There was an internal question that came up, and I figured I would write a quick article as I had to grab some screenshots anyway. If you have vSAN Encryption – Data At Rest enabled, how do you verify the disks are actually encrypted? There are a couple of things you can do, and one is, of course verify in the vSAN UI that encryption is enabled in the configuration section. But you can also verify on a per-host basis if the disks have been encrypted through the command: esxcli vsan storage list. The output would look as follows:

As you can see, Encryption: true.
Of course, it is also beneficial to know if the Key Management System is reachable and healthy, as well as whether the necessary CPU instructions are available. These details can be viewed in vSAN Skyline Health, as shown in the next screenshot.
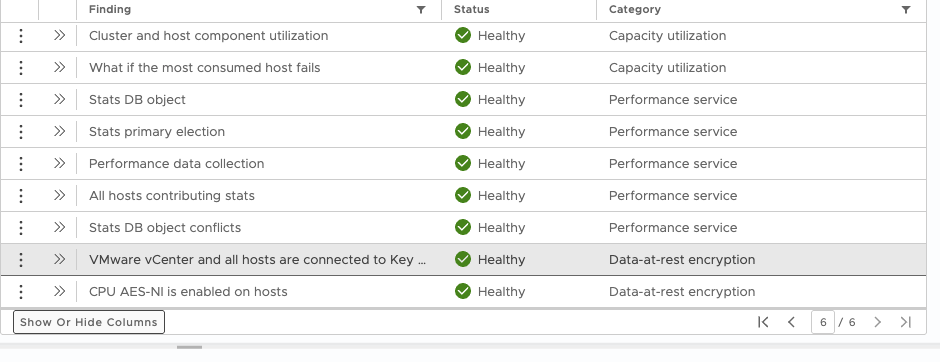
Hope that helps… OH, if you do use the Native Key Server, and encounter an error “not available on host”, verify if you enabled it with “Use key provider only with TPM” ticked or not, as if that is selected and you don’t have a TPM would result in that error.