Just something I wanted to document for myself as it is info I need on a regular basis and always have trouble finding it or at least finding the correct bits and pieces. I was more or less triggered by this excellent white paper that Herco van Brug wrote. I do want to invite everyone out there to comment. I will roll up every single useful comment into this article to make it a reference point for designing your storage layout based on performance indicators.
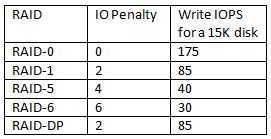
The basics are simple, RAID introduces a write penalty. The question of course is how many IOps do you need per volume and how many disks should this volume contain to meet the requirements? First, the disk types and the amount of IOps. Keep in mind I’ve tried to keep values on the safe side:

(I’ve added SSD with 6000 IOps as commented by Chad Sakac)
So how did I come up with these numbers? I bought a bunch of disks, measured the IOps several times, used several brands and calculated the average… well sort of. I looked it up on the internet and took 5 articles and calculated the average and rounded the outcome.
[edit]
Many asked about where these numbers came from. Like I said it’s an average of theoretical numbers. I used a (now offline) article from ZDNet as the theoretical basis. ZDNet explains what the maximum amount of IOps theoretically is for a disk. In short; It is based on “average seek time” and the half of the time a single rotation takes. These two values added up result in the time an average IO takes. There are 1000 miliseconds in every second so divide 1000 by this value and you have a theoretical maximum amount of IOps. Keep in mind though that this is based on “random” IO. With sequential IO these numbers will of course be different on a single drive.
[/edit]
So what if I add these disks to a raid group:
For “read” IOps it’s simple, RAID Read IOps = Sum of all Single Disk IOps.
For “write” IOps it is slightly more complicated as there is a penalty introduced:
So how do we factor this penalty in? Well it’s simple for instance for RAID-5 for every single write there are 4 IO’s needed. That’s the penalty which is introduced when selecting a specific RAID type. This also means that although you think you have enough spindles in a single RAID Set you might not due to the introduced penalty and the amount of writes versus reads.
I found a formula and tweaked it a bit so that it fits our needs:
(TOTAL IOps × % READ)+ ((TOTAL IOps × % WRITE) ×RAID Penalty)
So for RAID-5 and for instance a VM which produces 1000 IOps and has 40% reads and 60% writes:
(1000 x 0.4) + ((1000 x 0.6) x 4) = 400 + 2400 = 2800 IO’s
The 1000 IOps this VM produces actually results in 2800 IO’s on the backend of the array, this makes you think doesn’t it?
Real life examples
I have two IX4-200Ds at home which are capable of doing RAID-0, RAID-10 and RAID-5. As I was rebuilding my homelab I thought I would try to see what changing RAID levels would do on these homelab / s(m)b devices. Keep in mind this is by no means an extensive test. I used IOmeter with 100% Write(Sequential) and 100% Read(Sequential). Read was consistent at 111MB for every single RAID level. However for Write I/O this was clearly different, as expected. I did all tests 4 times to get an average and used a block size of 64KB as Gabes testing showed this was the optimal setting for the IX4.
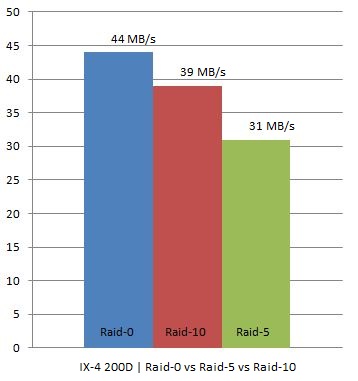
In other words, we are seeing what we were expecting to see. As you can see RAID-0 had an average throughput of 44MB/s, RAID-10 still managed to reach 39MB/s but RAID-5 dropped to 31MB/s which is roughly 21% less than RAID-10.
I hope I can do the “same” tests on one of the arrays or preferably both (EMC NS20 or NetApp FAS2050) we have in our lab in Frimley!
<update: December 2012>
More info about storage / VMFS volume sizing can be found in the following articles:
- VMFS-5 LUN Sizing
- LUN sizes in the new Storage World
- Should I use many small LUNs or a couple large LUNs for Storage DRS?
</update>
Good article, Duncan, and a worthy topic. In fact, this is something I’ve been mulling over as well. I am absolutely convinced that too many virtualization architects don’t take IOPS into consideration when planning datastores or placing VMs.
I’m curious, though–since RAID-DP is a modified form of RAID 6, why are the IO penalties so dramatically different between the two?
Could you comment on the IO types that led to these numbers?
Random vs Sequential. IO size. Number of outstanding requests.
Thanks Duncan. Great article.
good article. For me it is always important to get the max iops per storage processor and lun (when talking about san). and also talk with the storage admin how the raid is setup and how many disks are configured in the raid setup.
Duncan, well done. I agree that too often I hear admins and users complain that their virtual infrastructure is “slow” and in many cases it is a well sized server environment attached to a woefully underpowered, and oft mis-configured, SAN or NAS.
One great VMTN thread that goes beyond RAID/Striping and into the actual arrays and their RAID configs with IOMeter performance stats is by ChristianZ. Great reference material for choosing potential arrays, and the optimal configuration for them. http://communities.vmware.com/thread/197844
Hi Duncan,
Interesting stuff. I agree with Scott – this is definitely an area (ie: IOPS) that is often overlooked in both physical and virtual implementations.
I have just finishing performing a series of tests on one of my home HP Proliant servers measuring disk performance between single disk and dual disk RAID 0 and 1 configurations. I would have liked to have tested RAID 5 and 6 though unfortunatley didn’t have sufficient SAS disks.
Although I haven’t had time to review the results in depth yet a quick glance indicates that they do appear to hold true to the expected IOP rules as you mention above.
I will be putting a post together soon with the results and a little more basic analysis. In the meantime I hope to pick up another SAS drive or two on EBay to allow me to test RAID 5 and 6.
Keep up the good work,
Simon
I forgot to mention the tests I performed were with both SAS (10K) and SATA (7.2K) drives so as to also compare and confirm the extent of performance differences (in my lab instance at least) between drive types. Cheers.
Very good reference information. This information is useful for creating baseline sizing, but may not be accurate when taking into account the caching perfomred by an array, or an array that uses a non-standard RAID method. For example, a NetApp array using a PAM module, or an array such as the IBM XIV that stripes all data accross all disk and is heavily dependent on it’s cache modules.
To answer the question posed by Scott above, RAID-DP’s write performance penalty is much less than standard RAID-6 because in RAID-DP, the dual parity bits are not striped accross all drives in the raid set. Parity is maintained by two specific drives, which reduces the amount of IO nececarry to maintain write parity. RAID-6 vs RAID-DP is akin to the difference between RAID-5 and RAID-4.
Wade
Disclosure – EMC employee here…
Duncan – this is a very important point, and very important to understand (storage newbies think in GB, veterans think in GB, IOps, MBps and latency).
I will say that the calculations you saw are a bit worst case scenario, and reflect local RAID type models, not array models.
For example, the “extra IO” (extra non-parity reads and writes) triggered during a parity write is only introduced when you **don’t** have a full-stripe write. if it’s a full stripe write (overwriting the full stripe size), it doesn’t need to read the old contents, re-calculate the parity on the new contents – and simply recalcs the parity via an XOR and blasts it down. (BTW – note that most low-end on-chipset or low cost RAID controllers do XOR in software not hardware).
