This is the session I have been waiting for, I had it very high on my “must see” list together with the session presented by Christian Dickmann earlier today. Not because it happened to be presented by our Storage an Availability CTO Christos Karamanolis (@XtosK on twitter), but because of the insights I expect to be provided in this session. The title I think says it all: An Industry Roadmap: From storage to data management.
** Keep that in mind when reading the rest of article. Also, this session literally just finished a second ago, I wanted to publish it asap so if there are any typos, my apologies. **
Christos starts with explaining the current problem. There is a huge information growth, 2x growth every 2 years. And that is on the conservative side. Where does the data go? According to analyst it is not expected that this will go to traditional storage, actually the growth of traditional storage is slowing down, actually there is a negative growth seen. Two new types of storage have emerged and are growing fast, Hyper-scale Server SAN Storage and Enterprise Server SAN Storage aka Hyper-converged systems.

With new types of applications changing the world of IT, data management is more important than ever before. Todays storage product do not meet the requirements of this rapidly changing IT world and does not provide the agility your business owners demand. Many of the infrastructure problems can be solved by Hyper-Converged Software, this is all enabled by the hardware evolution we’ve witness over the last years: flash, RDMA, NVMe, 10Gbe etc. These changes from a hardware point of view allowed us to simplify storage architectures and deliver it as software. But it is not just about storage, it is also about operational simplicity. How do we enable our customers to manage more applications and VMs with less. Storage Policy Based Management has enabled this for both Virtual SAN (hyper-converged) and Virtual Volumes in more traditional environments.
Data Lifecycle Management however is still challenging. Snapshots, Clones, Replication, Dedupe, Checksums, Encryption. How do I enable these on a per VM level? How do we decouple all of these data services from the underlying infrastructure? VMware has been doing that for years, best example is vSphere Replication where VMs and Virtual Disks can be replicated on a case by case basis between different types of storage systems. It is even possible to leverage an orchestration solution like Site Recovery Manager to manage your DR strategy end to end from a single interface from private cloud to private cloud, but also from private to public. And from private to public is enabled by vCloud Availability suite, and here you can pay as you g(r)o(w). All of this again driven by policy and through the interface you use on a daily basis, the vSphere Web Client.
How can we improve the world of DR? Just imagine there was a portable snapshot. A snapshot that was decoupled from storage, can be moved between environments, can be stored in public or private clouds and maybe even both at the same time. This is something we as VMware are working on. A portable snapshot that can be used for Data Protection purposes. Local copies, archived copies in remote datacenters with a different SLA/retention.
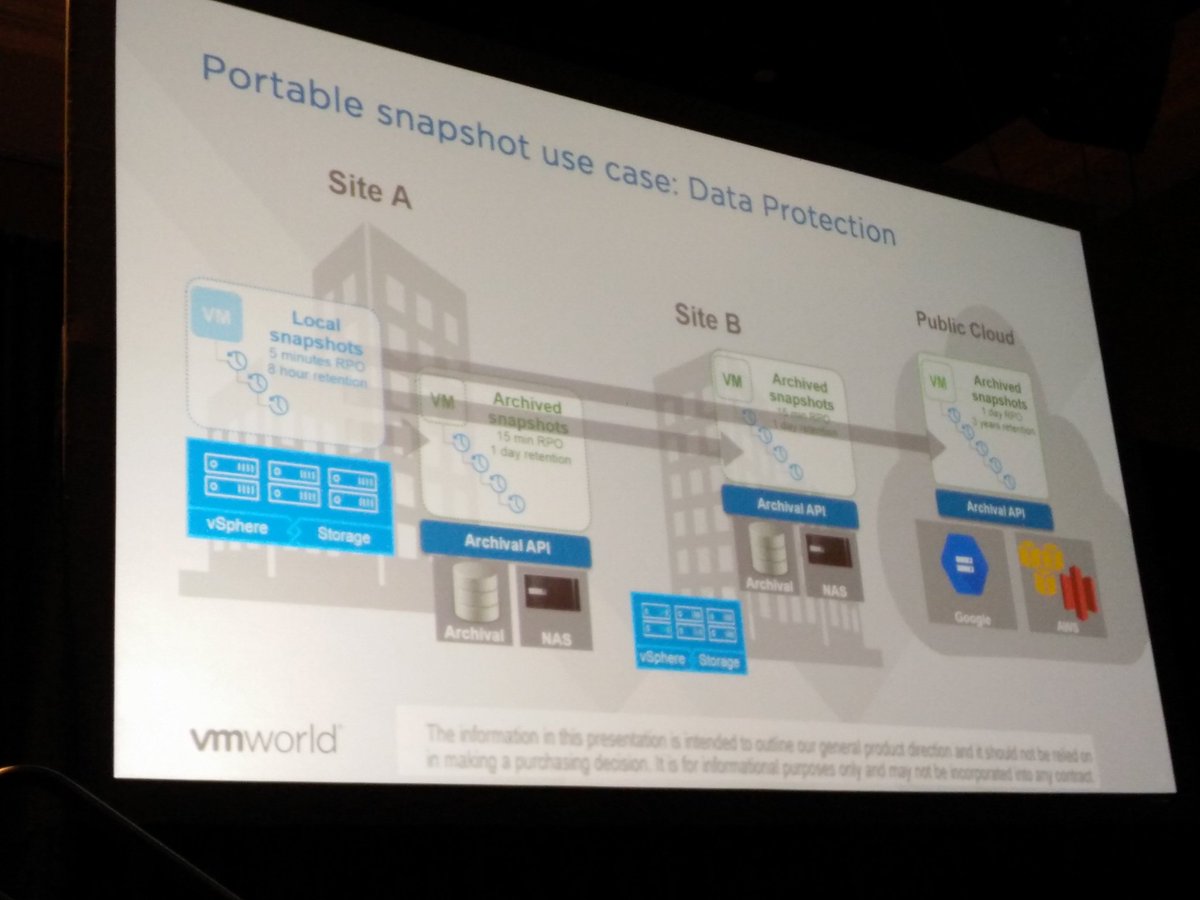
How does this scale however when you have 10000s of VMs? Especially when there are 10s of snapshots per VM, or even hundreds. This should all be driven by policy. If I can move the data to different locations, can I use this data as well for other purposes? How about leveraging this for test&dev or analytics? Portable snapshots providing application mobility.
