![]() Before I get started, I have not been briefed by Datrium so I am also still learning as I type this and it is purely based on the somewhat limited info on their website. Datrium’s name has been in the press a couple of times as it was the company that was often associated with Diane Greene. The rumours back then were that Diane Greene was the founder and was going to take on EMC, that was just a rumour as Diane Greene is actually an investor in Datrium. Not just her of course, Datrium is also backed by NEA (Venture Capitalist) and various other well known people like Ed Bugnion, Mendel Rosenblum, Frank Slootman and Kai Li. Yes, a big buy in from some of the original VMware founders. Knowing that two of the Datrium founders (Boris Weissman and Ganesh Venkitachalam) are former VMware Principal Engineers (and old-timers) that makes sense. (Source) This morning a tweet was send out, and it seems today they are officially out of stealth.
Before I get started, I have not been briefed by Datrium so I am also still learning as I type this and it is purely based on the somewhat limited info on their website. Datrium’s name has been in the press a couple of times as it was the company that was often associated with Diane Greene. The rumours back then were that Diane Greene was the founder and was going to take on EMC, that was just a rumour as Diane Greene is actually an investor in Datrium. Not just her of course, Datrium is also backed by NEA (Venture Capitalist) and various other well known people like Ed Bugnion, Mendel Rosenblum, Frank Slootman and Kai Li. Yes, a big buy in from some of the original VMware founders. Knowing that two of the Datrium founders (Boris Weissman and Ganesh Venkitachalam) are former VMware Principal Engineers (and old-timers) that makes sense. (Source) This morning a tweet was send out, and it seems today they are officially out of stealth.
As the sun rises this morning, so does a new dominant #datastorage player #Datrium #stealthmode
— Datrium (@Datrium) July 28, 2015
So what is Datrium about? Well Datrium delives a new type of storage system which they call DVX. Datrium DVX is a hybrid solution comprised of host local data services and a network accessed capacity shelf called “netshelf”. I think this quote from their website says it all what their intention is… Move all functionality to the host and let the “shelf” just take care of storing bits. I included a diagram that I found on their website as it makes it more clear.
On the host, DiESL manages in-use data in massive deduplicated and compressed caches on BYO (bring your own) commodity SSDs locally, so reads don’t need a network hop. Hosts operate locally, not as a pool with other hosts.

It seems that from a host perspective the data services (caching, compression, raid, cloning etc) are implemented through the installation of a VIB. So not VM/Appliance based but rather kernel based. The NetShelf is accessible via 10GbE and Datrium uses a proprietary protocol to connect to it. From a host side (ESXi) they connect locally over NFS, which means they have implemented an NFS Server within the host. The NFS connection is also terminated within the host and they included their own protocol/driver on the host to be able to connect to the NetShelf. It is a bit of an awkward architecture, or better said … at first it is difficult to wrap your head around it. This is the reason I used the word “hybrid” but maybe I should have used unique. Hybrid, not because of the mixture of flash and HDD but rather because it is a hybrid of hyper-converged / host local caching and more traditional storage but done in a truly unique way. What does that look like? Something like this I guess:
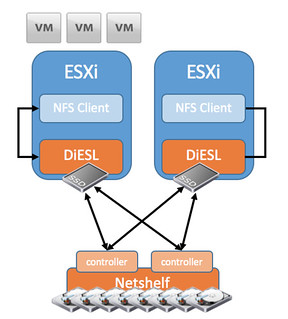
So what does this look like from a storage perspective? Well each NetShelf will come with 29TB of usable capacity. Expected deduplication and compression rate for enterprise companies is between 2-6x which means you will have between 58TB and 175TB to your disposal. In order to ensure your data is high available the NetShelf is a dual controller setup with dual port drives (Which means the drives are connected to both controllers and used in an “active/standby” fashion). Each controller has NVRAM which is used for write caching, and a write will be acknowledge to the VM when it has been written to the NVRAM of both controllers. In other words, if a controller fails there should be no data loss.