This is why storage vendors are always so emphatic about stripe alignment (i.e. align the volume along stripe boundaries) – in VMware land, this happens automatically when configuring VMFS via the vSphere and VI client, but is why there’s benefit from aligning VM guest partitions also (Windows NTFS volumes on Windows XP, vista, W2K, W2K3 start unaligned to a the 64K boundary, but not at 0). Aligning IO on stripe boundaries dramatically increases the likelyhood that IO can be a “full stripe write”.
Second, advanced higher end arrays do a LOT of write coalescing – batching up the IOs, and trying to maximize full stripe I/O and other factors. This also can help with locality (“derandomizing IO”), and also in some cases can actually do the parity from a read-cached value. In practice in those arrays, parity RAID impact (R5, R6 and R-DP) are much lower than the worst case scenarioes – and generally not matching R1, R0 and R10 performance, they can approach (with some workloads, match or even beat).
How could parity RAID beat mirroring models? Sometimes, for read-centric workloads, there is more parallelism…. Think of an example – on a read, in a 8-disk R10 set, the contents can be read from 4 disks simultaneously – the other 4 disks simply have a mirror of the same data. The same configured as a R6 6+2 set – you can read from 6 disks simultaneously.
@Bjorn Bats – one thing I would warn – many storage vendors overstate their IOps maximums – taking very large cache hit rates as their key assumption. Storage vendors have specs they publish and others which are internal – “what to expect in the real world”. I would recommend to any customer to push for those values rather than what is publicly positioned. At EMC, CSPEED (Midrange block), NSPEED (NAS), and SPEED (enterprise block) people are the people with all that info, just ask the team that supports you for one of them, and you’ll get a good, non sales answer. I’m sure my peers at other storage companies have similar models/groups.
Thanks Duncan – a great topic to bring to a broader audience!
(BTW – I cover this idea in Chapter 6 in a great deal of depth in Chapter 6 of Scott Lowe’s “Mastering vSphere 4”, where I guest-wrote the storage chapter)
Again, disclosure, I’m an EMC employee.
@Wade – not claiming to be an expert on NetApp, so please correct me if I’m wrong on any of the below. The parity cost of R6 is the same as R-DP, the difference of a dedicated parity disk vs. distributed parity can sometimes be good, and sometimes be no good.
What is the case is that NetApp behavior does all writes as new writes (write anywhere file layout) – which is different than other storage subsystems, which if a write is an “overwrite” move the actuator and wait for the spindle to rotate such they can overwrite the original block (data block or parity block). This results in a tendency for WAFL to have lower write latency so long as contiguous locations are generally available (i.e. places to blam down the IO to disk). This is likely one of the main reasons why NetApp selected R4 and R-DP – as a dedicated parity disk works better with this core model.
If you look at a NetApp device sitting beside any other array, and look at the disk LED pattern, this behavior is visible to a human eye.
Random write IO = “blink…. blink…. blink” on a NetApp array (the IO’s get cached up, and laid out in large contiguous write patterns). Conversely if you look at the same on a CLARiiON (or other arrays more generally), you’ll see the lights all doing this = “blink, blink, blink” all in a crazy pattern (the IO’s are getting laid out all in their localized places). Conversely, reading a sequential write pattern will have the inverse pattern (NetApp blinks rapidly and randomly, other array blinks in cadence across the raid set)
As with most things, all engineering decisions tend to have trade-offs.
I agree with your point on caches being important as they absorb the RAID penalties is the same point I was making earlier (and applies across all sophisticated array types).
I’m completely agree with Chad Sakac.
I always say it’s all about the I/O profile. What are your writes, sequential or random. What is your block size 8k 16k 32k 64k etc. What is your read/write ratio? These are things that counts to.
If you go further than just the disk and look how many IOPS you can do on the disk controller? This formula will help.
a. Block Size/Throughput (i.e. 32KB/320MB) = T; where T = time in ms
b. Block Size * 1/(controller overhead + T)ms = I; where I = IOPS
How many IOPS can we do on disk?
a. 5ms + (rotational delay/rotational speed) + I = T; where T = time in ms
Let’s assume rotational delay = .5 (given by If rotational latency is 15,000 RPM, then 15000/60/1000 = .25 ms
So,
5ms + .5/.25 ms + 1000/T = IOPS p/disk
What about caching. Caching is very important and usually the reason why you choose a vendor besides costs :).
But basically you’re right about IOPS. Most Hdd companies give good values regarding there IOPS on the disk to work with. But when there are ‘High end apps’ who needs performance, You should note that there is more than just IOPS on the disk.
At least this is my opinion.
Disclosure – NetApp Employee here
Duncan,
Great post and I think something that folks need to understand and think more about. I run into this when customers are lured by the large drive sizes available with SATA drives however the much lower RPM means significantly lower IOPS available. In my world with NetApp Deduplication and the dedupe rates seen with most virtual environments customers on the slower drives can run out of IOPS long before they use up all the available capacity. I can actually get more VMs per shelf of FC disks thanks to dedupe and the higher IOPS available on the faster disk spindles. In VDI environments where dedupe is wildly effective I have often joked I would love to have a few trays of 15K 18GB drives again. I don’t need the capacity just the spindles.
Also as mentioned cache and intelligent cache such as our PAM card also offloads a significant number of IOPS from the disks which also has to be factored in. Sizing is definitely different and more interesting than it was a few years ago.
Wow, thanks for the comments everyone. I know I seriously over simplified things and I also used worst case scenarios but that’s what needs to be done to address a topic like this.
@Chad like I said I tried to over simplify things to make it clear that there is a performance impact. Maybe we can do a collaborative article with for instance Vaughn to see how it impacts performance.
@Keith , you just addressed the issue I have with deduplication. These offerings are usually based on “cost savings” which is limit the amount of spindles. Often people forget the downside and hit the limitation and more than often in VDI environments as IOPS are underestimated. Now I love the technology, don’t get me wrong but there is a downside to it when people design without doing the math. That happens a lot as storage admins and virt admins don’t tend to talk to eachother.
Disclosure – EMC Employee here…
@Duncan, I love how you make topics simple. As you can see from my comments and blog posts – I suck at that 🙂 Now, in defense of my NetApp brother in the spirit of the holiday season :-)….
PAM (and in ONTAP 7.3 and later, FAS platform cache in general) deduplication helps NetApp by effectively increasing the cache size – since a single block are effectively referred to multiple times. Now, to be clear, all caches on arrays that I know work this way (ergo re-directed pointer-based snapshots or cloned blocks are only cached once) – but NetApp can do this on a volume that isn’t using snapshots/clones, but is a primary storage volume since their dedupe eliminates the block that is a duplicate (in a way that is analagous, but not the same as a snapshot in general).
But – larger cache is generally good, and helps overall system performance (again, some workloads more than others).
The same effect occurs if you are using VMware View composer (the base replica which serves all the images fits in a smaller effective cache, but has the impact as if all the linked clones are cached.
I wanted to stay away from this – I dread saying something that can be construed as competitive, or too biased (I try my darnest to say open-minded, but some bias I suppose is inevitable) – and this is certainly not the forum for one vendor vs. another (not my intent here)
Now – where I see this get oversold by sales (rarely SEs) is in three fashions:
1) the point that Keith raised (a great comment – showing he has his customers at heart, which is all any of us vendors can do) – which is sometimes you have capacity to spare but need IOPs.
