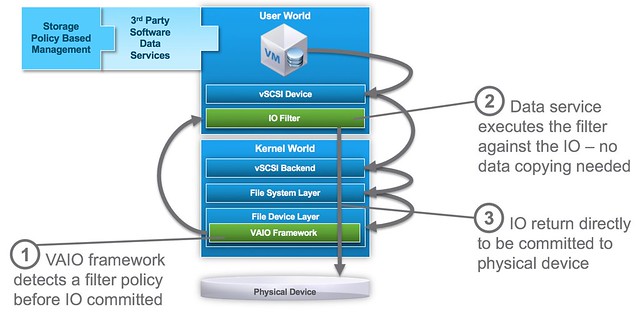
I have discussed this topic a couple of times, and want to inform people about a recent change in recommendation. In the past when deploying a stretched cluster (vMSC) it was recommended by most storage vendors and by VMware to set Disk.AutoremoveOnPDL to 0. This basically disabled the feature that automatically removes LUNs which are in a PDL (permanent device loss) state. Upon return of the device a rescan would then allow you to use the device again. With vSphere 6.0 however there has been a change to how vSphere responds to a PDL scenario, vSphere does not expect the device to return. To be clear, the PDL behaviour in vSphere was designed around the removal of devices, they should not stay in the PDL state and return for duty, this did work however in previous version due to a bug.
With vSphere 6.0 and higher VMware recommends to set Disk.AutoremoveOnPDL to 1, which is the default setting. If you are a vMSC / stretched cluster customer, please change your environment and design accordingly. But before you do, please consult your storage vendor and discuss the change. I would also like to recommend testing the change and behaviour to validate that the environment returns for duty correctly after a PDL! Sorry about the confusion.
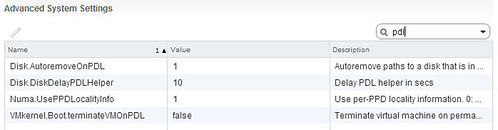
KB article backing my recommendation was just posted: https://kb.vmware.com/kb/2059622. Documentation (vMSC whitepaper) is also being updated.