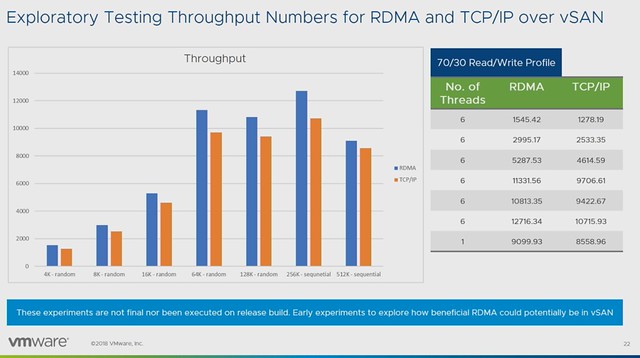
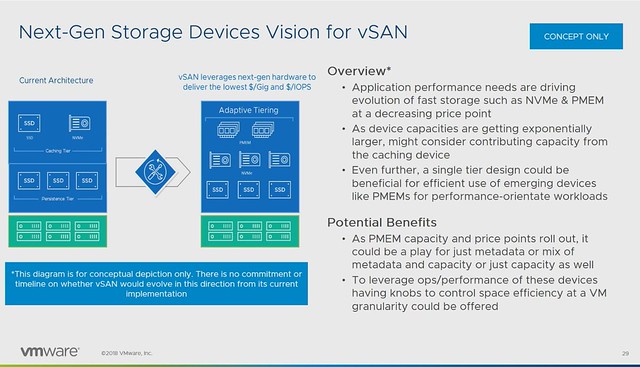
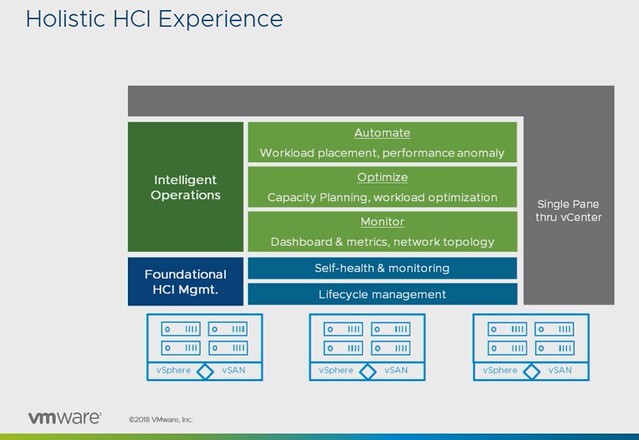
At VMworld, there were various sessions with vSAN Customers, many of which I have met in some shape or form in the past couple of years. Some of these stories contain some great use cases or stories. Considering they are “hidden” in 60-minute sessions I figured I would write about them and share with you the link where and when applicable.
In the Monday keynote, there were also a couple of great vSAN quotes and customers mentioned. Not sure everyone spotted this, but definitely, something I felt is worth sharing, as these were powerful stories and use cases. First of all the vSAN numbers were shared, with 15k customers and adoption within 50% of the Global 2000 within 4 years I think it is fair to say that our business unit is doing great!

In the Make A Wish foundation video I actually spotted the vSAN management interface, although it was not explicitly mentioned still very cool to see that vSAN is used. As their CEO mentioned, it was great to get all that attention after they appeared on national television but it also resulted in a big website outage. The infrastructure is being centralized and new infra and security policies are put into place, “working with VMware enables us to optimize our processes and grant more wishes”.
 Another amazing story was Mercy Ships, this non-profit operates the largest NGO hospital ship bringing free medical care to different countries in Africa. Not just medical care, they also are providing training to local medical staff so they can continue providing the help needed in these areas of the world. They are now building their next generation ship which is going live in 2020, VMware and Dell/EMC will be a big part of this. As Pat said: “it is truly amazing to see what they do with our technology”. Currently, they use VxRail, Dell Isilon etc on their ships as part of their infrastructure.
Another amazing story was Mercy Ships, this non-profit operates the largest NGO hospital ship bringing free medical care to different countries in Africa. Not just medical care, they also are providing training to local medical staff so they can continue providing the help needed in these areas of the world. They are now building their next generation ship which is going live in 2020, VMware and Dell/EMC will be a big part of this. As Pat said: “it is truly amazing to see what they do with our technology”. Currently, they use VxRail, Dell Isilon etc on their ships as part of their infrastructure.