2) the cost of PAMs, and often larger FAS platforms required to accomodate large PAM II configurations) are added in late after the deduplication conversation (changing the economic proposal). This is just bad selling (EMC does it too although I fight it everywhere I find it – not implying that this is vendor-specific)
3) All caches (including PAM) can help with cacheable IO – particularly cacheable reads. Caches also help with absorbing write bursts, but the backend storage (spindles) need to be able to destage (commit) the write cache otherwise it overflows, and then the host sees the performance of the backend (non-cached disk) directly. This has been (across all storage vendors) the thing that I’ve seen impact VDI projects the most, which have the greatest opportunity for capacity savings due to commonality, but also some of the highest IO density – I did a post on that here: http://virtualgeek.typepad.com/virtual_geek/2009/12/whats-what-in-vmware-view-and-vdi-land.html
I suppose a good “middle ground” position would be “have the storage vendors tell you how they can improve IOps density (cache and other techniques) and save money, but also consider the spindle count needed without any vendor-specify magic. If anyone is claiming they can get away with 1/2 or even less spindles than you see from the basic math, consider walking away backwards, and slowly”.
I’ve got to be honest, it’s for that reason that I don’t understand the general market positioning that PAM (or caches in general) and SSD are mutually exclusive. Solid state disks can be what Keith states (and Duncan, consider adding them to your table – they do 6000-8000 random IOps) – a small number of IOps eating “spindles” behind an even faster read/write cache – and even host-based use of flash, like VMware’s recent SSD as vswap study, or FusionIO cards in servers. Frankly, I think all vendors would be well-served by doing both.
@ Chad Well said my Canadian brother! Your price on PAM does come up on occasion when customers get really excited for the PAM and SSD technology even though they likely don’t need it. As Chad mentioned in 7.3 and later our standard cache in controllers is dedupe aware also and for most mid sized environments, server or VDI that is sufficient to meet the customers demands. It is nice to know though, that we could always add a PAM card in after the fact if the additonal cache is required.
You got it right, there is a balance and deduplication only changes how you size storage. It is one of those technologies though that does make you potentially change what type and how many spindles you need.
All of these technologies are good things, we just have to adapt to them and insure customers understand them so they are used to their full potential just as we had to do when server virtualization first took off. We as virtualization “experts” helps customers understand where it was and was not a fit. As the vendors have changed and improved their technology we constantly have to adapt those definitions. Same will be true of storage as new technologies such as Dedupe, SSD and intelligent storage placement become more main stream.
Duncan,
Now you just need some SSD numbers in here with a few choice applications for use vs RAM disk and the thought circle is almost complete 🙂
Disclosure – Xiotech Employee here 🙂
Hey Duncan – GREAT POST !!
Not to throw another log on the fire but 🙂
On your IOPS per drive table – how full are those drives based on your IOPS number? One of the interesting conversations I have with customers is when sizing a disk pool for IOPS, you need to consider how full you plan to run your array. ie) I’m buying 10TB’s of capacity, i know I have 8TB’s of data i want to migrate over, so that’s 80% full out of the chute. If we are sizing the system to hit certain IOPS peeks, you must take into consideration the IOPS drop that comes with a drive that gets above 70 to 80% utilized correct? In most cases, customers are running closer to 90% and then are surprised to see performance problems. IOP Pools can go from FANTASTIC to HORRIBLE pretty quick and all the sizing in the world can’t help a customer that wants to use up every bit of the capacity they purchased !!!
So I’ll ask the group, when you do this sort of sizing, what capacity utilization (%FULL) number do you use?
@Chad & @ Keith – I know there’s a solution to that which is called Cache however how often do you see a sales person tell the customer well I just saved you $ 25.000 worth of disks and I want to sell you an $ X of cache? Not likely to happen, in fact I’ve seen this a couple of times already. Again, I think dedupe has its place but there’s a cost associated to it which people should be aware of. And yes I know you can add those modules afterwards but that changes the TCO and the game.
@Tommy , as mentioned these are just averages in a worst case scenario. I simplified things and did not take utilization into account. We(people designing virtual infrastructures) need a baseline to work with and that’s why I wrote this article. (And because I had nothing else to do during my holiday ;-))
Again, thanks everyone for commenting! A lot of useful info here.
@duncan – great simple, reference blog post! I have something similar scratched out on a notebook cover.
@others – Way to ruin a good and simple blogpost with great information. 😉
Guy’s nice discussion 😉
I have been looking all over but can’t find my original source.
——–
I remember reading a while ago that as a rule of thumb you could state that the performance hit for RAID5 vs RAID1 on today’s modern RAID controllers is negligible.
Chad’s post elaborates on that somewhat but is this a correct statement?
Taking with it the responsibility for the consultant to check his assumptions when reaching certain performance thresholds ofcourse 🙂
@MartijL
Without advertising for my own blog.
http://www.mikes.eu/index.php?option=com_content&view=article&id=167:a-bunch-of-disks-in-raid-5&catid=39:business-continuity-and-availability&Itemid=60
This is also an approach that is less technically and talks about RAID5 vs RAID1 and performance vs. disk capacity as well. I know on the other hand there are still differences.
@ chad sakac and @ duncan.
isnt is possible to blog an example of a low entry emc box to let us see that the maths are different for a storage box ?
i always hear the same things from storage guys that the cache and raid doesnt matter anymore. for me as an vmware consultant it is always hard to get real answer about how the storage is setup and what the real specs are.
@Bjorn Bats – Absolutely. Rather than having me do it (as an EMCer), I’ll get a small EMC array to Duncan to play with alongside his RAID stuff.
Stay tuned….
@MartijnL – I wouldn’t say that parity RAID has no penalty on a modern array, only that assuming the worst case isn’t accurate either (due to cache and storage processor decoupling of host IO to backend disk IO, and write coalescing and very fast parity calculations.
To be clear, when you look at the sizing guides and internal tools we use to generate customer configs within EMC, we actually assume a pretty negative scenario (a conservative approach along what Duncan was pointing out initially). Sometimes we get hammered for this (a competitor might not be as conservative), but in general, it’s a good way to make sure that the performance is better than expected, not worse.
In general, storage vendors tend to oversell the effects of cache. Does it help? ABSOLUTELY. A basic (and I’m trivalizing it a lot here) example to remember that illustrates the danger of overselling cache effect:
Let’s say you have a large write cache – 100GB in size. IOs are coming in at the rate of 10000 IOps (IO size is 64KB, so that’s 65MBps per second – not a ton) The write cache will fill in about 25 minutes of steady state work. Now lets say your backend disks can only “sink” (i.e. enough spindles such that the IOps per spindle, coupled with RAID losses) 6000 IOps. Well, once the write cache is full, performance will nosedive by 40% because the host will be exposed directly to the backend disks (the write cache is committing the IOs as fast as it can). Would a larger write cache help? Only in the sense that the “buffer time” would be a bit longer. When an array is operating in steady state – the write cache can only absorb write BURSTS. Read cache can actually ELIMINATE read IOs (for cacheable reads).
Moral of the story – you better size the spindle count to be able to handle the steady-state write workload. Which is why the read/write mix in things like VDI workloads matter (but of course, more generally with all workloads) a lot.
Merry Christmas, and Happy Holidays all!
