When ever I talk to customers about Virtual SAN the question that comes up usually is why Virtual SAN? Some of you may expect it to be performance, or the scale-out aspect, or the resiliency… None of that is the biggest differentiator in my opinion, management truly is. Or should I say the fact that you can literally forget about it after you have configured it? Yes, of course that is something you expect every vendor to say about their own product. I think the reply of one of the users during the VSAN Chat that was held last week is the biggest testimony I can provide: “VSAN made storage management a non-issue for the first time for the vSphere cluster admin”. (see tweet below)
@vmwarevsan VSAN made storage management a non-issue for this first time vSphere cluster admin! #vsanchat http://t.co/5arKbzCdjz
— Aaron Kay (@num1k) September 22, 2015
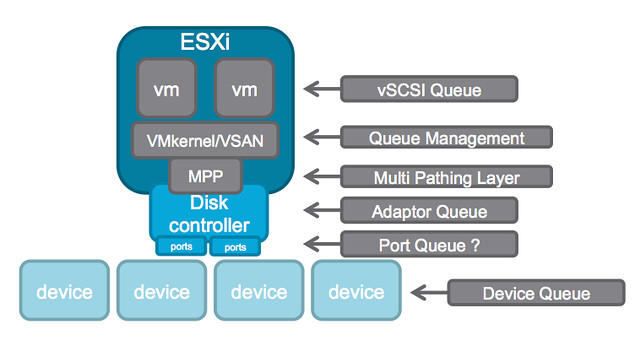
When we released the first version of Virtual SAN I strongly believed we had a winner on our hands. It was so simple to configure, you don’t need to be a VCP to enable VSAN, it is two clicks. Of course VSAN is a bit more than just that tick box on a cluster level that says “enable”. You want to make sure it performs well, all drivers/firmware combinations are certified, the network is correctly configured etc. Fortunately we also have a solution for that, this isn’t a manual process.
No, you simply go to the VSAN healthcheck section on your VSAN cluster object and validate everything is green. Besides simply looking at those green checks, you can also run certain pro-active tests that will allow you to test for instance multicast performance, VM creation, VSAN performance etc. It all comes as part of vCenter Server as of the 6.0 U1 release. On top of that there is more planned. At VMworld we already hinted at it, advanced performance management inside vCenter based on a distributed and decentralized model. You can expect that at some point in the near future, and of course we have the vROps pack for Virtual SAN if you prefer that!
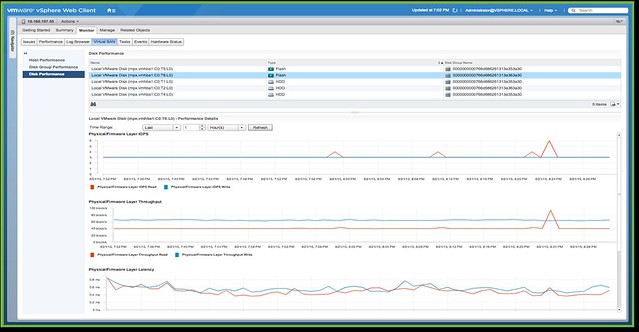
No, if you ask me, the biggest differentiator definitely is management… simplicity is the key theme, and I guarantee that things will only improve with each release.
 Last week on twitter there was a discussion about hyper-converged solutions and how these were not what someone who works in an enterprise environment would buy for their tier 1 workloads. I asked the question: well what about buying Pure Storage, Tintri, Nimble or Solid Fire systems? All non-hyper converged solutions, but relatively new. Answer was straight forward: not buying those either, big risk. Then the classic comment came:
Last week on twitter there was a discussion about hyper-converged solutions and how these were not what someone who works in an enterprise environment would buy for their tier 1 workloads. I asked the question: well what about buying Pure Storage, Tintri, Nimble or Solid Fire systems? All non-hyper converged solutions, but relatively new. Answer was straight forward: not buying those either, big risk. Then the classic comment came: I’ve been thinking about the term Software Defined Data Center for a while now. It is a great term “software defined” but it seems that many agree that things have been defined by software for a long time now. When talking about SDDC with customers it is typically referred to as the ability to abstract, pool and automate all aspects of an infrastructure. To me these are very important factors, but not the most important, well at least not for me as they don’t necessarily speak to the agility and flexibility a solution like this should bring. But what is an even more important aspect?
I’ve been thinking about the term Software Defined Data Center for a while now. It is a great term “software defined” but it seems that many agree that things have been defined by software for a long time now. When talking about SDDC with customers it is typically referred to as the ability to abstract, pool and automate all aspects of an infrastructure. To me these are very important factors, but not the most important, well at least not for me as they don’t necessarily speak to the agility and flexibility a solution like this should bring. But what is an even more important aspect? With Virtual Volumes placement of a VM (or VMDK) is based on how the policy is constructed and what is defined in it. The Storage Policy Based Management engine gives you the flexibility to define policies anyway you like, of course it is limited to what your storage system is capable of delivering but from the vSphere platform point of view you can do what you like and make many different variations. If you specify that the object needs to thin provisioned, or has a specific IO profile, or needs to be deduplicated or… then those requirements are passed down to the storage system and the system makes its placement decisions based on that and will ensure that the demands can be met. Of course as stated earlier also requirements like QoS and availability are passed down. This could be things like latency, IOPS and how many copies of an object are needed (number of 9s resiliency). On top of that, when requirements change or when for whatever reason SLA is breached then in a requirements driven environment the infrastructure will assess and remediate to ensure requirements are met.
With Virtual Volumes placement of a VM (or VMDK) is based on how the policy is constructed and what is defined in it. The Storage Policy Based Management engine gives you the flexibility to define policies anyway you like, of course it is limited to what your storage system is capable of delivering but from the vSphere platform point of view you can do what you like and make many different variations. If you specify that the object needs to thin provisioned, or has a specific IO profile, or needs to be deduplicated or… then those requirements are passed down to the storage system and the system makes its placement decisions based on that and will ensure that the demands can be met. Of course as stated earlier also requirements like QoS and availability are passed down. This could be things like latency, IOPS and how many copies of an object are needed (number of 9s resiliency). On top of that, when requirements change or when for whatever reason SLA is breached then in a requirements driven environment the infrastructure will assess and remediate to ensure requirements are met. When I look at discussions being held around whether server side caching solutions is preferred over an all-flash arrays, which is just another form factor discussion if you ask me, the only right answer that comes to mind is “it depends”. It depends on what your business requirements are, what your budget is, if there are any constraints from an environmental perspective, hardware life cycle, what your staff’s expertise / knowledge is etc etc. It is impossible to to provide a single answer and solution to all the problems out there. What I realized is that what the software-defined movement actually brought us is choice, and in many of these cases the form factor is just a tiny aspect of the total story. It seems to be important though for many people, maybe still an inheritance from the “server hugger” days where hardware was still king? Those times are long gone though if you ask me.
When I look at discussions being held around whether server side caching solutions is preferred over an all-flash arrays, which is just another form factor discussion if you ask me, the only right answer that comes to mind is “it depends”. It depends on what your business requirements are, what your budget is, if there are any constraints from an environmental perspective, hardware life cycle, what your staff’s expertise / knowledge is etc etc. It is impossible to to provide a single answer and solution to all the problems out there. What I realized is that what the software-defined movement actually brought us is choice, and in many of these cases the form factor is just a tiny aspect of the total story. It seems to be important though for many people, maybe still an inheritance from the “server hugger” days where hardware was still king? Those times are long gone though if you ask me.