The first session I watched was a session by our VP of Product Management and VP of Development, I actually attended this session in person at VMworld, and as a result of technical difficulties, they started 20 minutes late, hence the session is “only” 40 minutes. This session is titled “HCI1469BU – The Future of vSAN and Hyperconverged Infrastructure“. In this session, David Selby has a section of about 10 minutes and he talks about the vSAN journey which Honeywell went through. (If you are just interested in David’s section, skip to 9:30 minutes into the session) In his section, David explains how at Honeywell they had various issues with SAN storage causing outages of 3k+ VMs, as you can imagine very costly. In 2014 Honeywell started tested with a 12 Node cluster for their management VMs. This for them was a low-risk cluster. Their test was successful and they quickly started to move VMs over to vSAN in other parts of the world. Just to give you an idea:
- US Delaware, 11k VMs on vSAN
- US Dallas, 500 VMs on vSAN
- NL Amsterdam, 12k VMs (40% on vSAN, 100% by the end of this year!)
- BE Brussels, 1000 VMs (20% on vSAN, 100% by the end of this year!)
That is a total of roughly 24,500 VMs on vSAN, with close to 1.7PB of capacity, with an expected capacity of around 2.5PB by the end of this year. All running on vSAN All Flash the Dell PowerEdge FX2 platform by the way! Many different types of workloads run on these clusters. Apps ranging from MS SQL, Oracle, Horizon View, Hadoop, Chemical Simulation software, and everything else you can think off. What I found interesting is that they are running their Connexo software on top of vSAN, in this particular case the data of 5,000,000 smart energy meters in homes in a country in Europe is landing on vSAN. Yes, that is 5 million devices sending data to the Honeywell environment and being stored, and analyzed on vSAN.

David also explained how they are leveraging IBM cloud with vSAN to run Chemical Plant simulators so operators of chemical plants can be trained. IBM cloud also runs vSAN, and Honeywell uses this so they can leverage the same tooling and processes for on-premises as well as in IBM Cloud. What I think was a great quote, “performance has gone through the roof, applications load in 3 seconds instead of 4 minutes, they received helpdesk tickets as users felt applications were loading too fast”. David works closely with the vSAN team on the roadmap, and had a long list of features he wanted in 2014, all of those have been released now, now there are a couple of things he would like to see addressed and as mentioned by Vijay, they will be worked on in the future.
A session I watched online was “HCI1615PU -vSAN Technical Customer Panel on vSAN Experiences“. This was a panel session that was hosted by Peter Keilty from VMware and had various customers: William Dufrin – General Motors, Mark Fournier – US Senate Federal Credit Union, Alex Rodriguez – Rent A Center, Mariusz Nowak – Oakland University. I always like these customer panels as you get some great quotes and stories, which are not scripted.

First, each of the panel members introduces themselves and followed by an intro of their environment. Let me quickly give you some stats of what they are doing/running:
- General Motors – William Dufrin
- Two locations running vSAN Thirteen vCenter Server instances
- 700+ physical hosts
- 60 Clusters
- 13,000+ VMs
William mentioned they started with various 4 node vSAN clusters, now they by default role out a minimum of 6-node or 12-node, depending on the use-case. They have server workloads and VDI desktops running, here we are talking thousands of desktops. Not using stretched vSAN yet, but this is something they will be evaluating in the future potentially.
- US Senate Federal Credit Union – Mark Fournier
- Three locations running vSAN (remote office location
- 2 vCenter Instances
- 8 hosts
- 3 clusters
- one cluster with 4 nodes, and then two 2-node configurations
- Also using VVols!
What is interesting is that Mark explains how they started virtualizing only just 4 years ago, this is not something I hear often. I guess change is difficult within the US Senate Federal Credit Union. They are leveraging vSAN in remote offices for availability/resiliency purposes at a relatively low cost (ROBO Licensing). They run all-flash but this is overkill for them, resource requirements are relatively low. Funny detail is that vSAN all-flash is outperforming their all-flash traditional storage solution in their primary data center. Now considering moving some workloads to the branches to leverage the available resources and perform better. Also a big user of vSAN Encryption, considering this is a federal organization that was to be expected, leveraging Hytrust as their key management solution.
- Rent-A-Center – Alex Rodriguez
- One location using vSAN
- 2 vCenter Server instances
- 16 hosts
- 2 clusters
- ~1000 VMs
Alex explains that they run VxRail, which for them was the best choice. Flawless and very smooth implementation, which is a big benefit for them. Mainly using it for VDI and published applications. Tested various other hyper-converged solutions, but VxRail was clearly better than the rest. Running a management cluster and a dedicated VDI cluster.
- Oakland University – Mariusz Nowak
- Two locations
- 1 vCenter Server instance
- 12 hosts
- 2 clusters
- 400 VMs
Mariusz explains the challenges around storage costs. When vSAN was announced in 2014 Mariusz was intrigued instantly, he started reading and learning about it. In 2017 they implemented vSAN and moved all VMs over, except for some Oracle VMs, but this is for licensing reasons. Mariusz leverages a lot of enterprise functionality in their environment, ranging from Stretched Cluster, Dedupe and Compression, all the way to Encryption. This is due to compliance/regulations. Interesting enough, Oakland University runs a stretched cluster with a < 1ms RTT, pretty sweet.