— Following Chad & Keith’s lead here… I’m with NetApp —
Duncan,
Thanks for posting this article it has sparked great discussion. I believe this topic is so relative as many VI admins are beginning to understand the nuances around storage.
I would like to take the discussion beyond the calculation overhead required for data protection (RAID), as there are many additional factors (as others have mentioned). Let’s consider some basic storage constructs.
Disks offer capacity (GBs) and performance (IOPs)
RAID offers protection (# of simultaneous failures) with a cost penalty to implement (IOPs)
Array cache enhances performance (IOPs) by serving reads from memory providing performance for writes.
Maybe a practical way to discuss storage IO is in a broader sense at an architectural level where we can begin by looking at a specific data type. In this manner it allows us to analyzing the properties of the storage construct specific to the data set.
For example, let’s take a shared datastore. We know this is probably our largest data set in our VMware environment, and consists of multiple VMs each with low to moderate IO needs.
Which RAID type should one use? RAID 6, 10, and DP all sound ideal for the consolidated data set as these three types provide protection in the case of a double disk failure. This level of ad protection ensures that a double disk failure doesn’t halt the operation of multiple VMs. Could one use RAID 5, sure, but let’s agree that in doing so one needs to address the mathematical reality that eventually they will lose data (this is not my opinion – view the stats on any disk drive and do the math). RAID 6, 10, and DP have varying RAID overhead in terms of IOPs (where RAID 10 and DP stand out), but also in terms of RAID capacity overhead (where RAID 6 and DP are very efficient and practical). Which does one choose?
Can’t one do this with SSD, I mean it offers 6000 IOPs per drive? – Sure, if one you have $$$$, RAID 6, and thin provisioning; however the gotcha is the storage efficiency of thn provisioning (and linked clones) is lost after the system go live (remember that data deleted in the GOS is still data on the array).
PAM isn’t free and as such the expense of buying it will rule it out. – First intelligent caching (deduce aware cache) is available in every array powered by ONTAP, so you get the benefit without PAM (PAM increases the amount of cache to insane levels). PAM gets positioned all of the time, because it is unique to NetApp and frankly because its pretty cool. As most customers realize ~70% saving with deduce (for virtual servers) typically the IOP requirement of shared datastores is meet by the existing disks and intelligent caching. PAM is a requirement for VDI, should be considered when looking at more than 2,000 consolidated VMs, or when one begins deploying enterprise apps like email and databases into a sizable environment. PAM isn’t free, but it provides a number of the benefits of SSD at a fraction of the price of SSD.
Do you sense a theme in what I’m writing?
Now if your storage array adds dedupe for VMs (NetApp SAN & NAS) or compression (EMC NAS) do you have enough IOPs in the disks to meet the IOP requirements of the stored VMs? Is the IOP value effected by RAID? What about by cache, the effective cache hit ratio, and deduce aware cache? You should also ask, what is the IO overhead for deduce and compression? For deduce (NetApp) the overhead is zero. in fact, performance with deduce is actually higher than without as the cache hit ratios are shared across all VMs and net an effect of an exponential capacity increase in the amount of data stored within cache. My understanding is that compression (EMC) requires a block range of the file to be copied, uncompressed, and then accessed… I guess this means one would need additional disk capacity reserved for the decompress stage, but maybe Chad can clarify. I’d have to imagine that the I/O overhead of compression would be 10%-20%.
If one uses traditional storage arrays one has to make a lot of choices around a number of technologies as no single RAID technology meets the goals of providing high availability, high utilization of the physical resource, and performance especially when serving a dense data set (by dense I am referring to deduce, compression, thin provisioning, linked clones, etc). The technology a storage array provides need to be very non-traditional and our customers believe that the combination of RAID-DP, deduce, intelligent caching (both in the array and with PAM) meet all of these goals with a reduced footprint. If one’s can’t get these features form their array then they soul virtualize their existing arrays with a NetApp vSeries (it’s the same as virtualizing a server with ESX/ESXi – allows you do more with less).
I’s sorry for the plug I just shared, but when speaking NetApp we are the odd guys with the very different technology in the storage industry. Don’t take my word for it just ask VMware engineering.
(I apologize for any typos I missed)
Happy holidays
Vaughn
Ugh.. looks like an auto spell check may have changed the word ‘dedupe’ with ‘deduce’ – sorry about that
Vaughn – First of all, merry christmas, happy holidays and and happy new year! I’m glad to see we’ll still be going back and forth in 2010 🙂 For anyone else who isn’t interested – please skip this comment.
(man, at this point, event **I’m*** tired of this, but can’t leave the comment out there without a response)
I try like gangbusters to avoid my comments on someone else’s blog (heck even my own) to avoid coming across like an EMC commercial (even going so far as to give props to my competitors, and even helping out our joint friend Keith above). But, based on the commercial comment, I have to respond.
I would bet dollars to donuts that Duncan’s original (being part of VMware PSO – and often called in when customers are having troubles) intent on this post was to note that IOPs matters, not just capacity, as array vendors have a tendency to overposition features. In fact, based on Duncan’s comment: ” however how often do you see a sales person tell the customer well I just saved you $ 25.000 worth of disks and I want to sell you an $ X of cache? Not likely to happen, in fact I’ve seen this a couple of times already”… well, I would bet that this post (trying to call out that backend spindle count matter) was because of dedupe being overpositioned and a customer not having enough backing spindles, but oodles of capacity.
I’ll come back to my earlier comment – I don’t understand why NetApp positions PAM as an alternative to SSDs, when (at least from where I sit – which I’m sure has bias) they are adjacent. PAM is use of solid-state non-volatile flash (and in earlier generations volatile DRAM) memory as an extension of filer RAM for more cache. Like I said – cache is good, and more is generally better. The application of dedupe to effectively raise the amount of cache – I wouldn’t say a bad thing about it – good for NetApp innovation in that area. For workloads which are highly affected by cache, EMC must respond with larger caches (and we have arrays with caches up to 1TB in size), and then customer do the usual vendor decision making process (sometimes we win, and sometimes we lose).
But – as the thread above discusses, write cache acts as a buffer for incoming IO. If you don’t have enough backing spindles to handle the steady state write IO workload, eventually (and eventually is a short time – enough time for the array write cache to fill) the write performance becomes largely gated by those backend disks.
NetApp absolutely has a many technology innovations, and many that are different than others. The fundamental one being to make everything run on top of the core elements of a filesystem, thus all data presentation (both NAS and block) models sharing functionality and features. On top of that, great innovation around pointer-based approaches layered on top of the basis of WAFL – in the early days, snapshots, and later another great example by being first on the market with production storage block-level dedupe.
But, to think that NetApp has an exclusive hold on “being different” – man, that’s a bit of hubris. I’ll hit a few (and other folks – if you want to chime in, go ahead):
– 3Par – unique with hardware based approaches and leading innovation around thin provisioning and scale-out.
– EqualLogic – unique introduction of scale out approach particularly with the first use of iSCSI redirection for scaling out iSCSI connections and bandwidth.
– Lefthand – unique introduction of VSAs as a production platform (using software mirroring and volume management to handle ESX server failures)
– Compellent – unique introduction of automated tiering
– Copan – unique first use of very dense platforms for “cheap and deep” use cases
– Data Domain – unique application of datadedupe and purpose-built internal filesystem construction for inline dedupe – which turned out to be the best bar none for the backup to disk use case (which requires oodles of ingest rate).
