This was one fun episode. I just love talking to people about things that are relatively new to me, and AI/ML definitely is a relatively new topic for me. Justin Murray is VMware’s Tech Marketing guru on this topic and he had some great knowledge to share with us. On top of that, Justin just has a great way of simplifying/explaining things and always is a pleasure to see present/listen to. Either listen via the embedded player below or listen via Spotify: spoti.fi/3vtxjA6, Apple: apple.co/3ErCdSC, or anywhere else you get your podcasts!
gpu
Unexplored Territory #005: AI Enterprise, DPUs, and NVIDIA Launchpad with Luke Wignall
Episode 005 is out! This time we talk to Luke Wignall, who is the Director of Technical Product Marketing at NVIDIA. We talk about some of the announcements made during the NVIDIA GTC Conference. Luke discusses NVIDIA Launchpad, AI Enterprise, and of course, we touch on DPUs aka SmartNICs. A great conversation with A LOT of information to digest. Enjoy the episode, and if you haven’t done so yet, make sure to subscribe! You can also listen via your podcast apps of course for Apple: https://apple.co/3lYZGCF, Google: https://bit.ly/3oQVarH, Spotify: https://spoti.fi/3INgN3R.
vGPUs and vMotion, why the long stun times?
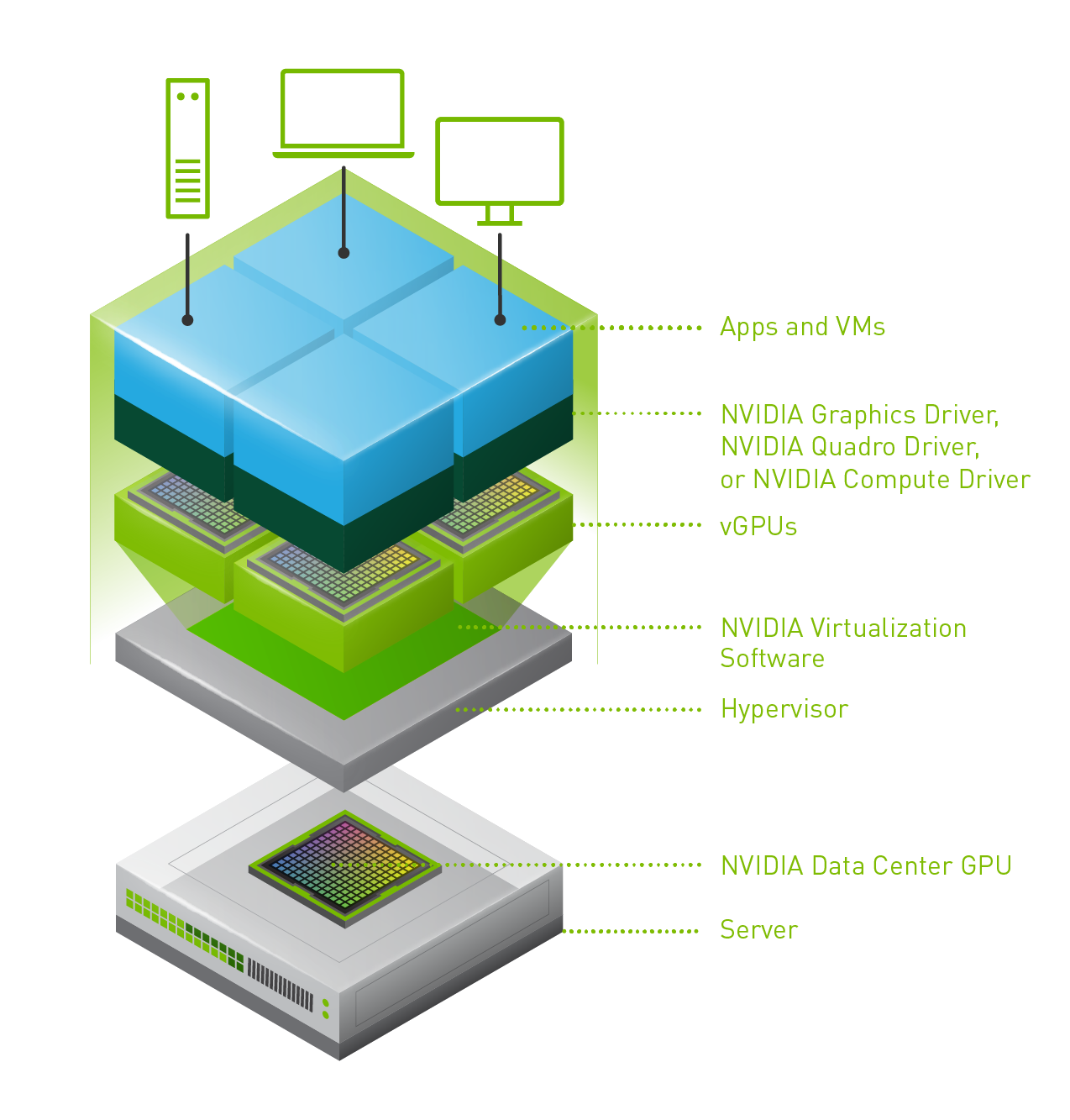 Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in his blog how to set this via Powershell or the UI. Now when you read the documentation there’s one thing that stands out, and that is the relatively high stun times for vGPU enabled VMs. Just as an example, here are a few potential stun times with various sized vGPU frame buffers:
Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in his blog how to set this via Powershell or the UI. Now when you read the documentation there’s one thing that stands out, and that is the relatively high stun times for vGPU enabled VMs. Just as an example, here are a few potential stun times with various sized vGPU frame buffers:
- 2GB – 16.5 seconds
- 8GB – 61.3 seconds
- 16GB – 100+ seconds (time out!)