Talking about availability, what if a host fails? If I read their website correctly then there is no write caching from a host point of view as it is states that each host operates independently from a caching point of view (no mirroring of writes to other hosts). This also means that all the data services need to be inline –> dedupe / compress / raid. When those actions complete the result will be stored on the NetShelf and then it is accessible by other hosts when needed. It makes me wonder what happens when DRS is enabled and a VM is migrated from one host to another. Will the read cache migrate with it to the other host? And what about very write intensive workloads, how will those perform when all data services are inline? What kind of overhead can/will it have on the host? How will it scale out? What if I need more than 1 Netshelf? Those are some of the questions that popup immediately. Considering the brain-power within Datrium I am assuming they have a simple answer to those questions… (Former VMware, Data Domain, NetApp, EMC etc) I will try to ask them these questions at VMworld or during a briefing and write a follow up.
From an operational aspect it is an interesting solution as it should lower the effort involved with managing storage almost to zero. There is the NFS connection and you have your VMs and VMDKS at the front end, at the back-end you have a blackbox or better said a shelf dedicated to storing bits. This should be dead easy to manage and deploy. It shouldn’t require a dedicated storage administrator but the VMware admin should be able to manage it. Some of you may ask, well what if I want to connect anything other than a VMware host to it? For now Datrium appears to be mainly targeting VMware environments (which makes sense considering their dna) but I guess they could implement this for various platforms in a similar fashion.
Again, I was not briefed by Datrium and I accidentally saw their tweet this morning but their solution is so intriguing I figured I would share it anyway. Hope it was useful.
Interested? More info here:
- Datasheet – http://www.datrium.com/datasheet/DVX_DataSheet.pdf
- Host side implementation info – http://www.datrium.com/dvx-overview/diesl-software/
- DVX Netshelf – http://www.datrium.com/dvx-overview/datrium-netshelf/
- Twitter: http://www.twitter.com/datriumstorage
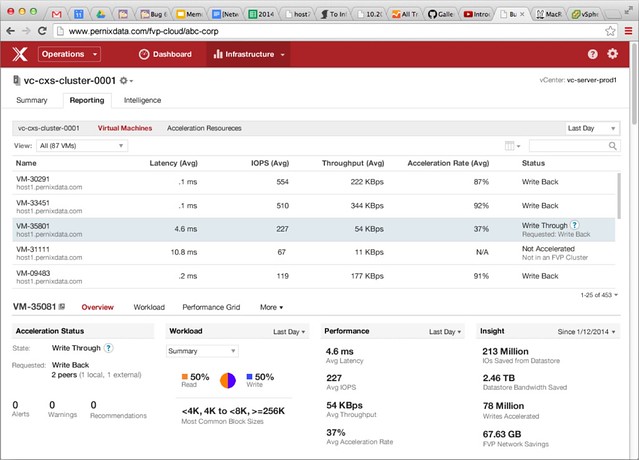
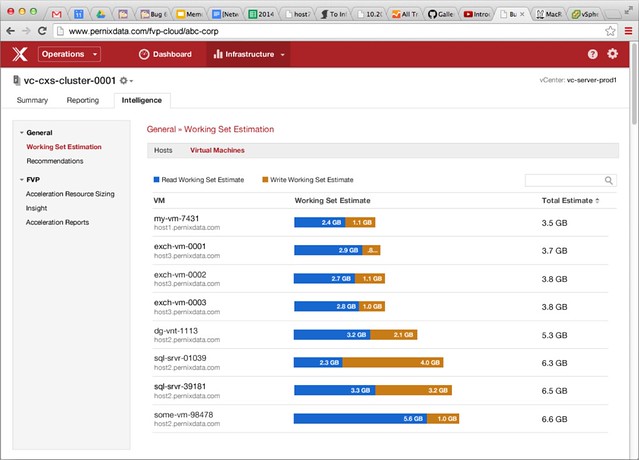
 Two months ago I published an
Two months ago I published an