– EMC – unique introduction of CAS, still unique with COS, MPFS, and of course the leading the way with use of SSDs. And, AFAIK – first introduction of production compression in a mainstream storage array. Which alongside deduplication are BOTH data reduction technologies – each saving the customer money (and of course different). Sometimes file-level dedupe is extremely space/compute efficient (in the case of general purpose filesystems for example), sometimes it is not. Every data reduction technique has a varying set of advantages and disadvantages.
– HDS – the first to really embrace the idea of placing a “array in front of an array” for heterogenous storage virtualization. NetApp vFilers follow this idea.
FYI (and important for technical accuracy) – Celerra NAS does both a deduplication (for indentical files) and compress (within and across files). The compress is done in memory and only on blocks as they are read, and are generally not stored on disk in some fashion. This is not a “zip” but a patented compression algorithm which came from Recoverpoint’s WAN compression codebase and was integrated into Celerra. Performance impact varies. In general, it has about a 10-20% impact on a mixed IO workload. In some cases, performance actually improves, but in general, it’s not bad to assume that 10-20% read impact. There is no write impact as the process is a background process (similar to NetApp Dedupe in that regard, though the Celerra dedupe/compress runs all the time, doing work when there is free CPU cycles, and idle when not). Celerra dedupe has been mainstream for about a year now, with most customers seeing about a 40-50% savings on general purpose NAS (filesystem) use cases. Until the most recent DART update, large (>200MB) or very active files were not compressed – so it had little to no effect on NFS exports used in the VMware use case (dominated by large VMDK files). The current DART rev lifts that restriction, and can save about 30-40% on top of thin provisioning in the VMware on NFS use case.
BUT – back to the point of the article is that this is a CAPACITY saving function (more GB per $). It assists on performance marginally. You better have enough backing IOPs – particularly for those writes. I fully expect NetApp to FUD our approach (as an example, the comment which I paraphrase as “ours is dedupe, theirs is compression”). They are both data reduction techniques. Technically, yours is a block dedupe, ours is a file dedupe + variable compression. On varying datasets, they have varying capacity savings efficiencies. Most customers have many different datasets.
I personally wonder if that hubris is why NetApp doesn’t do SSDs as an option along with PAM – perhaps it’s inconceivable there (thinking of that dude in Princess Bride who ran around saying “inconceivable!”) that good ideas might come from elsewhere. I’m glad I don’t think that way, and man, I’m glad EMC doesn’t think that way. When we see a good idea done somewhere else, you can count on us trying to see how we could provide similar or adjacent value to our customers in a way that can be done in our technologies.
BTW looking at the list of innovations from all the folks above, that’s why we’re making thin our default provisioning model and adding stuff like zero reclaim, introducing compression/dedupe (first on NAS, but not ending there), just added our first “30 disks in 3U” dense configurations, FAST, disk spin-down, acquiring Data Domain, and so on and so forth – oh and yes, making sure we hit fundamentals (like keeping current with 2TB SATA and SSDs).
Innovation comes from everywhere – and the most important attribute is adaptability to change, IMO.
That whole use of the phrase “traditional storage array” when describing the rest of the industry smacks of that hubris. NetApp’s architecture has been around for 20 years now – and sure, has had innovation on top of innovation – but still based on the core from 20 years ago. Now, ONTAP 8, and the integration of Spinnaker represents the first big architectural change in a while – and I’m personally and professionally interested and am watching closely – it’s important to have strong competitors in our (or any) industry.
Each of us has advantages, and disadvantages – strangely perhaps, the storage industry never moved towards a common very standardized design (like servers). We’re all wildly different. VMware engineering has the “joy” of trying to work with all of our “uniqueness”, something I know is difficult for them.
wow, what a lengthy replies and that during Christmas. Showed them to my wife as it proofs I am not the only Technology Idiot on this planet as she always seems to believe. 🙂
Anyway, Chad is correct. I am merely trying to point out that IOps is often overlooked. Especially by the sales team. I am not talking about the EMC or NetApp sales team and pre-sales engineers as these usually are more than capable to create a good offering. I am not going to point fingers as it might get messy. But the fact is that we(VMware PSO) get pulled in a lot for performance issues, which 9 out of 10 times are related to overcommitment or Storage. When it is storage it is mainly due to a misinformed customer and a misleading business case.
It is easy to calculate capacity and with the correct tools even Deduplication can be taken into account. But it seems to be very difficult to take IOps into account. Especially when we are consolidating workloads to a single LUN and indeed in the case of VDI it seems to be more difficult as the workload is less(no it it isn’t) predictable. With less predictable I mean that although it seems to be predictable and something that can be verified in a PoC it is often overlooked and miscalculated.
Again, this is not intended as a deepdive. It is “worst case” scenario, and a start for us Consultants/Architects.
I do have two EMC arrays, a NetApp Filer and we are currently building our test lab. When it is finished and I can find the time I will try to do a performance test based on different raid-levels. Hopefully I will have an update soon.
Maybe you can help me – I’m always asking myself what the IOPS literature values are based on. For example, the table in this article states that an 15K drive provides 175 IOPS. What workload is this based on? 4KB random writes? 4KB random reads? 8KB sequential reads? Just specifying a value is pretty worthless unless we know on what kind of workload it is based on. I’m always wondering about this while reading about those values. Any idea? Is there a “hidden standard” for these values that I’m not aware of?
@ Michael
The IOPS value usually relates to random IO. And since random IO is mostly limited by the speed of the head moving, the actual IO size makes little difference.
Check out: http://blogs.zdnet.com/Ou/?p=322 for a brief run through the maths.
In general:
– VMware tends to be very random in practice (multiple OS’s & apps all hitting the same disk).
– For VMware, I assume an average IO size between 4k & 8K. Your mileage may vary! 🙂
I love these kind of discussions, they through up such a wide range of views, for my self it has become more influential in the way i design over the last year.
Chad mentions the EMC CSPEED team, i have recently been accepted into this arena and on the back of this i will be perfroming some varied workload testing in our EMC solution centre from the new year.
The area i am keenest to test is the VDI space where IOPs can be a killer due to density of VMs, 1 point i’d like to chip in is the change i have seen for MS partition alignment, i was looking for a reference document for a customer and it would appear that MS have changed their stance and now recommend 1024 for all platforms not just 2008 (2003/XP/2000)http://support.microsoft.com/kb/929491 (this document got revised in June 2009).
Duncan:
Good topic as I’ve been spending a considerable amount of time looking at statistical performance prediction using disk-based IOPs to extrapolate filer performance (predictions). Richard Elling has a great post about how the RAID/IOPS factors in a ZFS world while introducing another axis in the performance curve – MTTDL (mean time to data loss), which is all to often sacrificed on the pyre of BW/IOPS optimization:
http://blogs.sun.com/relling/entry/zfs_raid_recommendations_space_performance
Likewise, this illustration in ZFS mirroring contradicts Chad a bit in his 4 vs 6 disk concurrency evaluation of RAID1 vs RAID6. While note necessarily unique to ZFS mirrors (all disks can source read IO, however this parallelism is not *always* observed as Chad is likely implying), the contradiction underscores the importance of understanding the underlying architecture and behaviour of the array system and how it puts each unit IO to use.