This is all documented here for the various frame buffer sizes. Now there are a couple of things to know about this. First of all, the time mentioned was tested with 10GbE and the NVIDIA P40. This could be different for an RTX6000 or RTX8000 for instance. Secondly, they used a 10GbE NIC. If you use multi-NIC vMotion or for instance a 25GbE NIC than results may be different (times should be lower). But more importantly, the times mentioned assume the full frame buffer memory is consumed. If you have a 16GB frame buffer and only 2GB is consumed then, of course, the stun time would be lower than the above mentioned 100+ seconds.
Now, this doesn’t answer the question yet, why? Why on earth are these stun times this long? The vMotion process is described in this blog post by Niels in-depth, so I am not going to repeat it. It is also described in our Clustering Deep Dive book which you can download here for free. The key reason why with vMotion the “down time” (stun times) can be kept low is that vMotion uses a pre-copy process and tracks which memory pages are changed. In other words, when vMotion is initiated we copy memory pages to the destination host, and if a page has changed during that copy process we mark it as changed and copy it again. vMotion does this until the amount of memory that needs to be copied is extremely low and this would result in a seamless migration. Now here is the problem, it does this for VM memory. This isn’t possible for vGPUs unfortunately today.
Okay, so what does that mean? Well if you have a 16GB frame buffer and it is 100% consumed, the vMotion process will need to copy 16GB of frame buffer memory from the source to the destination host when the VM is stunned. Why when the VM is stunned? Well simply because that is the point in time where the frame buffer memory will not change! Hence the reason this could take a significant number of seconds unfortunately today. Definitely something to consider when planning on using vMotion on (multi) vGPU enabled VMs!
Installing the NVIDIA software on an ESXi host and configuring for vGPU usage
I have been busy in the lab with testing our VR workload within a VM and then streaming the output to a head-mounted display. Last week I received a nice new shiny NVIDIA RTX6000 to use in my Dell Precision workstation. I received a passively cooled RTX8000 at first, by mistake that is. And the workstation wouldn’t boot as it doesn’t support that card, great in hindsight as would have probably been overheated fast considering the lack of airflow in my home office. After adding the RTX6000 to my machine it booted and I had to install the NVIDIA vib on ESXi. I also had to configure the host accordingly. I did it through the command-line as that was the fastest for me. I started with copying the vib file to /tmp/ on the ESXi host using scp and then did the following:
esxcli system maintenanceMode set –e true esxcli software vib install –v /tmp/NVIDIA**.vib esxcli system maintenanceMode set –e false reboot
The above places the host in maintenance mode, installs the vib, removes the host from maintenance mode and then reboots it. The other thing I had to do, as I am planning on using vGPU technology, is to set the host by default to “Shared Direct – Vendor shared passthrough graphics”. You can also do this through the command-line as follows:
esxcli graphics host set --default-type SharedPassthru
You can also set the assigned policy:
esxcli graphics host set --shared-passthru-assignment-policy <Performance | Consolidation>
I configured it set to “performance” as for my workload this is crucial, it may be different for your workload though. In other to ensure these changes are reflected in the UI you will either need to reboot the host, or you can restart Xorg the following way:
/etc/init.d/xorg stop nv-hostengine -t nv-hostengine -d /etc/init.d/xorg start
That is what it took. I realized after the first reboot I could have configured the host graphics configuration and changed the default policy for the passthrough assignment first probably and then reboot the host. That would also avoid the need to restart Xorg as it would be restarted with the host.
If there’s a need for it, you can also change the NVIDIA vGPU scheduler being used. There are three options available: “Best Effort”, “Equal Share”, and “Fixed Share”. Using esxcli you can configure to use a particular scheduler. I set my host to Equal Share with with the default time slice, which you can do as shown below. Note, this only works for particular GPU models, not for all of them, so read the documentation of your card first before you apply.
esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords=<span class="token assign-left variable">RmPVMRL</span><span class="token operator">=</span>0x01"
And for those who care, you can see within vCenter which VM is associated with which GPU, but you can also check this via the command-line of course:
esxcli graphics vm list
And the following command will list all the devices present in the host:
esxcli graphics device list
On twitter I was just pointed to a script which lists the vGPU vib version across all hosts of your vCenter Server instances. Very useful if you have a larger environment. Thanks Dane for sharing.