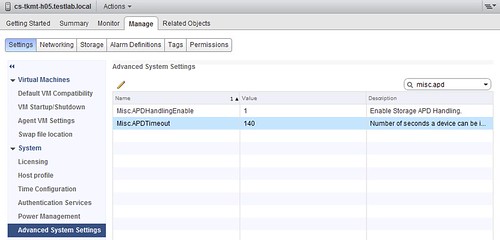
This brand new setting is called Misc.APDHandlingEnable. It can be set to 0 or 1. A value of zero means that ESXi will stick to the “old” method which is to always retry failed I/O’s. A value of 1 enables the new behavior. The behavior will allow ESXi to “fast-fail” I/Os. This will happen after 140 seconds by default. Fast-failing I/Os is what will prevent the host to be disconnected or frozen up. This is configurable though through Misc.APDTimeout. Note you can set a filter in the Web Client to find the right advanced setting as shown in the screenshot below. Note that the minimum value for Misc.APDTimeout is 20 seconds.
Cormac Hogan has a great article about APD with a lot more technical details, make sure to read it.
At Keith Farkas’s talk at VMworld, he did mention that this is only for host I/O, not for guest I/O… guest I/O will just spin while the host I/O will time out. This is a great stride forward, but doesn’t do much to help fix guest datastore loss issues. HA still won’t detect an APD condition as a failover, so FT won’t protect against these unless management ports are on the same downed paths as the datastores. 🙁
Do these enhancements to APD handling allow HA to kill/restart VMs using datastores that have entered APD state? (Specifically does the disk.terminateVMOnPDLDefault setting also cover VMs with datastores in “APD Timeout” state? Based on my reading it looks like VMkernel IO is handled the same in a PDL state and an “APD Timeout” state.)
Does anyone know how this will apply to RDMs? We have a bunch of physical mode RMS (and a small number of virtual mode) on a SAN that we have to power down for maintenance. Is it sufficient, to power down the VMs with the RDMs to avoid any APD problemds? ESXi 5.1U1. I think we would avoid locking up the host as long as the guests are not powered on an issuing any IO right?