In my mind, the most important factor to understand in contemplating array sizing for performance is how read/write caching will influence the usable IO of a storage pool (group of disks). Here, assumptions could be made about write coalescing provided cache/spindle sizing is balanced where the underlying goal is conversion of random IO patterns into sequential ones (i.e. writes acknowledged by the array prior to being committed to disk) by employing non-volatile caching mechanisms (nvram or SSD). This makes understanding SSD performance a bit more important.
Looking at the SSD estimate, I wondered if 6000 IOPS was a reasonable number to use, looking at my recent design cases. While STEC-based SSD’s may average towards 6K IOPS, perhaps small array builders (and embedded arrays) would be taking Intel SLC “enterprise” SSDs to task. For X25-E disks, the “write-side” of the IOPS is only rated at 3300 IOPS: about 1/2 of the calculate performance based on latency (somewhere around 6300 IOPS), implying the impact of flash management. Likewise, the “rated” read IOPS characteristic is typically given at 35K.
In my mind, the disparity of performance (10x) between read and write nullifies the validity of the averaging method for SSD’s, and could lead to some really bad results in random-write oriented applications (i.e. MS SQL temp pools, etc.) I’m with Chad in being unable to get to the simplified approach because I keep hearing the little “exception devils” in the back of my head. For me, I feel more safe in boiling things down to either individual read IO and write IO behaviours (dual performance tables per disk type), or to write-only behaviours for worst-case estimates (single performance table per disk type).
That said, I like to track my performance estimates of sequential (read bias), random (write bias) and average IOP (designed mix) estimates to determine how close to the mark we get in the final system. Likewise, it gives us a baseline target for array evaluation. Given that your analysis falls out of Herco’s rather helpful tech note on VDI storage, a bias towards (random) write must be the general rule in VDI storage sizing (performance).
What I liked about your evaluation was how you turned the exercise on its ear: implying aggregate array IO from the client demand. This approach actually helps in looking at raid device queue sizing in ZFS-based pools as a limiting factor where large numbers of disks are used to back relatively few presented LUNs (ZFS evil tuning guide). Conversely, we look at the reciprocal approach by flipping your multiplier to a divisor (or multiplied fraction) and calculating the delivered IOPS of the storage system.
Interestingly, if you look at the random write IOP scaling of RAID5/6 is how it tends to goe as a factor of N/(N-1) (or N-2) where N = number of disks in the raid set: as more disks are added to the set, the random write performance approaches that of a single disk. This is where alternative approaches and/or write coalescing become increasing important, because re-characterizing random IO as sequential IO can get these raid sets back to scaling with disk count.
Not to take away from RAID-DP, but it doesn’t get write performance for free: it does lose something to RAID5/6 in terms of read IOPS where small(er) numbers of disks are used. While the RAID5/6 can grab a stripe from all disks in a sequential read, RAID-DP loses the IOPS of the two parity disks (N-2) – and that’s the trade-off yielding the higher write IOPS.
Cheers!
@Colin – good addition to the thread. Perhaps a mistaken assumption on my part based on where I spend the bulk of my time as all EMC arrays can read from all elements of a mirror or a RAID stripe set, but as you note, perhaps not true as a general statement (I can’t comment on that either way).
I must confess interest in ZFS – will poke at it in 2010. While obviously an EMC competitor, I hope that Oracle doesn’t bork it – some good innovation there, and innovations come fast and furious. Very curious about their inline dedupe, they have a very different approach than both NetApp and EMC Celerra.
Wow, good discussion guys. A detailed blog post on this would be fantastic.
On the I/O penalty, would the additional I/O’s for example on a RAID-1 (2) occur simultaneously? Thus the latency would be the same as a single disk?
Why does the IOps halve? Wouldn’t the same number of I/O’s be required on each disk to write out all of the data? (in raid 1 example)
How do you approach the sizing of I/O requirements for customers? As suggested above I think most integrators go after the capacity in terms of the sale and the engineers (myself) are often left holding the can to try and make the infrastructure perform once deal is done.
As an aside… Chad, I really appreciate your balanced comments. I have recently moved from an EMC Partner to a netapp partner (as a VMware engineer) but am trying to learn how everybody works so I can provide the best virtual environments to my customers sitting over any particular storage.
I think that Daniel Myers has hit the nail on the head. In the real world, how do you approach the sizing of I/O requirements for customers? This is what it all boils down to and depending on answers may explain why Duncan et al gets called in because of performance issues.
The correct formula is: 1/(average latency in ms + average seek time for read or write in ms)
I have a practical example at http://deinoscloud.wordpress.com/2009/09/11/understanding-disk-iops/
Cheers,
Didier
Won’t sizing have to consider the size of the I/O? If doing large I/O’s the IOPS will be much smaller than doing small I/O’s?
What I/O size are we assuming for calculations?
Yes it does matter, but I am talking about “rough” estimates to use for a simple calculation.
Great discussion guys and happy new year!
Duncan, I am still confused about RAID DP write penalty being 2, which is same as mirroring. Doesn’t RAID DP needs to write double-parity? One new write plus two parity writes, so the penalty should be 3, isn’t it? Please advise where I got it wrong, many thanks!
Some great discussion here. zStorageAnalyst that’s a good question. I’ve been told by people I trust that DP is superior to RAID 6, I suspect it has to do with drive versus stripe for your parity information.
“traditional storage array” – I think this is a big deal to NetApp and for good reason. For a long time lots of high end storage vendors (EMC I’m looking at you but EMC certainly was not alone) in portraying NetApp as “the NAS guys – put your home directories there but update your resume before depoying anything important”. As if the architecture is the goal, not getting data to users in a value producing fashion. I’m a NetApp user because they still allow me a flexibility to do what I want with a single large array at a cost that approaches reasonable. I think the “traditional storage array” comment is more laughing at FUD than anything else.
And I’m looking forward to watching ZFS develop. Hopefully it does not end in a legal boondoggle, having everyone work together seems to be more profitable, at least to me as a customer. If the replication works as advertised and is reliable I could be a Sun customer on our next refresh cycle, we’ll see.
Vendors need to focus more on adding value and less on how to lock customers into their products. I think Microsoft is risking making itself irrelevant if it does not wake up, for instance – the cost of migrating off a platform is not value and my current company will be using MS products for a long time because of how deeply imbeded they are in our systems.
Jeremy, interesting that you mentioned ZFS.
My understanding is that ZFS does RAID like WAFL, new writes instead of overwrites.
I haven’t seen any concrete answer for why RAID-DP write penalty being 2, so let me keep thinking along my line for now.
For RAID-Z2, the write penalty would be 3, same as what I think for RAID-DP.
For RAID-Z3, the write penalty would be 4, one new write + 3 parity writes.
Well, if RAID-DP penalty is really 2, I would be totally off here.
Anyone care to agree/disagree? Thanks.
This RAID-DP stuff is getting into my head… I have been reading and reading, saw multiple factors for the NetApp RAID’s super performance – the use of NVRAM, writing in new blocks, the extra parity compared to RAID 4 only carries 2-3% overhead… but did not see anything about the write penalty factor. And I guess ZFS RAID-Z does its own magic as well, beyond my comprehension to conclude the write penalty factor. I give up. 🙁
Hope someone more knowledgeable can tell me the answer.
have you had any issues with you ix4-200d locking up? mine has twice and i’m now moving off it. Iomega support was ZERO help…. uh…reboot… uh….i dont know…uh reboot.
