In vSphere 7.0 U2 a new feature popped up for Lifecycle Manager. This new feature basically provides the ability to specify what should happen to your workloads when you are applying updates or upgrades to your infrastructure. The new feature is only available for those environments which can use Quick Boot. Quick Boot basically is a different method of restarting a host. It basically skips the BIOS part, which makes a big difference in overall time to complete a reboot.
When you have LCM configured, you can enable Quick Boot by editing the “Remediation Settings”. You then simply tick the “Quick Boot” tickbox, which then provides you a few other options:
- Do not change power state (aka vMotion the VMs)
- Suspend to disk
- Suspend to memory
- Power off
I think all of these speak for themselves, and Suspend to Memory is the new feature that was introduced in 7.0 U2. When you select this option, when you do maintenance via LCM, the VMs which are running on the host which need to be rebooted, will be suspended to memory before the reboot. Of course, they will be resumed when the hypervisor returns for duty again. This should shorten the amount of time the reboot takes, while also avoiding the cost of migrating VMs. Having said that, I do believe that the majority of customers will want to migrate the VMs. When would you use this? Well, if you can afford a small VM/App downtime and have large mem configurations for hosts as well as workloads. As the migration of large memory VMs, especially when they are very memory active, could take a significant amount of time.

I hope that helps, if you want to know where to find the config option in the UI, or if you would like to see it demonstrated, simply watch the video below!
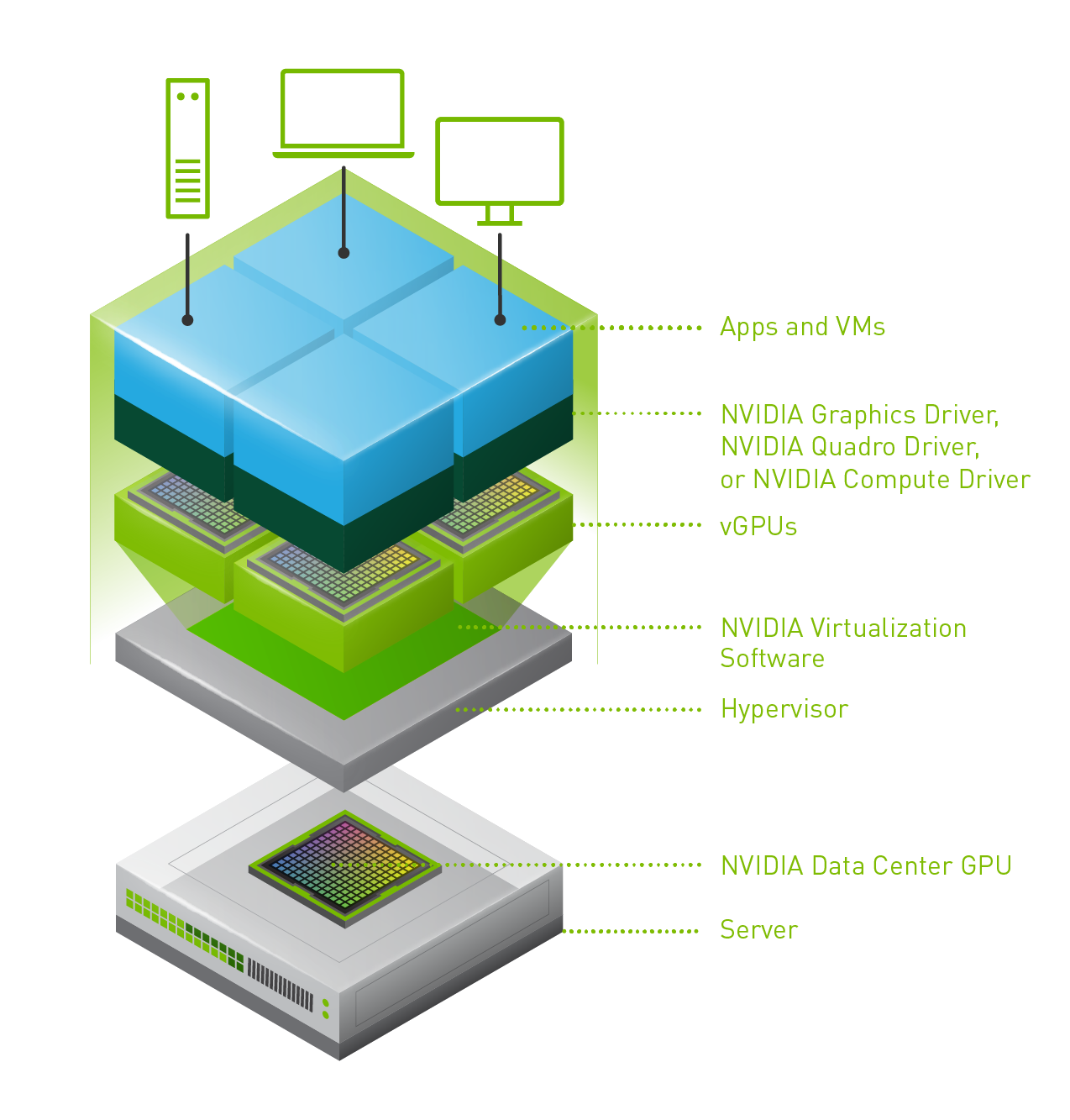 Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in
Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in 