I receive a lot of hits on an old article regarding aligning your VMDKs. This article doesn’t actually explain why it is important but only how to do it. The how is not actually as important in my opinion. I do however want to take the opportunity to list some of the options you have today to align your VMs VMDKs. Keep in mind that some require a license(*) or login for that matter:
- UberAlign by Nick Weaver
- mbralign by NetApp(*)
- vOptimizer by Vizioncore(*)
- GParted (Free tool, Thanks Ricky El-Qasem).
First let’s explain why alignment is important. Take a look at the following diagram:
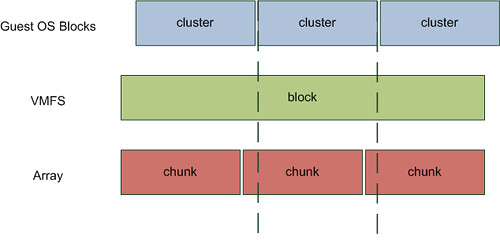
In my opinion there is no need to discuss VMFS alignment. Everyone, and if you don’t you should!, creates their VMFS via vCenter which means it is automatically aligned and you won’t need to worry about it. However you will need to worry about the Guest OS. Take Windows 2003, by default when you install the OS your partition is misaligned. (Both Windows 7 and Windows 2008 create aligned partitions by the way.) Even when you create a new partition it will be misaligned. As you can clearly see in the diagram above every cluster will span multiple chunks. Well actually it depends. I guess that’s the next thing to discuss but first let’s show what an aligned OS partition looks like:
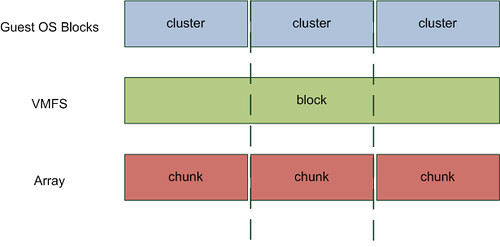
I would recommend everyone to read this document. Although it states at the beginning it is obsolete it still contains relevant details! And I guess the following quote from the vSphere Performance Best Practices whitepaper says it all:
Src
The degree of improvement from alignment is highly dependent on workloads and array types. You might want to refer to the alignment recommendations from your array vendor for further information.
Now you might wonder why some vendors are more effected by misalignment than others. The reason for this is block sizes on the back end. For instance NetApp uses a 4KB block size (correct me if I am wrong). If your filesystem uses a 4KB block size (or cluster size as Microsoft calls it) as well this basically means every single IO will require the array to read or write to two blocks instead of 1 when your VMDK’s are misaligned as the diagrams clearly show.
Now when you take for instance an EMC Clariion it’s a different story. As explained in this article, which might be slightly outdated, Clariion arrays use a 64KB chunk size to write their data which means that not every Guest OS cluster is misaligned and thus EMC Clariion is less effected by misalignment. Now this doesn’t mean EMC is superior to NetApp, I don’t want to get Vaughn and Chad going again ;-), but it does mean that the impact of misalignment is different for every vendor and array/filer. Keep this in mind when migrating and / or creating your design.