Various questions then came in, some interesting questions/answers or quotes:
- “vSAN Ready Node and ROBO licensing is extremely economical, it was very easy to get through the budget cycle for us and set the stage for later growth”
- The Storage Policy Based Management framework allows for tagging virtual disks with different sets of rules and policies when we implemented that we crafted different policies for SolidFire and vSAN to leverage the different capabilities of each platform (reworded for readability)
- QUESTION: What were some of the hurdles and lessons learned?
- Alex: We started with a very early version vSPEX Blue and the most challenging for us back then was updating, going from one version to the other. Support, however, was phenomenal.
- William: Process and people! It is not the same as traditional storage, you use a policy-based management framework on object-based storage, which means different procedures. Networking, in the beginning, was also a challenge, consistent MTU settings across hosts and network switches are key!
- Mariusz: We are not using Jumbo Frames right now as we can’t enable it across the cluster (including the witness host), but with 6.7 U1 this problem is solved!
- Mark: What we learned is that dealing with different vendors isn’t always easy. Also, ROBO licensing makes a big difference in terms of price point.
- QUESTION: Did you test different failure scenarios with your stretched cluster? (reworded for readability)
- Mariusz: We did various failure scenarios. We unplugged the full network of a host and watched what happened. No issues, vSphere/vSAN failed over VMs with no performance issues.
- QUESTION: How do you manage upgrades of vSphere and firmware?
- Alex: We do upgrades and updates through VxRail Manager and VUM. It downloads all the VIBs and does a rolling upgrade and migration. It works very well
- Mark: We leverage both vSphere ROBO as well as vSAN ROBO, one disadvantage is that vSphere ROBO does not include DRS which means you don’t have “automated maintenance mode”. This results in the need to manually migrate VMs and placing hosts into maintenance mode manually. But as this is a small environment this is not a huge problem currently. We can probably script it through PowerCLI.
- Mariusz: We have Ready Nodes, which is more flexible for us, but it means upgrades are a bit more challenging. But VMware has promised more is coming in VUM soon. We use Dell Plugins for vCenter so that we can do firmware upgrades etc from a single interface (vCenter).
The last session I watched was “HCI3691PUS – Customer Panel: Hyper-converged IT Enabling Agility and Innovation“, which appeared to be a session sponsored by Hitachi with ConAgra Brands and Norwegian Cruise Line as two reference customers. Matt Bouges works for ConAgra Brands as an Enterprise Architect, Brian Barretto works for Norwegian Cruise Line as a Virtualization Manager.
First Matt discussed why ConAgra moved towards HCI, which is all about scaling and availability as well as business restructuring. They needed a platform that could scale with their business needs. For Brian / Norwegian Cruise Line‘s it was all about cost. The current SAN/Storage architecture was very expensive, and as at the time, a new scalable solution (HCI) emerged they explored that and found that the cost model was in their favor. As they run the data centers on the ships as well they need something that is agile, note that these ships are huge, basically floating cities, with redundant data centers onboard of some of these ships. (Note they have close to 30 ships, so a lot of data centers to manage.) Simplicity and also rack space was a huge deciding factor for both ConAgra and Norwegian Cruise Lines.
 Norwegian Cruise Line mentioned that they also still use traditional storage, same for ConAgra. It is great that you can do this with vSAN, keep your “old investment”, while building out the new solution. Over time most applications will move over though. One thing that they feel is missing with hyper-converged is the ability to run large memory configurations or large storage capacity configurations. (Duncan: Not sure I entirely agree, limits are very close to non-HCI servers, but I can see what they are referring to.) One thing to note as well from an operational aspect is that certain types of failures are completely different, and handled completely different in an HCI world, that is definitely something to get familiar with. Another thing mentioned was the opportunity of HCI in the Edge, nice small form factor should be possible and should allow running 10-15 VMs. It removes the need for “converged infra” in those locations or traditional storage in general in those environments. Especially now that compute/processing and storage requirements go up at the edge due to IoT and data analytics that happens “locally”.
Norwegian Cruise Line mentioned that they also still use traditional storage, same for ConAgra. It is great that you can do this with vSAN, keep your “old investment”, while building out the new solution. Over time most applications will move over though. One thing that they feel is missing with hyper-converged is the ability to run large memory configurations or large storage capacity configurations. (Duncan: Not sure I entirely agree, limits are very close to non-HCI servers, but I can see what they are referring to.) One thing to note as well from an operational aspect is that certain types of failures are completely different, and handled completely different in an HCI world, that is definitely something to get familiar with. Another thing mentioned was the opportunity of HCI in the Edge, nice small form factor should be possible and should allow running 10-15 VMs. It removes the need for “converged infra” in those locations or traditional storage in general in those environments. Especially now that compute/processing and storage requirements go up at the edge due to IoT and data analytics that happens “locally”.
That was it for now, hope you find this useful!