I was reading an article by one of my Tech Marketing colleagues, Kyle Gleed and coincidentally Gabe published an article about the same topic to which Frank replied and just now Forbes Guthrie… the topic being Large Pages. I have written about this topic many times in the past and both Kyle, Gabe, Forbes and Frank mentioned the possible impact of large pages so I won’t go into detail.
There appears to be a lot of concerns around the benefits and the possible downside of leaving it enabled in terms of monitoring memory usage. There are a couple of things I want to discuss as I have the feeling that not everyone fully understands the concept.
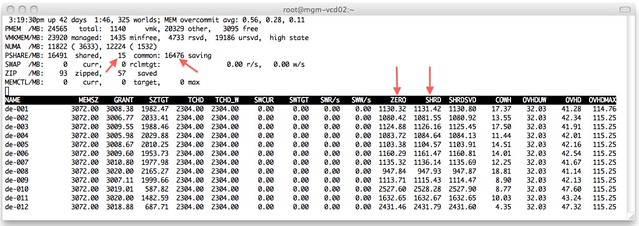
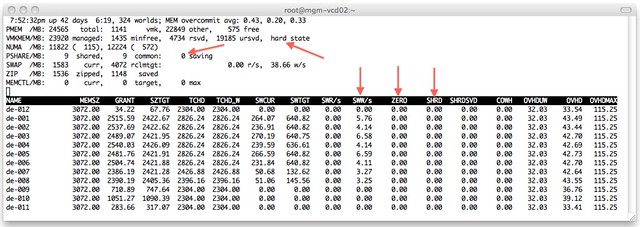
First of all what are the Large/Small Pages? Small Pages are regular 4k memory pages and Large Pages are 2m pages. I guess the difference is pretty obvious. Now as Frank explained when using Large Pages there is a difference in TLB(translation lookaside buffer) entries; basically a VM provisioned with 2GB would need would need a 1000 TLB entries with Large Pages and 512.000 with Small Pages. Now you might wonder what this has got to do with your VM, well that’s easy… If you have an CPU that has EPT(Intel) or RVI(AMD) capabilities the VMkernel will try to back ALL pages with Large Pages.
Please read that last sentence again and spot what I tried to emphasize. All pages. So in other words where Gabe was talking about “does your Application really benefit from” I would like to state that that is irrelevant. We are not merely talking about just your application, but about your VM as a whole. By backing all pages by Large Pages the chances of TLB misses are decreased, and for those who never looked into what the TLB does I would suggest reading this excellent wikipedia page. Let me give you the conclusion though, TLB misses will increase latency from a memory perspective.
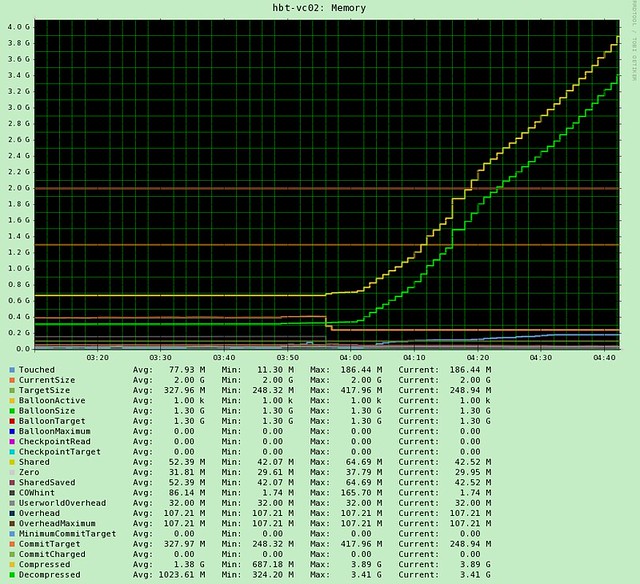
That’s not just it, the other thing I wanted to share is the “impact” of breaking up the large pages into small pages when there is memory pressure. As Frank so elegantly stated “the VMkernel will resort to share-before-swap and compress-before-swap”. There is no nicer way of expressing uber-sweetness I guess. Now one thing that Frank did not mention though is that if the VMkernel detects memory pressure has been relieved it will start defragmenting small pages and form large pages again so that the workload can benefit again from the performance increase that these bring.
Now the question remains what kind of performance benefits can we expect as some appear to be under the impression that when the application doesn’t use large pages there is no benefit. I have personally conducted several tests with a XenApp workload and measured a 15% performance increase and on top of that less peaks and lower response times. Now this isn’t a guarantee that you will see the same behavior or results, but I can assure it is beneficial for your workload regardless of what types of pages are used. Small on Large or Large on Large, all will benefit and so will you…
I guess the conclusion is, don’t worry too much as vSphere will sort it out for you!