I think 175 IOPS for 15k is VERY conservative, Seagate 15k.7 drives are rated at 3.4/3.9ms average read/write latency, so for 50/50 workload that works out to ~3.65ms average giving ~275 IOPS. HP has a line of 2.5″ 15k drives with an ~2.6ms average latency or almost 400 IOPS per spindle. On my virtualized arrays I generally see average latency from host to storage within 10% of spec sheet numbers for uncached access.
Hi guys,
This is a superb article, especially as it is targeted at the VMware community, you ignore storage to your peril as a virtualization expert.
re: ZFS, RAIDZ has a write penalty of 2 because as it has a dynamic strip width all rights are full stripe (as chad says this is optimal,for writes smaller than full stripe RAID five has to
* read old data
* read old parity
* write new data
* write new parity
I would guess RAIDZ(N) therefore had a write penelty of (N-1). With the new ZIL/L2ARC in SDD stuff you can get real good performance with off the shelf hardware in Nexenta/OpenSolaris.
I do not know if WAFL uses something like dynamic stripe width for RAID-DP or avoids the fourfold penalty somehow else.
re: approximate IOPS figures for a single disk. I disagree with the statement
“In short; It is based on “average seek time” and the half of the time a single rotation takes. These two values added up result in the time an average IO takes.”
Why add them to get the time taken? Don’t they happen in parallel?
I blogged about it recently as I keep seeing people reference that ZDnet article and I think it is wrong (it does not invalidate your advice a bit, just adjusts the numbers slightly, but I used to be a Maths teacher and have a bit of a bee in my bonnet about it 🙂 )
http://www.thattommyhall.com/2010/02/15/iops/
Tom
Ha ha,
Can I retract that comment about adding:- at the point the seek is done, you need to wait for the platter to spin into place, on average half a turn (the latency time). They do therefore happen in sequence! (If it was not for those pesky disks always spinning, I’d have been right)
*Slinks off embarrased*
Oh and the N-1 should be N, I’m going to bed!
I mean N+1!!!! FFS
disclosure: IBM advanced technical expert & infrastructure systems architect, working for a business partner
No product specifics or advertisements here!
interesting math & discussion!
Some adjustments:
* Single drive, classic avg i/o time is
avg. seek + 1/2 rotation + _data transfer time_
There are multiple SCSI-commands for a single I/O. FC & SAS are based on SCSI.
* RAID-5 or similar array:
The four I/Os (two reads, xor modification, two writes) are with two disks (here 1x data, 1x parity), one read plus one write to each of them.
If you are lucky, the writes do not have to seek, since the disks read the to-be-modiefied-sector just before – increasing possible RAID I/O numbers!
On the other hand, if the two drives to be read have outstanding I/Os to be done before, the cache destage has to wait – as just-incurring reads do, also, raising response times!
Full stride writes are likely to be found with database loads or multimedia, but not in OLTP environments.
* For RAID-6 or the like
Even worse, since six I/Os are neccessary
* enterprise subsystem:
Concurrent streaming I/O might saturate components bandwith for some time.
Concurrent random I/O might saturate controller CPUs.
* Write cache:
Most arrays have strategies when to flush some data from the write cache.
And, most-if-not-all arrays do not allow the whole (insert marketing-cache GBs here) cache for writes.
Most vendors sell you the whole installed memory as cache, when a big portion is required for OS and internal data structures.
Some vendors protect just a small portion of the cache for writes,
some decide by the attached operating system & failover mode, how much write cache to allocate for a LUN.
Some even mirror the read cache for reduced overall capacity.
* Advanced functions:
Thin Provisioning requires tables to describe which blocks are whre to find, and which are empty. These tables require memory and have to be securely written to permanent storage. Writing to ‘new’ blocks is always slower than with a thick volume, since storage has to be allocated on the fly.
Flashcopy=Snapshot, and the like, might read original data when written blocks are smaller than the internal blocksize.
This is true, even if not using copy-on-write, since a small write has to be surrounded by it’s original data for a whole block.
Flashcopy=Snapshot deletion might induce severe read&write-activity on other systems.
Background scans, disk scrubbing, RAID rebuilds all increase subsystem load.
*** The most ignored factor is min/avg/max response time distribution:
When you issue an operation to an idle disk, you get what you calculate.
When there are 60 I/Os outstanding to a 33% utilized FC-15k disk, you wait 333 ms for the other I/Os to complete before your I/O starts!
Yours,
Ilja
Very cool informations, thanks a lot.
TOTAL IOps × % READ)+ ((TOTAL IOps × % WRITE) ×RAID Penalty)
Does anyone know the RAID Penalty for RAID-50 or RAID-60 or other RAID levels?
Very good discussion 🙂
When looking at storage arrays (instead of single disks): Isn’t it important to look at the relation between IOPS and average latency?
I just did some simple test using IOMETER:
– 8K, 55% Read, 80% Random (a typical Exchange 2007 workload)
– 12GB VMDK virtual disk
– Windows Server 2008 R2 with 2vCPU and 2GB RAM on vSphere4
– NetApp FAS2050 with 14x 15k FC drives (1 spare, RAID-DP)
Depending on the number of Outstanding IOs (queue depth) I get very different results:
-> #Outstanding IOs = 4: approx. 560IOPS
-> #Outstanding IOs = 16: approx. 930IOPS, but higher latency
Question: Which is the correct value for the disk performance in IOPS?
I have been looking for the same answer regarding the RAID Penalty for RAID50.
RAID 10 penalty = 2 (RAID 1 = 2 X RAID 0 = 1)
RAID 60 penalty = 6 (RAID 6 = 6 X RAID 0 = 1)
RAID 50 penalty = 4 (etc)
Yes?
Hi Volker.
You can search on the internet and find that for Virtual machines to perform test using IOmeter you need to put the size of the disk at 4 times the amount of Memery your VM has to saturate the virtual disks.
Otherwhise you will get unreliable results. For a Virtual disk on the machine on not a regular SAN connected to the VM you should get 70-90 IOPs.
Hope this helps with your results. For any kind of enterprise system you will need a separate array for the VM and for the VM storage or put them on separate theads on your SAN.
How is it the “penalty” is a multiplier. You seem to be saying that writes will be faster due to the penalty. Call me stupid, but shouldn’t you be dividing rather than multiplying?
@Joe: A simple example, in order for a single I/O to be written to disk in the case of RAID-5 it will need to write the parity blocks as well. So a 1 I/O will in real life be 4 I/Os meaning that if you need to drive large volumes of IOPS you will need to make sure that your backend (disks) actually will be able to cope with it.
Okay, so what you’re saying is that if I need 10,000 IOPS delivered with a 50/50 read:write ratio, I’d need a RAID 10 array that delivers
10,000(0.5+(0.5*2)) = 15,000 IOPS
or a RAID5 array that delivers 25,000 IOPS
or a RAID 6 array that delivers 35,000 IOPS
Do I have it right? That would definitely affect my choice of RAID types.
Correct,
Doesn’t SAN controller cache reduce the RAID penalty? If the cache is handling the 4 writes of RAID 5, should there still be a penalty?
Assuming that the cache is large enough to handle the writes and the backend IOPS are sufficient enough to handle the writes being flushed from the cache?
-MattG
When considering SAN storages which has read and write caches and SSDs along with the regular hard disks (raid) .. it should affect the iops.
