**disclaimer: this article is an out-take of our book: vSphere 5 Clustering Technical Deepdive**
There’s a cool and exciting new feature as part of Storage vMotion in vSphere 5.0. This new feature is called Mirror Mode and it enables faster and highly efficient Storage vMotion processes. But what is it exactly, and what does it replace?
Prior to vSphere 5.0 we used a mechanism called Change Block Tracking (CBT), to ensure that blocks which were already copied to the destination were marked as changed and copied during the iteration. Although CBT was efficient compared to legacy mechanisms (snapshots), the Storage vMotion engineers came up with an even more elegant and efficient solution which is called Mirror Mode. Mirror Mode does exactly what you would expect it to do; it mirrors the I/O. In other words, when a virtual machine that is being Storage vMotioned writes to disk, the write will be committed to both the source and the destination disk. The write will only be acknowledged to the virtual machine when both the source and the destination have acknowledged the write. Because of this, it is unnecessary to do re-iterative copies and the Storage vMotion process will complete faster than ever before.
The questions remain: How does this work? Where does Mirror Mode reside? Is this something that happens inside or outside of the guest? A diagram will make this more obvious.
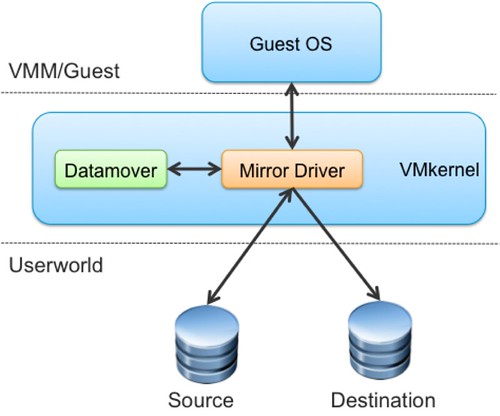
By leveraging DISKLIB, the Mirror Driver can be enabled for the virtual machine that needs to be Storage vMotioned. Before this driver can be enabled, the virtual machine will need to be stunned and of course unstunned after it has been enabled. The new driver leverages the datamover to do a single-pass block copy of the source disk to the destination disk. Additionally, the Mirror Driver will mirror writes between the two disks. Not only has efficiency increased but also migration time predictability, making it easier to plan migrations. I’ve seen data where the “down time” associated with the final copy pass was virtually eliminated (from 13seconds down to 0.22 seconds) in the case of rapid changing disks, but also the migrations time went from 2900 seconds back to 1900 seconds. Check this great paper by Ali Mashtizadeh for more details.
The Storage vMotion process is fairly straight forward and not as complex as one might expect.
- The virtual machine working directory is copied by VPXA to the destination datastore.
- A “shadow” virtual machine is started on the destination datastore using the copied files. The “shadow” virtual machine idles, waiting for the copying of the virtual machine disk file(s) to complete.
- Storage vMotion enables the Storage vMotion Mirror driver to mirror writes of already copied blocks to the destination.
- In a single pass, a copy of the virtual machine disk file(s) is completed to the target datastore while mirroring I/O.
- Storage vMotion invokes a Fast Suspend and Resume of the virtual machine (similar to vMotion) to transfer the running virtual machine over to the idling shadow virtual machine.
- After the Fast Suspend and Resume completes, the old home directory and VM disk files are deleted from the source datastore.
- It should be noted that the shadow virtual machine is only created in the case that the virtual machine home directory is moved. If and when it is a “disks-only Storage vMotion, the virtual machine will simply be stunned and unstunned.
Of course I tested it as I wanted to make sure mirror mode was actually enabled when doing a Storage vMotion. I opened up the VMs log files and this is what I dug up:
2011-06-03T07:10:13.934Z| vcpu-0| DISKLIB-LIB : Opening mirror node /vmfs/devices/svm/ad746a-1100be4-svmmirror
2011-06-03T07:10:47.986Z| vcpu-0| HBACommon: First write on scsi0:0.fileName='/vmfs/volumes/4d884a16-0382fb1e-c6c0-0025b500020d/VM_01/VM_01.vmdk'
2011-06-03T07:10:47.986Z| vcpu-0| DISKLIB-DDB : "longContentID" = "68f263d7f6fddfebc2a13fb60560e8e7" (was "dcbd5c17ac7e86a46681af33ef8049e5")
2011-06-03T07:10:48.060Z| vcpu-0| DISKLIB-CHAIN : DiskChainUpdateContentID: old=0xef8049e5, new=0x560e8e7 (68f263d7f6fddfebc2a13fb60560e8e7)
2011-06-03T07:11:29.773Z| Worker#0| Disk copy done for scsi1:0.
2011-06-03T07:15:16.218Z| Worker#0| Disk copy done for scsi0:0.
2011-06-03T07:15:16.218Z| Worker#0| SVMotionMirroredMode: Disk copy phase completed
Is that cool or what? One can only imagine what kind of new features can be introduced in the future using this new mirror mode driver. (FT enabled VMs across multiple physical datacenters and storage arrays anyone? Just guessing by the way…)