Christos next demoed what the above may look like in the future, the demo shows a VM being replicated from vSphere to AWS, but vSphere to vSphere or vSphere to Azure were also available as an option. The normal settings are configured (destination datastore and network) and literally within seconds the replication starts. The UI looks very crisp and seems to be similar to what was shown in the keynote on day 1 (Cross Cloud Services). But how does this work in the new world of IT, what if I have many new gen applications, containers / microservices?
A Distributed File System for Cloud Native apps is now introduced. It appears to be a solution which sits on top of Virtual SAN and provides a file system that can scale to 1000s of hosts with functionality like highly scalable and performing snapshots and clones. These snapshots provided by this Distributed File System are also portable, this concept being developed is called exoclones. It is not something that is just living in the heads of the engineering team, Christos actually showed a demo of an exoclone being exported and imported to another environment.
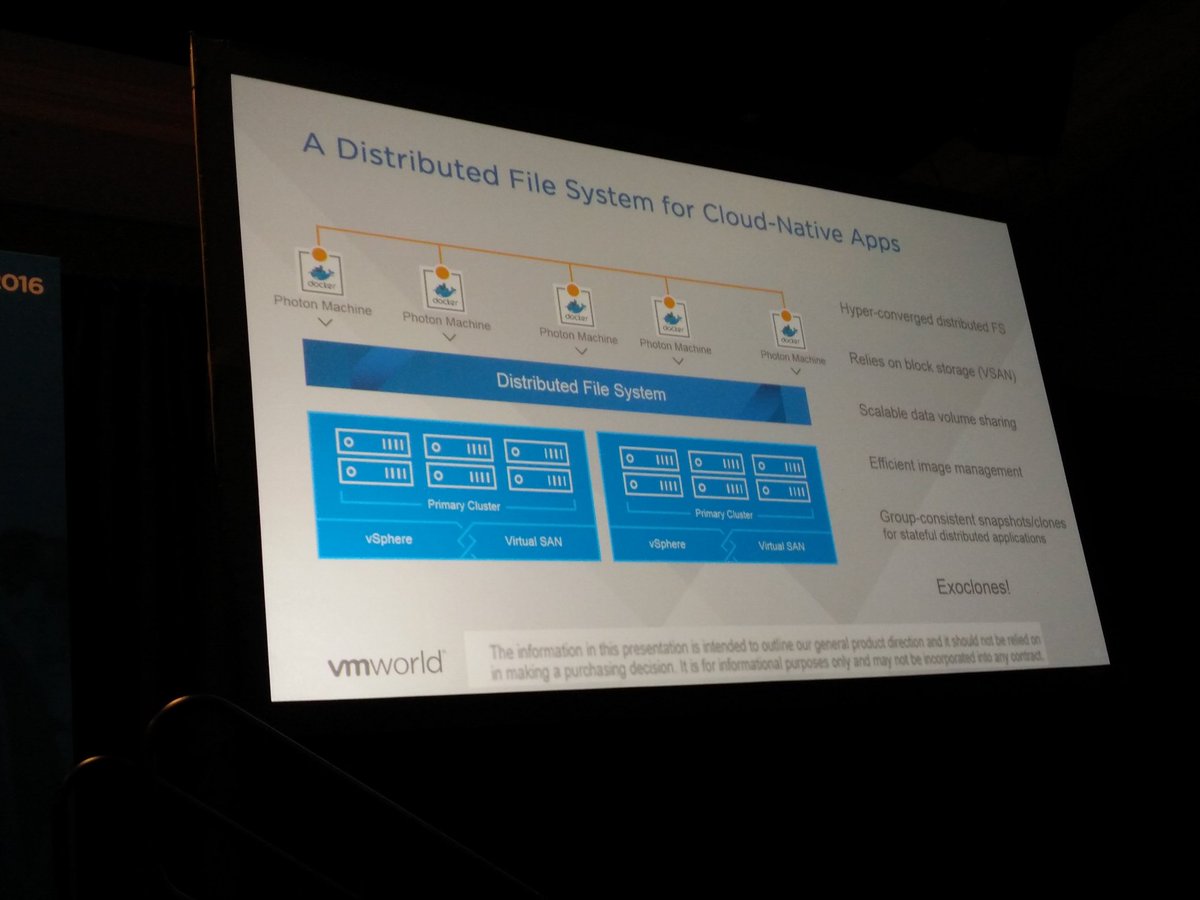
If VMware does provide that level of data portability, how do you track and control all that data? Data governance is key in most environments, how do we enforce compliance, integrity and availability. This will be the next big challenge for the industry. There are some products which can provide this today, but nothing that can do this cross-cloud and for both current and new application architectures and infrastructures.
Although for years we seem to have been under the impression that the infrastructure was the center of the universe. Reality is that it serves a clear purpose: host applications and provide users access to data. Your companies data is what is most important. We as VMware realize that and are working to ensure we can help you move forward on your next big journey. In short, it is our goal that you can focus on data management and no longer need to focus on the infrastructure.
Great talk,