Can we have a discussion on the disk requirements, possibly a good balance in terms of cost with respect to this scenario … ??
– Shalton
How do you get the raid penalty factor? Where does that figure come from? I don’t understand how you derived it, or where you got it.
Thanks,
Aleksey
Wouldn’t the penalty factor for RAID 5 depend on how many drives are in the raid group?
Nevermind, I found the answer and it is “no”. Further in-depth explanation can be found in the “raid 4” section of the original 1988 RAID paper.
Raid 5 write penalty IS dependent on the number of disks in the raid set AND the write size versus stripe size.
Say we have 12 disks in a raid 5 set with 64K stripe size. We want to write/update a 8K block in a larger file.
We need to read the 64K block where the 8K are embedded. Merge the 8K into the 64K block. Before writing we need to calculate the value for the checksum disk. For that we need to read the 10 disks (all disks minus party minus the one we already have read), calculate the new checksum and write the datablock with the new 8K and the checksum back to disk.
This way one write/update operation creates 11 reads plus two writes. A severe penalty of 1 to 13.
If we only had 3 disks in raid 5 with 8K stripe size, and we write/update 8K, we would need to read one and write two. A one to three penalty.
With 5 disk and 2K stripe and update/write 2K, it would be three reads and two writes. one to five.
It is someway simple to remember, if You want to go cheap on space wastage, You put many disk in the raid 5 or 6 set and pay penalty in the iops performance.
There is no such thing as a free lunch 🙂 Have fun.
Well done It was an excellent written piece. Perform continue when you are. We shall be excitedly waiting around.
I’d be interested to find out if you did any testing on your FAS2050 and what the results were. In theory the results should have come out better than RAID-10, though given that your results above were for 100% sequential write the RAID-5 could have been higher than they were for RAID-10 depending on the efficiency of the RAID controller.
In this particular case I think the lower result for RAID-5 might have been because the CPU wasnt keeping up with the parity calculations, rather than the read old data block, read parity block, write data block write parity block 4x penalty often cited for RAID-5. If the disk subsystem was caching the data and then overwriting all of the data in the disk stripe (aka full stripe writes), these dont incurr the 4x IO penalty as there are no read operations required as all the information required to create/update parity is sitting in the write buffer. In theory you can destage from the write cache to all the data disks simultaneously which gives parity RAID a theoretical peformance edge in these kinds of workloads.
It’s also possible that the filesystem you were writing to turned your sequential write workload into something more random at the back end (“normal” non write anywhere filesystems tend to do this for the metadata updates).
I wrote up a detailed analysis of the impact of RAID on write intensive workloads (specifically VDI) here http://storagewithoutborders.com/2010/07/19/data-storage-for-vdi-part-4-the-impact-of-raid-on-performance/ and I’d appreciate any comments you might have.
Regards
John Martin (aka @life_no_borders)
Raid 0 penalty should be 1 not 0.
Multiplyin writes x 0 would give us no IOPS needed for writes in raid 0.
Am I correct?
I’m a little confuse with this formula.
(TOTAL IOps × % READ)+ ((TOTAL IOps × % WRITE) ×RAID Penalty)
Where the Total IOPS comes?
Great information but I have a simple basic question please;
“The question of course is how many IOps do you need per volume”
This is my issue, how do I know or how can I determine the IOPS requirments. All I normally get is capacity or fast/slow storage.
Rick, you can audit your servers or desktops with software like Liquidware to see what kind of i/o you’re getting. You can also use calculators from the software manuf. for example Exchange, Microsoft will give you i/o requirements given you know a lot about the environment you’re going to support.
Hi. Good information, we have discussed an enormity with our supplier for the disk configuration that they brought to us for V7000 IBM solution, they chose 216 Hdd 300Gb 10K, theoretical as we believe that this configuration is worst performing in relation to an HP EVA6100 with 112 and 10K 146GB disks, they say the V7000 have new technology such as buss, cache, anyway we are very confused!!
Wouldn’t RAID 0 penalty be 1, not 0? I saw someone, already asking about that.
It does not contradict any of the findings / results and makes the formula correct for RAID 0.
Btw — I am aware that there are other web sites that say that RAID 0 penalty is zero, but that does not mean that it is correct.
Do an experiment, for RAID-0 plug in “0” for penalty in the formula and see what you get, and then try it with “1”.
AK
You are right Arkadius, RAID-0 has 1x write penalty.
the confusion is because ‘no penalty’ means 1x (and not 0x).
So the author should write 1x 2x 4x 6x 2x in the penalty column.
(he could also write +0 +1 +3 +5 +2 but the the formula must be written differently)
i hope it is clear
Great post (and clearly demonstrate why FC drives are being replaced with SAS or a mixture of SATA and SSD).
The major drawback of the post – it is only true for HDDs… SSD formulas (e.g. RAID) cannot just “scale” from the HDD ones. This calls for an equivalent post for SSDs.
Hello there! I know this is somewhat off topic but I
was wondering which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had problems with
hackers and I’m looking at options for another platform. I would be fantastic if you could point me in the direction of a good platform.
Hy Duncan, in the example where is the source of the 2400 IOPS?
HI Oscar,
The calculation is like
(1000 x 0.4) = 400
((1000 x 0.6) x 4) = 2400
(1000 x 0.4) + ((1000 x 0.6) x 4)
400 + 2400 = 2800 IO’s
Hope this help.
Thanks,
Mohammed.
Hello
I am a bit confused with Chad’s statement in an earlier comment:
“Think of an example – on a read, in a 8-disk R10 set, the contents can be read from 4 disks simultaneously – the other 4 disks simply have a mirror of the same data.”
That means that in RAID-10 with 8 disks each, I sum the 4 of them to take the total read IOPs. Or this has to do with large files – lets say a 1GB file will be split to 4 disks, instead of 8 (for raid 5) – but for small random requests all 8 disks will be used ?
Great info here but a bit overwhelming and probably more confused. I understand RAID penalties and IOPS and even R/W ratio’s, but now I’m not sure how I should really be sizing a SAN. My first question is how many IOPS, R/W ratio, and sequential vs random. Duncan, your example was simplified to make a point, understood, so how would you size for a customer? The one person I would love to ask, who was probably one of the most brilliant people i have met in the IT industry, has left his distinguished position.
I was continuing and looking for this question.Thanks JL for raising this question.
I collected IOPS from the physical servers (mixed of linux and windows) for storage sizing for transferring those physical server to the virtualized environment with vpshere 5. I used perfmon utility for windows servers (added physical disk read/sec and write/sec counters) and iostat command for linux servers.
All of my servers have 4-5 disks and have RAID-5 configured…..
I got the read write info (i.e. IOPS info):
total number of read/sec for windows and linux is 2400 (i.e. 80% read)
total number of write/sec for windows and linux is 600 (i.e. 20% write)
So I need at least 3000 IOPS from the shared storage. Please let me know, am I correct?
the 3000 IOPS are from my existing servers RAID-5.
So what will be the storage calculation for me? is like this:
(TOTAL IOps × % READ)+ ((TOTAL IOps × % WRITE) ×RAID Penalty)
( 3000 × 0.8 )+ (( 3000 × 0.2 ) × 4 ) = 4800
Should my storage should deliver 4800 IOPS?
Hasib
Well done Duncan..The post is very informative. It has been grabbing attention even after 5 years of posting. Thanks everyone for making the comments more informative than the original post… 😛